기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Iceberg 작동 방식
Iceberg는 디렉터리가 아닌 테이블에서 개별 데이터 파일을 추적합니다. 이렇게 하면 작성자가 데이터 파일을 제자리에 생성할 수 있습니다(파일을 이동하거나 변경하지 않음). 또한 작성자는 명시적 커밋을 통해서만 테이블에 파일을 추가할 수 있습니다. 테이블 상태는 메타데이터 파일에서 유지 관리됩니다. 테이블 상태가 변경되면 항상 메타데이터를 자동으로 대체하는 새 메타데이터 파일이 생성됩니다. 테이블 메타데이터 파일은 테이블 스키마, 파티셔닝 구성 및 기타 속성을 추적합니다.
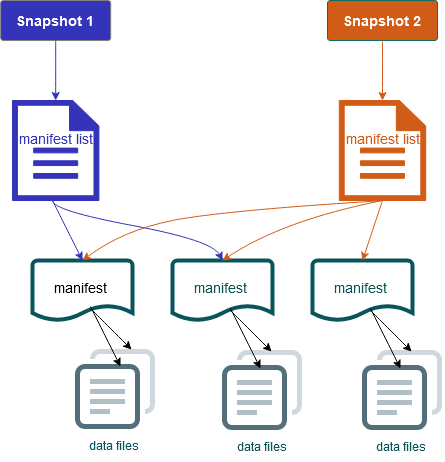
또한 테이블 콘텐츠의 스냅샷도 포함합니다. 각 스냅샷은 특정 시점에 테이블에 있는 전체 데이터 파일 세트입니다. 스냅샷은 메타데이터 파일에 나열되지만 스냅샷의 파일은 별도의 매니페스트 파일에 저장됩니다. 한 테이블 메타데이터 파일에서 다음 테이블 메타데이터 파일로의 원자적 전환은 스냅샷 격리를 제공합니다. 독자는 테이블 메타데이터를 로드했을 때 최신 상태였던 스냅샷을 사용합니다. 독자는 새로 고침을 통해 새 메타데이터 위치를 선택할 때까지 변경 사항의 영향을 받지 않습니다. 스냅샷의 데이터 파일은 테이블의 각 데이터 파일, 파티션 데이터 및 지표에 대한 행을 포함하는 하나 이상의 매니페스트 파일에 저장됩니다. 스냅샷은 매니페스트에 있는 모든 파일을 통합한 것입니다. 자주 변경되지 않는 메타데이터를 다시 작성하지 않도록 스냅샷 간에 매니페스트 파일을 공유할 수도 있습니다.
Iceberg 스냅샷 다이어그램
Iceberg는 다음 기능을 제공합니다.
-
Amazon S3 데이터 레이크에서 ACID 트랜잭션 및 시간 이동을 지원합니다.
-
커밋 재시도를 통해 낙관적 동시성
의 성능 이점을 활용합니다. -
파일 수준 충돌 해결은 높은 동시성을 제공합니다.
-
메타데이터의 열당 최소 및 최대 통계를 사용하면 파일을 건너뛸 수 있어서 선택적 쿼리의 성능이 향상됩니다.
-
파티션 스키마에 대한 업데이트를 활성화하는 파티션 진화를 통해 테이블을 유연한 파티션 레이아웃으로 구성할 수 있습니다. 그러면 실제 디렉터리에 의존하지 않고도 쿼리와 데이터 볼륨을 변경할 수 있습니다.
-
스키마 진화
및 적용을 지원합니다. -
Iceberg 테이블은 멱등성 싱크 및 재생 가능한 소스 역할을 합니다. 이를 통해 정확히 한 번의 파이프라인으로 스트리밍 및 배치 지원이 가능합니다. 멱등성 싱크는 이전에 성공했던 쓰기 작업을 추적합니다. 따라서 싱크는 장애 발생 시 데이터를 다시 요청하고, 여러 번 전송된 경우 데이터를 삭제할 수 있습니다.
-
테이블 진화, 작업 기록, 각 커밋에 대한 통계를 포함한 기록과 계보를 확인합니다.
-
데이터 형식(Parquet, ORC, Avro) 및 분석 엔진(Spark, Trino, PrestoDB, Flink, Hive)을 선택하여 기존 데이터 세트에서 마이그레이션합니다.
