신규 고객은 Amazon Forecast를 더 이상 사용할 수 없습니다. Amazon Forecast의 기존 고객은 평소와 같이 서비스를 계속 사용할 수 있습니다. 자세히 알아보기
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
누락 값 처리
시계열 예측 데이터의 일반적인 문제는 누락된 값이 있다는 것입니다. 측정 실패, 서식 문제, 인적 오류 또는 기록할 정보 부족 등 여러 가지 이유로 데이터에 누락된 값이 포함될 수 있습니다. 예를 들어 소매점 제품 수요를 예측할 때 품목이 매진되었거나 공급되지 않는 경우 해당 품목이 품절된 동안에는 기록할 판매 데이터가 없습니다. 누락된 값은 충분히 많을 경우 모델의 정확도에 큰 영향을 미칠 수 있습니다.
Amazon Forecast는 대상 시계열 및 관련 시계열 데이터 세트에서 누락된 값을 처리하기 위한 여러 가지 채우기 방법을 제공합니다. 채우기는 데이터세트에서 누락된 항목에 표준화된 값을 추가하는 프로세스입니다.
Forecast는 다음과 같은 채우기 방법을 지원합니다.
-
중간 채우기 - 데이터 세트의 항목 시작 날짜와 항목 종료 날짜 사이에 누락된 값을 채웁니다.
-
뒤로 채우기 - 데이터 세트의 마지막으로 기록된 데이터 포인트와 글로벌 종료 날짜 사이에 누락된 값을 채웁니다.
-
앞으로 채우기(관련 시계열에만 해당) - 데이터 세트의 글로벌 종료 날짜와 예측 기간 종료 사이에 누락된 값을 채웁니다.
다음 이미지는 다양한 채우기 방법을 시각적으로 나타냅니다.
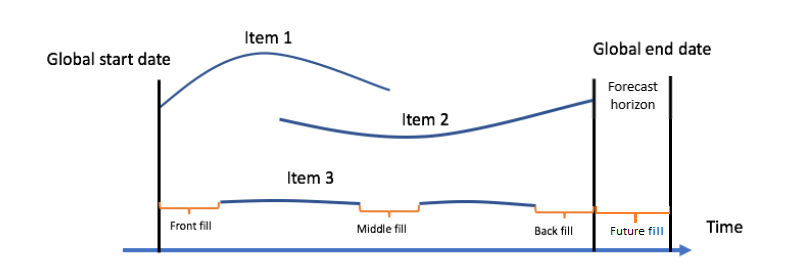
채우기 로직 선택
채우기 로직을 선택할 때 모델에서 로직을 해석하는 방법을 고려해야 합니다. 예를 들어, 소매 시나리오에서 재고 품목의 판매량이 0을 기록하는 것은 품절 품목의 판매량이 0을 기록하는 것과 다릅니다. 후자가 해당 품목에 대한 고객의 관심 부족을 의미하지는 않습니다. 이 때문에 대상 시계열에서 0 채우기는 예측에서 예측기를 과소 편향시킬 수 있는 반면, NaN 채우기는 실제 발생한 재고 품목 판매량 0을 무시하고 예측기를 과다 편향시킬 수 있습니다.
다음 시계열 그래프는 잘못된 채우기 값 선택이 모형의 정확도에 어떤 영향을 미치는지 보여줍니다. 그래프 A 및 B는 부분적으로 품절된 품목에 대한 수요를 표시하며 검은색 선은 실제 판매량 데이터를 나타냅니다. A1의 누락된 값은 0으로 채워져 A2에서 상대적으로 과소 편향된 예측(점선 표시)을 초래합니다. 마찬가지로 B1의 누락된 값은 NaN으로 채워져 B2에서 보다 정확한 예측으로 이어집니다.

지원되는 채우기 로직의 목록은 다음 단원을 참조하십시오.
대상 시계열 및 관련 시계열 채우기 로직
대상 시계열 및 관련 시계열 데이터 세트 모두에 채우기를 수행할 수 있습니다. 각 데이터 세트 유형에는 서로 다른 채우기 지침과 제한 사항이 있습니다.
| 데이터세트 유형 | 기본적으로 채우기? | 지원되는 채우기 방법 | 기본 채우기 로직 | 허용되는 채우기 로직 |
|---|---|---|---|---|
| 대상 시계열 | 예 | 중간 및 뒤로 채우기 | 0 |
|
| 관련 시계열 | 아니요 | 중간, 뒤로 및 앞으로 채우기 | 기본값 없음 |
|
중요
대상 및 관련 시계열 데이터 세트 모두 mean, median, min, max는 누락된 값 이전의 최근 데이터 항목 64개가 포함된 이동 구간을 기반으로 계산됩니다.
누락 값 구문
누락 값 채우기를 수행하려면 CreatePredictor 작업을 직접적으로 호출할 때 구현할 채우기 유형을 지정합니다. 채우기 로직은 FeaturizationMethod 객체에서 지정됩니다.
다음 발췌 내용은 대상 시계열 속성 및 관련 시계열 속성(각각 target_value 및 price)에 대해 올바른 형식의 FeaturizationMethod 개체를 보여 줍니다.
채우기 메서드를 특정 값으로 설정하려면 채우기 파라미터를 value로 설정하고 해당 _value 파라미터에서 값을 정의하세요. 아래 그림과 같이 관련 시계열의 뒤로 채우기는 "backfill": "value" 및 "backfill_value":"2"를 사용하여 값 2로 설정됩니다.
[ { "AttributeName": "target_value", "FeaturizationPipeline": [ { "FeaturizationMethodName": "filling", "FeaturizationMethodParameters": { "aggregation": "sum", "middlefill": "zero", "backfill": "zero" } } ] }, { "AttributeName": "price", "FeaturizationPipeline": [ { "FeaturizationMethodName": "filling", "FeaturizationMethodParameters": { "middlefill": "median", "backfill": "value", "backfill_value": "2", "futurefill": "max" } } ] } ]
