Amazon S3 기반(Amazon S3 스토리지 모드)
HBase를 Amazon EMR 버전 5.2.0 이상에서 실행할 경우 다음 이점을 제공하는 Amazon S3 기반 HBase를 활성화할 수 있습니다.
HBase 루트 디렉터리는 HBase 스토어 파일 및 테이블 메타데이터를 포함하여 Amazon S3에 저장됩니다. 이 데이터는 클러스터 외부에서 지속되며 Amazon EC2 가용 영역에서 사용할 수 있으므로 스냅샷이나 다른 방법을 사용하여 복구할 필요가 없습니다.
Amazon S3의 스토어 파일을 사용하면 데이터 요구 사항 대신 계산 요구 사항에 맞게 Amazon EMR 클러스터 크기를 조정하고 HDFS에서 3배로 복제할 수 있습니다.
Amazon EMR 버전 5.7.0 이상을 사용하여 읽기 전용 복제본 클러스터를 설정할 수 있습니다. 그러면 Amazon S3에서 데이터의 읽기 전용 복제본을 유지할 수 있습니다. 읽기 전용 복제본 클러스터에서 데이터에 액세스하여 읽기 작업을 동시에 수행할 수 있습니다. 이는 기본 클러스터를 사용할 수 없는 경우에도 마찬가지입니다.
Amazon EMR 버전 6.2.0 이상에서 영구 HFile 추적은
hbase:storefile이라고 하는 HBase 시스템 테이블을 사용하여 읽기 작업에 사용되는 HFile 경로를 직접 추적합니다. 이 기능은 기본적으로 활성화되어 있으며, 수동 마이그레이션을 수행할 필요가 없습니다.
다음 그림은 Amazon S3 기반 HBase에 관련된 HBase 구성 요소를 보여줍니다.
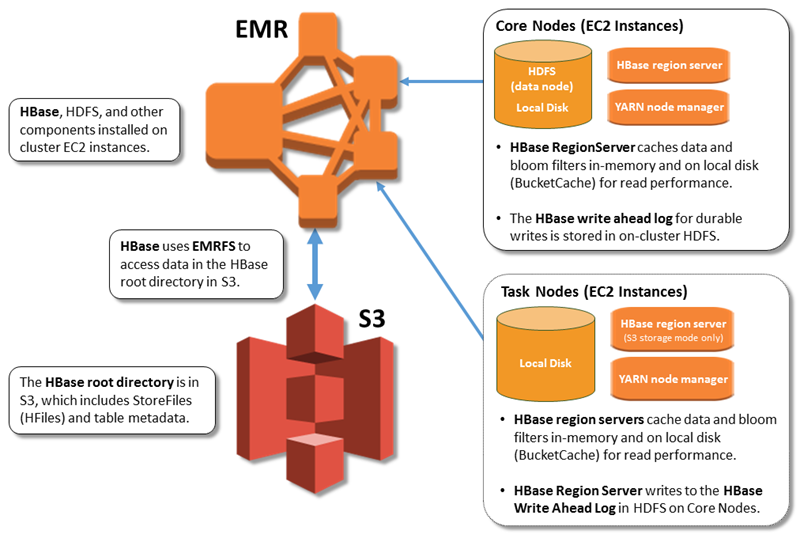
Amazon S3 기반 HBase 활성화
Amazon EMR 콘솔, AWS CLI 또는 Amazon EMR API를 사용하여 Amazon S3 기반 HBase를 활성화할 수 있습니다. 구성은 클러스터 생성시 옵션입니다. 콘솔을 사용할 경우 고급 옵션을 사용하여 설정을 선택합니다. AWS CLI를 사용할 경우 --configurations 옵션을 사용하여 JSON 구성 객체를 제공하십시오. 구성 객체의 속성에서 스토리지 모드와 Amazon S3의 루트 디렉터리 위치를 지정합니다. 지정된 Amazon S3 위치는 Amazon EMR 클러스터와 동일한 리전에 있어야 합니다. 한 번에 하나의 활성 클러스터만 Amazon S3에서 동일한 HBase 루트 디렉터리를 사용해야 합니다. 콘솔 단계와 AWS CLI를 사용하는 자세한 create-cluster 예제는 HBase를 포함하는 클러스터 생성을 참조하십시오. 구성 객체 예제가 다음 JSON 코드 조각에 표시됩니다.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
참고
Amazon S3 버킷을 HBase의 rootdir로 사용하는 경우 Amazon S3 URI의 끝에 슬래시를 추가해야 합니다. 예를 들어, 문제를 방지하기 위해 "hbase.rootdir: s3://amzn-s3-demo-bucket" 대신 "hbase.rootdir: s3://amzn-s3-demo-bucket/"을 사용해야 합니다.
읽기 전용 복제본 클러스터 사용
Amazon S3 기반 HBase를 사용하여 기본 클러스터를 설정한 후 기본 클러스터와 동일한 데이터에 대한 읽기 전용 액세스 권한을 제공하는 읽기 전용 복제본 클러스터를 생성하여 구성할 수 있습니다. 이는 쿼리 데이터에 동시에 액세스해야 하거나 기본 클러스터를 사용할 수 없는 경우에도 중단 없이 액세스해야 하는 경우에 유용합니다. 읽기 전용 복제본 기능은 Amazon EMR 버전 5.7.0 이상에서 사용할 수 있습니다.
기본 클러스터와 읽기 전용 복제본 클러스터는 동일한 방법으로 설정하지만 한 가지 중요한 차이점이 있습니다. 두 클러스터는 모두 동일한 hbase.rootdir 위치를 가리킵니다. 하지만 읽기 전용 복제본 클러스터의 hbase 분류에는 "hbase.emr.readreplica.enabled":"true" 속성이 포함되어 있습니다.
예를 들어, 이 항목의 앞에 표시된 기본 클러스터에 대한 JSON 분류에서 읽기 전용 복제본 클러스터에 대한 구성은 다음과 같습니다.
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://amzn-s3-demo-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
데이터를 추가할 때 읽기 전용 복제본 동기화
읽기 전용 복제본에서는 기본 클러스터에서 Amazon S3에 쓰는 HBase StoreFiles 및 메타데이터를 사용하므로, 읽기 전용 복제본은 Amazon S3 데이터 스토어의 최신 정보만 반영합니다. 다음 지침을 따르면 데이터를 쓸 때 읽기 전용 복제본과 기본 클러스터 사이의 지연 시간을 최소화할 수 있습니다.
가능하면 언제든 기본 클러스터에 데이터를 대량 로드합니다. 자세한 내용은 Apache HBase 설명서에서 Bulk loading
을 참조하세요. 스토어 파일을 Amazon S3에 쓰는 플러시는 데이터를 추가한 후 가능한 빨리 발생해야 합니다. 수동으로 플러시하거나 플러시 설정을 조정하여 지연 시간을 최소화하십시오.
압축이 자동으로 실행될 수 있는 경우 수동 압축을 실행하여 압축이 트리거될 때 불일치가 발생하지 않도록 합니다.
읽기 전용 복제본 클러스터에서 메타데이터가 변경된 경우(예: HBase 리전 분할 또는 압축을 수행한 경우, 테이블을 추가하거나 제거한 경우)
refresh_meta명령을 실행합니다.읽기 전용 복제본 클러스터에서 테이블에서 레코드를 추가하거나 변경할 때
refresh_hfiles명령을 실행합니다.
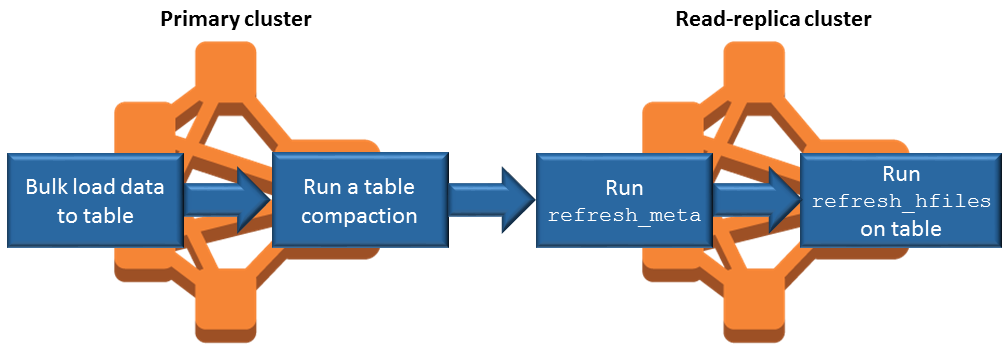
영구 HFile 추적
영구 HFile 추적은 hbase:storefile이라고 하는 HBase 시스템 테이블을 사용하여 읽기 작업에 사용되는 HFile 경로를 직접 추적합니다. HBase에 추가 데이터가 추가되면 새 HFile 경로가 테이블에 추가됩니다. 이렇게 하면 중요한 쓰기 경로 HBase 작업에서 커밋 메커니즘으로 이름 바꾸기 작업이 제거되고, 파일 시스템 디렉터리 나열 대신 hbase:storefile 시스템 테이블에서 읽어 HBase 영역을 열 때 복구 시간이 개선됩니다. 이 기능은 Amazon EMR 버전 6.2.0 이상에서 기본적으로 활성화되어 있으며 수동 마이그레이션 단계가 필요하지 않습니다.
참고
HBase 스토어파일 시스템 테이블을 사용한 지속적 HFile 추적은 HBase 리전 복제 기능을 지원하지 않습니다. HBase 리전 복제에 대한 자세한 내용은 타임라인이 일치하는 고가용성 읽기
영구 HFile 추적 비활성화
영구 HFile 추적은 Amazon EMR 릴리스 6.2.0부터 기본적으로 활성화됩니다. 영구 HFile 추적을 비활성화하려면 클러스터를 시작할 때 다음 구성 재정의를 지정합니다.
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
참고
Amazon EMR 클러스터를 재구성할 때 모든 인스턴스 그룹을 업데이트해야 합니다.
Storefile 테이블 수동 동기화
새 HFile이 생성되면 storefile 테이블이 최신 상태로 유지됩니다. 하지만 어떤 이유로든 storefile 테이블이 데이터 파일과 동기화되지 않는 경우 다음 명령을 사용하여 데이터를 수동으로 동기화할 수 있습니다.
온라인 리전에서 storefile 테이블 동기화:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
오프라인 리전의 storefile 테이블 동기화:
storefile 테이블 znode를 제거합니다.
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]리전을 할당합니다('hbase 쉘'에서 실행).
hbase cli> assign '<region name>'할당이 실패한 경우.
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
storefile 테이블 조정
storefile 테이블은 기본적으로 네 개의 리전으로 분할됩니다. storefile 테이블에 여전히 쓰기 로드가 많은 경우 테이블을 수동으로 더 분할할 수 있습니다.
특정 핫 리전을 분할하려면 다음 명령('hbase shell'에서 실행)을 사용합니다.
hbase cli> split '<region name>'
테이블을 분할하려면 다음 명령('hbase shell'에서 실행)을 사용합니다.
hbase cli> split 'hbase:storefile'
운영상의 고려 사항
HBase 리전 서버는 BlockCache를 사용하여 데이터 읽기를 메모리에 저장하고 BucketCache를 사용하여 데이터 읽기를 로컬 디스크에 저장합니다. 또한 리전 서버는 MemStore를 사용하여 데이터 쓰기를 메모리에 저장하고, 데이터를 Amazon S3의 HBase StoreFiles에 쓰기 전에 write-ahead 로그를 사용하여 데이터 쓰기를 HDFS에 저장합니다. 클러스터의 읽기 성능은 인 메모리 또는 디스크 상의 캐시에서 레코드를 검색할 수 있는 빈도와 관련이 있습니다. 캐시가 누락되면 Amazon S3에 있는 StoreFile에서 레코드를 읽게 되고, 이 경우 HDFS에서 읽는 것보다 훨씬 더 높은 지연 시간과 표준 편차가 발생합니다. 또한 Amazon S3에 대한 최대 요청 속도가 로컬 캐시에서 얻을 수 있는 것보다 낮으므로 읽기가 많은 워크로드의 경우 데이터 캐싱이 중요할 수 있습니다. Amazon S3 성능에 대한 자세한 내용은 Amazon Simple Storage Service 사용 설명서에서 성능 최적화를 참조하세요.
성능을 향상시키려면 가능한 한 많은 데이터 세트를 EC2 인스턴스 스토리지에 캐시하는 것이 좋습니다. BucketCache는 리전 서버의 EC2 인스턴스 스토리지를 사용하기 때문에 충분한 인스턴스 스토어가 있는 EC2 인스턴스 유형을 선택하고 Amazon EBS 스토리지를 추가하여 필요한 캐시 크기를 수용할 수 있습니다. hbase.bucketcache.size 속성을 사용하여 연결된 인스턴스 스토어 및 EBS 볼륨에서 BucketCache 크기를 늘릴 수도 있습니다. 기본 설정은 8,192MB입니다.
쓰기의 경우 MemStore 플러시의 빈도 및 사소한 압축 및 주요 압축 중에 제공되는 StoreFiles 수가 리전 서버 응답 시간 증가에 크게 기여할 수 있습니다. 최적의 성능을 얻기 위해 MemStore 플러시 및 HRegion 블록 승수 크기를 늘리면 주요 압축 사이의 경과 시간이 늘어나지만, 읽기 전용 복제본을 사용할 경우 일치하는 데 지연 시간이 길어질 수 있습니다. 경우에 따라 더 큰 파일 블록 크기(5GB 미만)를 사용하여 EMRFS에서 Amazon S3 멀티파트 업로드 기능을 트리거하여 성능을 향상시킬 수 있습니다. Amazon EMR의 기본 블록 크기는 128MB입니다. 자세한 내용은 HDFS 구성 단원을 참조하십시오. 플러시 및 압축으로 성능을 벤치마킹하는 동안 1GB 블록 크기를 초과하는 고객은 거의 없었습니다. 또한 HBase 압축 및 리전 서버는 더 적은 수의 StoreFile을 압축해야 할 때 최적으로 작동합니다.
큰 디렉터리는 이름을 바꾸어야 하기 때문에 테이블을 Amazon S3에서 삭제하는 데 상당한 시간이 걸릴 수 있습니다. 삭제하는 대신 테이블을 비활성화하는 것이 좋습니다.
오래된 WAL 파일과 스토어 파일을 정리하는 HBase 클리너 프로세스가 있습니다. Amazon EMR 릴리스 버전 5.17.0 이상을 사용하면 클리너가 전역적으로 활성화되고 다음 구성 속성을 사용하여 클리너 동작을 제어할 수 있습니다.
| 구성 속성 | 기본값 | 설명 |
|---|---|---|
|
|
1 |
만료된 큰 HFiles를 삭제하기 위해 할당된 스레드 수 |
|
|
1 |
만료된 작은 HFiles를 삭제하기 위해 할당된 스레드 수 |
|
|
사용 가능한 모든 코어의 1/4로 설정합니다. |
oldWALs 디렉터리를 스캔하기 위한 스레드 수 |
|
|
2 |
oldWALs 디렉터리 밑의 WALs를 삭제하기 위한 스레드 수 |
Amazon EMR 5.17.0 이전을 사용하는 경우 과중한 워크로드를 실행할 때 클리너 작업은 쿼리 성능에 영향을 줄 수 있으므로 사용량이 적은 시간에만 클리너를 사용하는 것이 좋습니다. 클리너에는 다음 HBase 셸 명령이 있습니다.
cleaner_chore_enabled는 클리너가 활성화되었는지 여부를 쿼리합니다.cleaner_chore_run는 클리너를 수동으로 실행하여 파일을 제거합니다.cleaner_chore_switch는 클리너를 활성화 또는 비활성화하고 클리너의 이전 상태를 반환합니다. 예를 들어,cleaner_chore_switch true는 클리너를 활성화합니다.
Amazon S3 기반 HBase 성능 튜닝을 위한 속성
Amazon S3 기반 HBase를 사용할 때 다음 파라미터를 조정하여 워크로드 성능을 조정할 수 있습니다.
| 구성 속성 | 기본값 | 설명 |
|---|---|---|
|
|
8,192 |
리전 서버 Amazon EC2 인스턴스 스토어 및 BucketCache 스토리지용 EBS 볼륨에 예약된 디스크 공간(MB)입니다. 설정은 모든 리전 서버 인스턴스에 적용됩니다. 큰 BucketCache 크기는 일반적으로 향상된 성능에 해당합니다. |
|
|
134217728 |
Amazon S3에 대한 memstore 플러시가 트리거되는 데이터 한도(바이트)입니다. |
|
|
4 |
업데이트가 차단되는 MemStore 상한을 결정하는 승수입니다. MemStore가 이 값을 곱한 |
|
|
10 |
업데이트가 차단되기 전에 스토어에 존재할 수 있는 StoreFiles의 최대 수입니다. |
|
|
10737418240 |
리전을 분할하기 이전의 리전의 최대 크기입니다. |
데이터 손실 없이 클러스터 종료 및 복원
Amazon S3에 기록되지 않은 데이터 손실 없이 Amazon EMR 클러스터를 종료하려면 MemStore 캐시를 Amazon S3에 플러시하여 새 스토어 파일을 작성해야 합니다. 먼저 모든 테이블을 비활성화해야 합니다. 다음 단계 구성은 클러스터에 단계를 추가할 때 사용할 수 있습니다. 자세한 내용은 Amazon EMR 관리 안내서에서 AWS CLI 및 콘솔을 사용하여 단계 작업을 참조하세요.
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
또는 다음 bash 명령을 직접 실행할 수도 있습니다.
bash /usr/lib/hbase/bin/disable_all_tables.sh
모든 테이블을 비활성화한 후 HBase 쉘과 다음 명령을 사용하여 hbase:meta 테이블을 플러시합니다.
flush 'hbase:meta'
그런 다음 Amazon EMR 클러스터에 제공된 쉘 스크립트를 실행하여 MemStore 캐시를 플러시할 수 있습니다. 단계별로 추가하거나 클러스터 내 AWS CLI를 사용하여 직접 실행할 수 있습니다. 이 스크립트는 모든 리전 서버의 MemStore가 Amazon S3로 플러시되도록 모든 HBase 테이블을 비활성화합니다. 스크립트가 성공적으로 완료되면 데이터는 Amazon S3에 유지되고 클러스터는 종료될 수 있습니다.
동일한 HBase 데이터로 클러스터를 다시 시작하려면 AWS Management Console에서 또는 hbase.rootdir 구성 속성을 사용하여 이전 클러스터와 동일한 Amazon S3 위치를 지정합니다.
