기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon에서 Flink 구성 EMR
Hive 메타스토어 및 Glue 카탈로그를 사용하여 Flink 구성
Amazon EMR 릴리스 6.9.0 이상은 Hive에 대한 Apache Flink 커넥터를 사용하여 Hive 메타스토어와 AWS Glue 카탈로그를 모두 지원합니다. 이 섹션에서는 Flink를 사용하여 AWS Glue 카탈로그 및 Hive 메타스토어를 구성하는 데 필요한 단계를 설명합니다.
Hive 메타스토어 사용
-
릴리스 6.9.0 이상 및 Hive와 Flink라는 두 개 이상의 애플리케이션을 사용하여 EMR 클러스터를 생성합니다.
-
스크립트 러너를 사용하여 다음 스크립트를 단계 함수로 실행합니다.
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar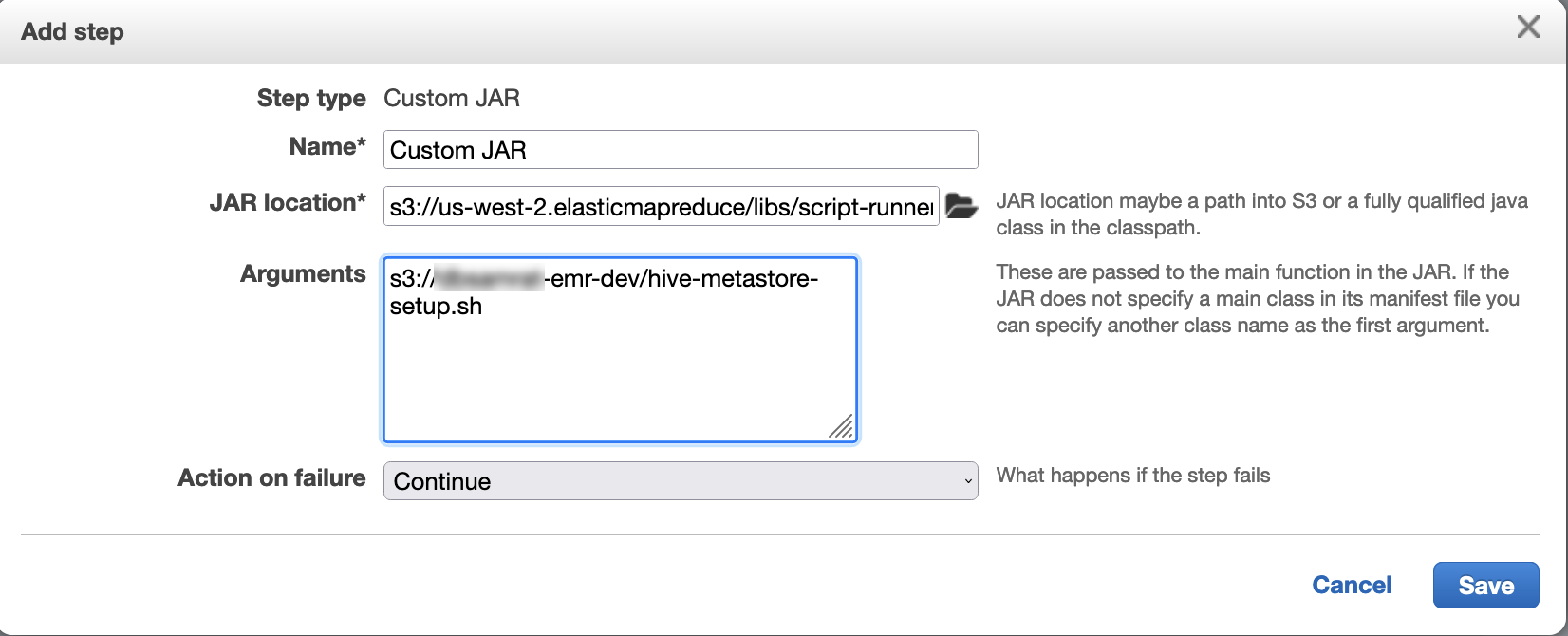
AWS Glue 데이터 카탈로그 사용
-
릴리스 6.9.0 이상 및 Hive와 Flink라는 두 개 이상의 애플리케이션을 사용하여 EMR 클러스터를 생성합니다.
-
AWS Glue 데이터 카탈로그 설정에서 Hive 테이블 메타데이터에 사용을 선택하여 클러스터에서 데이터 카탈로그를 활성화합니다.
-
스크립트 러너를 사용하여 단계 함수로 다음 스크립트를 실행합니다. Amazon EMR 클러스터에서 명령 및 스크립트 실행:
glue-catalog-setupsh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
구성 파일을 사용하여 Flink 구성
Amazon EMR 구성을 사용하여 API 구성 파일로 Flink를 구성할 수 있습니다. 내에서 구성할 수 있는 파일은 다음과 API 같습니다.
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
Flink용 기본 구성 파일은 flink-conf.yaml입니다.
AWS CLI를 사용하여 Flink에 사용되는 작업 슬롯 수를 구성하는 방법
-
다음 콘텐츠가 포함된
configurations.json파일을 생성합니다.[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
다음 구성을 사용하여 클러스터를 생성합니다.
aws emr create-cluster --release-labelemr-7.5.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
참고
Flink를 사용하여 일부 구성을 변경할 수도 있습니다API. 자세한 내용은 Flink 설명서에서 Concepts
Amazon EMR 버전 5.21.0 이상을 사용하면 클러스터 구성을 재정의하고 실행 중인 클러스터의 각 인스턴스 그룹에 대해 추가 구성 분류를 지정할 수 있습니다. Amazon EMR 콘솔, AWS Command Line Interface (AWS CLI) 또는를 사용하여이 작업을 수행합니다 AWS SDK. 자세한 내용은 실행 중 클러스터의 인스턴스 그룹에 대해 구성 제공을 참조하십시오.
병렬 처리 옵션
애플리케이션 소유자는 Flink 내에서 작업에 할당할 리소스를 잘 알고 있습니다. 이 설명서의 예제에서는 애플리케이션에 사용되는 태스크 인스턴스와 동일한 개수의 작업을 사용합니다. 일반적으로 이러한 사용은 초기 수준의 병렬화에 권장되지만, 작업 슬롯을 사용하여 더 세부적으로 병렬화할 수도 있습니다. 이 경우 일반적으로 인스턴스당 가상 코어
여러 기본 노드가 있는 EMR 클러스터에서 Flink 구성
Flink JobManager 의는 여러 프라이머리 노드가 있는 Amazon EMR 클러스터에서 프라이머리 노드 장애 조치 프로세스 중에도 사용할 수 있습니다. Amazon EMR 5.28.0부터는 JobManager 고가용성도 자동으로 활성화됩니다. 수동 구성이 필요하지 않습니다.
Amazon EMR 버전 5.27.0 이하에서는 JobManager 가 단일 장애 지점입니다. 가 JobManager 실패하면 모든 작업 상태가 손실되고 실행 중인 작업이 재개되지 않습니다. 다음 예제와 같이 애플리케이션 시도 횟수를 구성하고, 체크포인트를 지정하고, Flink의 상태 스토리지 ZooKeeper 로를 활성화하여 JobManager 고가용성을 활성화할 수 있습니다.
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
에 대한 최대 애플리케이션 마스터 시도YARN와 Flink에 대한 애플리케이션 시도를 모두 구성해야 합니다. 자세한 내용은 YARN 클러스터 고가용성 구성을
메모리 프로세스 크기 구성
Flink 1.11.x를 사용하는 Amazon EMR 버전의 경우에서 (jobmanager.memory.process.size) 및 TaskManager (taskmanager.memory.process.size) 모두에 JobManager 대한 총 메모리 프로세스 크기를 구성해야 합니다flink-conf.yaml. 구성으로 클러스터를 구성하거나를 통해 이러한 필드의 주석 처리를 API 수동으로 해제하여 이러한 값을 설정할 수 있습니다SSH. Flink는 다음과 같은 기본값을 제공합니다.
-
jobmanager.memory.process.size: 1,600m -
taskmanager.memory.process.size: 1,728m
JVM 메타스페이스와 오버헤드를 제외하려면 대신 총 Flink 메모리 크기(taskmanager.memory.flink.size)를 사용합니다taskmanager.memory.process.size. taskmanager.memory.process.size의 기본값은 1,280m입니다. taskmanager.memory.process.size 및 taskmanager.memory.process.size를 모두 설정하는 것은 권장되지 않습니다.
Flink 1.12.0 이상을 사용하는 모든 Amazon EMR 버전은 Flink용 오픈 소스 세트에 Amazon의 기본값으로 나열된 기본값을 가지EMR므로 직접 구성할 필요가 없습니다.
로그 출력 파일 크기 구성
Flink 애플리케이션 컨테이너는 .out 파일, .log 파일, .err 파일과 같은 세 가지 유형의 로그 파일을 생성하고 작성합니다. .err 파일만 압축되어 파일 시스템에서 제거되고, .log 및 .out 로그 파일은 파일 시스템에 남습니다. 이러한 출력 파일을 관리할 수 있고 클러스터를 안정적으로 유지하기 위해 최대 파일 수를 설정하고 파일 크기를 제한하도록 log4j.properties에서 로그 로테이션을 구성할 수 있습니다.
Amazon EMR 버전 5.30.0 이상
Amazon EMR 5.30.0부터 Flink는 구성 분류 이름이 인 log4j2 로깅 프레임워크를 사용합니다. 다음 예제 구성flink-log4j.은 log4j2 형식을 보여줍니다.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR 버전 5.29.0 이하
Amazon EMR 버전 5.29.0 이하에서는 Flink가 log4j 로깅 프레임워크를 사용합니다. 다음 구성 예제에서는 log4j 형식을 보여줍니다.
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Java 11과 함께 실행하도록 Flink 구성
Amazon EMR 릴리스 6.12.0 이상은 Flink에 대한 Java 11 런타임 지원을 제공합니다. 다음 섹션에서는 Flink에 대한 Java 11 런타임 지원을 제공하도록 클러스터를 구성하는 방법을 설명합니다.
클러스터를 생성할 때 Java 11용 Flink 구성
다음 단계에 따라 Flink 및 Java 11 런타임을 사용하여 EMR 클러스터를 생성합니다. Java 11 런타임 지원을 추가하는 구성 파일은 flink-conf.yaml입니다.
실행 중인 클러스터에서 Java 11용 Flink 구성
다음 단계에 따라 Flink 및 Java 11 런타임으로 실행 중인 EMR 클러스터를 업데이트합니다. Java 11 런타임 지원을 추가하는 구성 파일은 flink-conf.yaml입니다.
실행 중인 클러스터에서 Flink의 Java 런타임 확인
실행 중인 클러스터의 Java 런타임을 확인하려면를 사용하여 기본 노드에 연결에 설명된 SSH 대로를 사용하여 기본 노드에 로그인합니다. SSH 그런 다음, 다음 명령을 실행합니다.
ps -ef | grep flink
-ef 옵션과 함께 ps 명령은 시스템에서 실행 중인 모든 프로세스를 나열합니다. grep로 해당 출력을 필터링하여 flink 문자열에 대한 언급을 찾을 수 있습니다. Java 런타임 환경(JRE) 값에 대한 출력을 검토합니다jre-XX. 다음 출력에서 jre-11은 런타임에 Flink용으로 Java 11이 선택되었음을 나타냅니다.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
또는 를 사용하여 기본 노드에 로그인SSH하고 명령를 사용하여 Flink YARN 세션을 시작합니다flink-yarn-session -d. 출력은 다음 예제java-11-amazon-corretto에서 Flink용 Java 가상 머신(JVM)을 보여줍니다.
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
