기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon의 관리형 조정 지표 이해 EMR
Amazon은 클러스터에 관리형 조정이 활성화된 경우 1분 단위로 데이터와 함께 고해상도 지표를 EMR 게시합니다. Amazon EMR 콘솔 또는 Amazon 콘솔을 사용한 관리형 조정으로 제어되는 모든 크기 조정 시작 및 완료에 대한 이벤트를 볼 수 있습니다 CloudWatch . CloudWatch 지표는 Amazon EMR 관리형 조정이 작동하는 데 매우 중요합니다. 데이터가 누락되지 않도록 CloudWatch 지표를 면밀히 모니터링하는 것이 좋습니다. 누락된 지표를 감지하도록 CloudWatch 경보를 구성하는 방법에 대한 자세한 내용은 Amazon CloudWatch 경보 사용을 참조하세요. Amazon에서 CloudWatch 이벤트를 사용하는 방법에 대한 자세한 내용은 이벤트 모니터링을 CloudWatch EMR참조하세요.
다음 지표는 클러스터의 현재 또는 대상 용량을 나타냅니다. 이러한 지표는 관리형 조정이 활성화된 경우에만 사용할 수 있습니다. 인스턴스 플릿으로 구성된 클러스터의 경우, 클러스터 용량 지표는 Units에서 측정됩니다. 인스턴스 그룹으로 구성된 클러스터의 경우, 클러스터 용량 지표는 관리형 조정 정책에 사용된 단위 유형을 기반으로 하는 vCPU에서 또는 Nodes에서 측정됩니다.
| 지표 | 설명 |
|---|---|
|
관리형 조정에 따라 결정되는 클러스터units/nodes/vCPUs의 목표 총 수입니다. Units: Count |
|
실행 중인 클러스터에서 units/nodes/vCPUs 사용 가능한 현재 총 수입니다. 클러스터 크기 조정이 요청되면 새 인스턴스가 클러스터에 추가되거나 클러스터에서 제거된 후 이 지표가 업데이트됩니다. Units: Count |
|
관리형 조정에 따라 결정되는 클러스터COREunits/nodes/vCPUs의 목표 수입니다. Units: Count |
|
클러스터에서 CORE units/nodes/vCPUs 실행 중인 현재 수입니다. Units: Count |
|
관리형 조정에 따라 결정되는 클러스터TASKunits/nodes/vCPUs의 목표 수입니다. Units: Count |
|
클러스터에서 TASK units/nodes/vCPUs 실행 중인 현재 수입니다. Units: Count |
다음 지표는 클러스터 및 애플리케이션의 사용 상태를 나타냅니다. 이러한 지표는 모든 Amazon EMR 기능에 사용할 수 있지만 클러스터에 대해 관리형 조정이 활성화된 경우 1분 단위로 데이터를 사용하여 더 높은 해상도로 게시됩니다. 다음 지표를 이전 표의 클러스터 용량 지표와 상호 연관시켜 관리형 조정 결정을 파악할 수 있습니다.
| 지표 | 설명 |
|---|---|
|
|
완료된에 제출된 애플리케이션 수YARN입니다. 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
|
|
보류 중인 상태로 YARN에 제출된 애플리케이션 수입니다. 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
|
|
실행 YARN 중인에 제출된 애플리케이션 수입니다. 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
ContainerAllocated |
에서 할당한 리소스 컨테이너 수입니다ResourceManager. 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
|
|
대기열에서 아직 할당되지 않은 컨테이너 수 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
ContainerPendingRatio |
보류 중인 컨테이너와 할당된 컨테이너의 비율(ContainerPendingRatio = ContainerPending / ContainerAllocated). If ContainerAllocated = 0, then ContainerPendingRatio = 입니다ContainerPending. 의 값은 백분율이 아닌 숫자를 ContainerPendingRatio 나타냅니다. 이 값은 컨테이너 할당 동작에 따라 클러스터 리소스를 조정하는 데 유용합니다. Units: Count |
|
|
현재 사용되는 HDFS 스토리지의 백분율입니다. 사용 사례: 클러스터 성능 분석 단위: 백분율 |
|
|
클러스터가 더 이상 작업을 실행하지 않지만 여전히 활성 상태로 요금이 발생하고 있다는 것을 나타냅니다. 아무런 작업도 실행되고 있지 않으면 1로 설정되고, 그 외에는 0으로 설정됩니다. 이 값은 5분 주기로 검사하며, 값이 1일 때는 클러스터가 검사 시에만 유휴 상태일 뿐 전체 5분간 유휴 상태라는 것을 의미하지는 않습니다. 오탐지를 방지하기 위해서는 이 값이 5분 주기의 연속 검사 1회를 넘어 1을 유지할 때 경보를 알려야 합니다. 예를 들어 30분 이상 1을 유지하는 경우 이 값에 대한 경보를 제기할 수 있습니다. 사용 사례: 클러스터 성능 모니터링 단위: 부울 |
|
|
할당 가능한 메모리 크기 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
|
|
현재 MapReduce 작업 또는 작업을 실행 중인 노드 수입니다. 지표 YARN와 동일합니다 사용 사례: 클러스터 진행 상황 모니터링 Units: Count |
|
|
( YARN = MemoryAvailableMB/MemoryTotalMB)에YARNMemoryAvailablePercentage 사용할 수 있는 나머지 메모리의 백분율입니다. 이 값은 YARN 메모리 사용량에 따라 클러스터 리소스를 조정하는 데 유용합니다. 단위: 백분율 |
다음 지표는 YARN 컨테이너 및 노드에서 사용하는 리소스에 대한 정보를 제공합니다. YARN 리소스 관리자의 이러한 지표는 클러스터에서 실행되는 컨테이너 및 노드에서 사용하는 리소스에 대한 인사이트를 제공합니다. 이러한 지표를 이전 테이블의 클러스터 용량 지표와 비교하면 관리형 조정의 영향을 보다 명확하게 파악할 수 있습니다.
| 지표 | 연결된 릴리스 | 설명 |
|---|---|---|
|
|
레이블 7.3.0 이상을 릴리스하는 데 사용 가능 |
게시 기간 동안 사용된 컨테이너 메모리 *초입니다. 단위: GB * 초 |
|
|
레이블 7.3.0 이상을 릴리스하는 데 사용 가능 |
게시 기간의 총 얀 컨테이너 *초입니다. 단위: GB * 초 |
|
|
레이블 7.5.0 이상을 릴리스하는 데 사용 가능 |
게시 기간 동안 사용된 컨테이너 VCPU *초입니다. 단위: VCPU *초 |
|
레이블 7.5.0 이상을 릴리스하는 데 사용 가능 |
게시 기간의 총 컨테이너 VCPU *초입니다. 단위: VCPU *초 |
|
|
레이블 7.5.0 이상을 릴리스하는 데 사용 가능 |
게시 기간 동안 사용된 노드 메모리 *초입니다. 단위: GB * 초 |
|
레이블 7.5.0 이상을 릴리스하는 데 사용 가능 |
게시 기간의 총 노드 메모리 *초입니다. 단위: GB * 초 |
|
|
레이블 7.3.0 이상을 릴리스하는 데 사용 가능 |
게시 기간 동안 사용된 노드 VCPU *초입니다. 단위: VCPU *초 |
|
|
레이블 7.3.0 이상을 릴리스하는 데 사용 가능 |
게시 기간의 총 노드 VCPU *초입니다. 단위: VCPU *초 |
Managed Scaling 지표 그래프 작성
다음 단계에 따라 지표를 그래프로 표시하여 클러스터의 워크로드 패턴과 Amazon EMR Managed Scaling에서 내린 해당 조정 결정을 시각화할 수 있습니다.
CloudWatch 콘솔에서 관리형 조정 지표를 그래프로 표시하려면
-
CloudWatch 콘솔
을 엽니다. -
탐색 창에서 Amazon EMR을 선택합니다. 모니터링할 클러스터의 클러스터 ID를 검색할 수 있습니다.
-
그래프 처리할 지표로 스크롤합니다. 그래프를 표시할 측정치를 엽니다.
-
하나 이상의 지표를 그래프 처리하려면 각 지표 옆에 있는 확인란을 선택합니다.
다음 예제에서는 클러스터의 Amazon EMR 관리형 조정 활동을 보여줍니다. 그래프는 3개의 자동 축소 기간을 보여줍니다. 여기서 활성 워크로드가 적은 경우 비용을 절감할 수 있습니다.
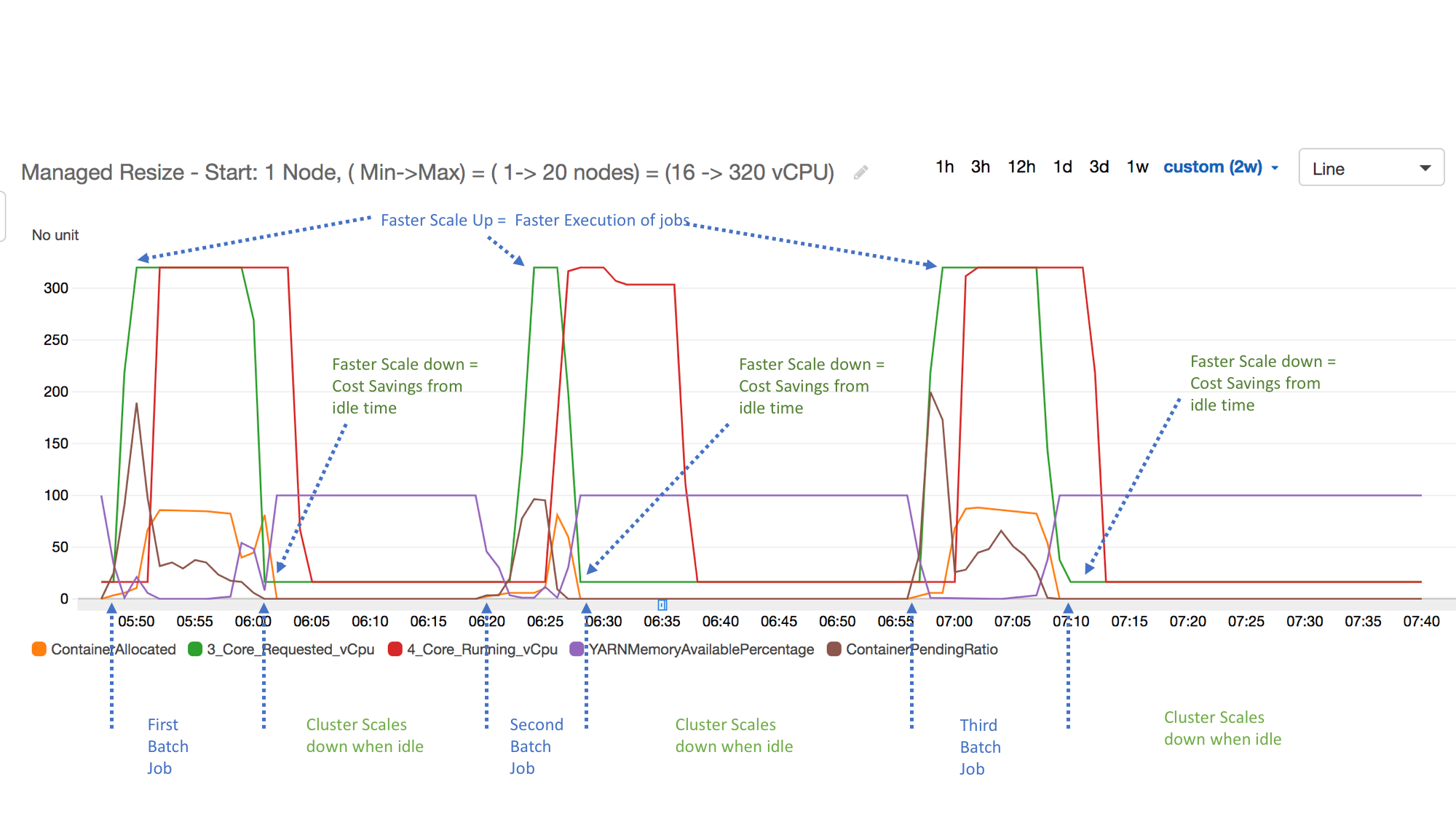
모든 클러스터 용량 및 사용량 지표는 1분 간격으로 게시됩니다. 또한 추가 통계 정보는 각 1분 데이터와 연관되어 Percentiles, Min, Max, Sum, Average, SampleCount 등의 다양한 함수를 표시할 수 있습니다.
예를 들어 다음 그래프는 Sum, Average, Min, SampleCount와 함께 서로 다른 백분위수 P10, P50, P90, P99에서 동일한 YARNMemoryAvailablePercentage 지표를 표시합니다.