기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon FSx for Lustre 성능
이 장에서는 파일 시스템의 성능을 극대화하기 위한 몇 가지 중요한 팁과 권장 사항을 포함하여 Amazon FSx for Lustre의 성능 주제에 대해 설명합니다.
주제
개요
인기 있는 고성능 파일 시스템인 Lustre를 기반으로 구축된 Amazon FSx for Lustre는 파일 시스템의 크기에 따라 선형적으로 증가하는 스케일아웃 성능을 제공합니다. Lustre 파일 시스템은 여러 파일 서버와 디스크에 걸쳐 수평적으로 확장됩니다. 이러한 확장을 통해 각 클라이언트는 각 디스크에 저장된 데이터에 직접 액세스하여 기존 파일 시스템에 존재하는 여러 병목 현상을 없앨 수 있습니다. Amazon FSx for Lustre는 Lustre의 확장 가능한 아키텍처를 기반으로 구축되어 많은 클라이언트에서 높은 수준의 성능을 지원합니다.
FSx for Lustre 파일 시스템의 작동 방식
각 FSx for Lustre 파일 시스템은 클라이언트가 통신하는 파일 서버와 데이터를 저장하는 각 파일 서버에 연결된 디스크 세트로 구성됩니다. 각 파일 서버는 고속 인 메모리 캐시를 사용하여 가장 자주 액세스하는 데이터의 성능을 향상시킵니다. 스토리지 클래스에 따라 SSD 읽기 캐시(선택 사항)를 포함해 파일 서버를 프로비저닝할 수 있습니다. 클라이언트가 인메모리 또는 SSD 캐시에 저장된 데이터에 액세스할 때 파일 서버는 디스크에서 데이터를 읽을 필요가 없으므로 지연 시간이 줄어들고 총 처리량을 늘릴 수 있습니다. 다음 다이어그램은 쓰기 작업, 디스크에서 제공되는 읽기 작업, 인 메모리 또는 SSD 캐시에서 제공되는 읽기 작업의 경로를 보여줍니다.
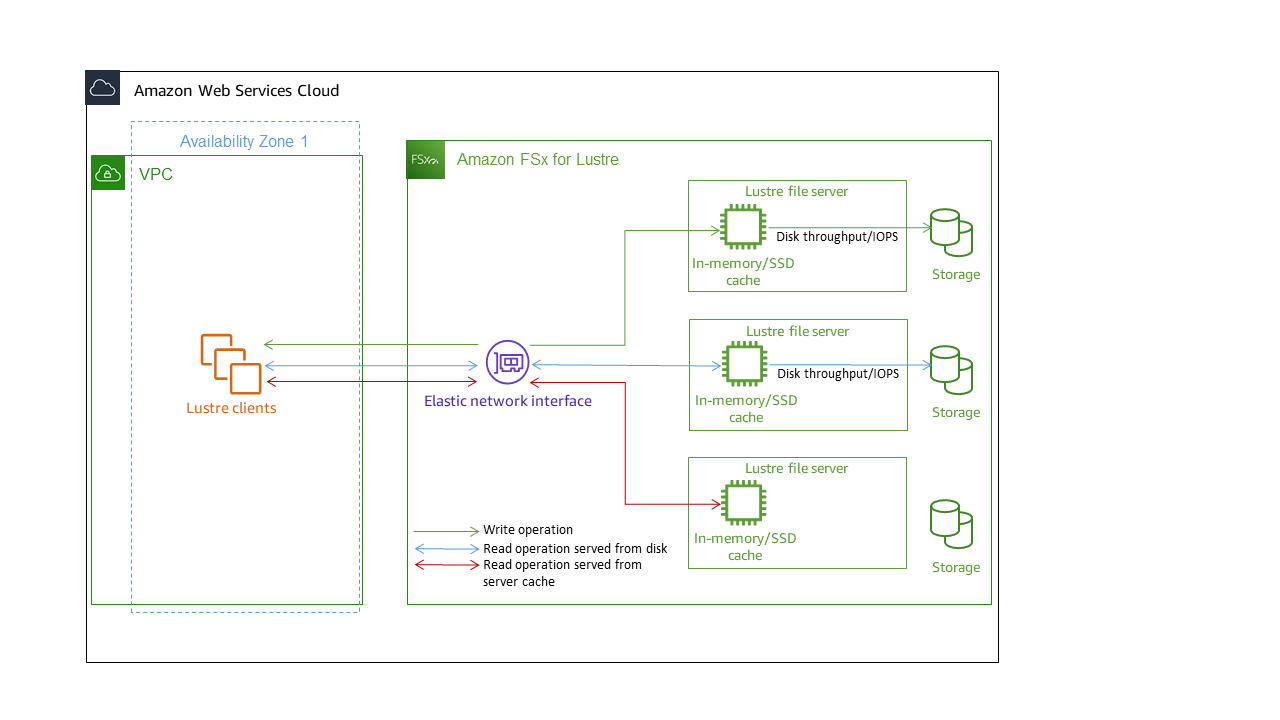
파일 서버의 인 메모리 또는 SSD 캐시에 저장된 데이터를 읽을 때 파일 시스템 성능은 네트워크 처리량에 따라 결정됩니다. 파일 시스템에 데이터를 쓰거나 인 메모리 캐시에 저장되지 않은 데이터를 읽을 때 파일 시스템 성능은 네트워크 처리량과 디스크 처리량 중 낮은 값에 따라 결정됩니다.
SSD 및 HDD 스토리지 클래스의 네트워크 처리량, 디스크 처리량, IOPS 특성에 대한 자세한 내용은 SSD 및 HDD 스토리지 클래스의 성능 특성 및 Intelligent-Tiering 스토리지 클래스의 성능 특성 섹션을 참조하세요.
파일 시스템 메타데이터 성능
파일 시스템 메타데이터 초당 IO 작업(IOPS)은 초당 생성, 나열, 읽기 및 삭제할 수 있는 파일 및 디렉터리 수를 결정합니다.
Persistent 2 파일 시스템을 사용하면 스토리지 용량과 관계없이 메타데이터 IOPS를 프로비저닝하고 파일 시스템에서 구동되는 메타데이터 IOPS 클라이언트 인스턴스의 수와 유형에 대한 가시성을 높일 수 있습니다. SSD 파일 시스템에서는 프로비저닝한 스토리지 용량에 따라 메타데이터 IOPS가 자동으로 프로비저닝됩니다. Intelligent-Tiering 파일 시스템에서는 자동 모드가 지원되지 않습니다.
FSx for Lustre Persistent 2 파일 시스템을 사용하면 프로비저닝하는 메타데이터 IOPS 수와 메타데이터 작업 유형에 따라 파일 시스템이 지원할 수 있는 메타데이터 작업 속도가 결정됩니다. 프로비저닝하는 메타데이터 IOPS 수준은 파일 시스템의 메타데이터 디스크에 프로비저닝된 IOPS 수를 결정합니다.
| 작업 유형 | 프로비저닝된 각 메타데이터 IOPS에 대해 초당 구동할 수 있는 작업 |
|---|---|
|
파일 생성, 열기 및 닫기 |
2 |
|
파일 삭제 |
1 |
|
디렉터리 생성, 이름 변경 |
0.1 |
|
디렉터리 삭제 |
0.2 |
SSD 파일 시스템의 경우 자동 모드를 사용하여 메타데이터 IOPS를 프로비저닝하도록 선택할 수 있습니다. 자동 모드에서 Amazon FSx는 아래 표에 따라 파일 시스템의 스토리지 용량에 따라 메타데이터 IOPS를 자동으로 프로비저닝합니다.
| 파일 시스템 스토리지 용량 | 자동 모드에 메타데이터 IOPS 포함 |
|---|---|
|
1200 GiB |
1500 |
|
2400 GiB |
3000 |
|
4800–9600 GiB |
6000 |
|
12000–45600 GiB |
12000 |
|
≥48000GiB |
24,000GiB당 12,000 IOPS |
사용자 프로비저닝 모드에서 프로비저닝할 메타데이터 IOPS 수를 선택적으로 지정할 수 있습니다. 유효한 값은 다음과 같습니다.
SSD 파일 시스템의 경우 유효한 값은
1500,3000,6000,12000및12000의 배수(최대192000)입니다.Intelligent-Tiering 파일 시스템의 경우 유효한 값은
6000및12000입니다.
메타데이터 IOPS를 구성하는 방법에 대한 자세한 내용은 메타데이터 성능 관리 섹션을 참조하세요. 파일 시스템의 기본 메타데이터 IOPS 수를 초과하여 프로비저닝된 메타데이터 IOPS에 대해 비용이 부과됩니다.
개별 클라이언트 인스턴스에 대한 처리량
처리량 용량이 10GBps 이상인 파일 시스템을 생성하는 경우 Elastic Fabric Adapter(EFA)를 활성화하여 클라이언트 인스턴스당 처리량을 최적화하는 것이 좋습니다. 클라이언트 인스턴스당 처리량을 더욱 최적화하기 위해 EFA 지원 파일 시스템은 또한 EFA 지원 NVIDIA GPU 기반 클라이언트 인스턴스에 대해 GPUDirect Storage를 지원하고 ENA Express 지원 클라이언트 인스턴스에 대해 ENA Express를 지원합니다.
하나의 클라이언트 인스턴스에서 끌어낼 수 있는 처리량은 선택한 파일 시스템 유형과 클라이언트 인스턴스의 네트워크 인터페이스에 따라 달라집니다.
| 파일 시스템 유형 | 클라이언트 인스턴스 네트워크 인터페이스 | 클라이언트당 최대 처리량, Gbps |
|---|---|---|
|
EFA 미지원 |
임의 |
100Gbps* |
|
EFA 지원 |
ENA |
100Gbps* |
|
EFA 지원 |
ENA Express |
100Gbps |
|
EFA 지원 |
EFA |
700Gbps |
|
EFA 지원 |
EFA와 GDS 함께 사용 |
1200Gbps |
참고
* 개별 클라이언트 인스턴스와 개별 FSx for Lustre 객체 스토리지 서버 간의 트래픽은 5Gbps로 제한됩니다. FSx for Lustre 파일 시스템의 기반이 되는 객체 스토리지 서버의 수는 파일 시스템의 IP 주소 섹션을 참조하세요.
파일 시스템 스토리지 레이아웃
Lustre의 모든 파일 데이터는 객체 스토리지 타겟(OST)이라는 스토리지 볼륨에 저장됩니다. 모든 파일 메타데이터(파일 이름, 타임스탬프, 권한 등 포함)는 메타데이터 대상(MDT)이라는 스토리지 볼륨에 저장됩니다. Amazon FSx for Lustre 파일 시스템은 하나 이상의 MDT와 여러 개의 OST로 구성됩니다. Amazon FSx for Lustre는 파일 시스템을 구성하는 OST 전체에 파일 데이터를 분산하여 스토리지 용량과 처리량 및 IOPS 부하의 균형을 유지합니다.
파일 시스템을 구성하는 MDT 및 OST의 스토리지 사용량을 보려면 파일 시스템이 마운트된 클라이언트에서 다음 명령을 실행합니다.
lfs df -hmount/path
이 명령의 출력은 다음과 같습니다.
예
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
파일 시스템의 스트라이핑 데이터
파일 스트라이핑으로 파일 시스템의 처리량 성능을 최적화할 수 있습니다. Amazon FSx for Lustre는 모든 스토리지 서버에서 데이터가 제공되도록 하기 위해 파일을 여러 OST에 자동으로 분산합니다. 파일이 여러 OST에 스트라이핑되는 방식을 구성하여 파일 수준에서 동일한 개념을 적용할 수 있습니다.
스트라이핑이란 파일을 여러 청크로 나눈 다음 여러 OST에 저장할 수 있다는 뜻입니다. 파일이 여러 OST에 스트라이핑되면 파일에 대한 읽기 또는 쓰기 요청이 해당 OST 전체에 분산되어 애플리케이션이 처리할 수 있는 총 처리량 또는 IOPS가 증가합니다.
Amazon FSx for Lustre 파일 시스템의 기본 레이아웃은 다음과 같습니다.
2020년 12월 18일 이전에 생성된 파일 시스템의 경우 기본 레이아웃은 스트라이프 수를 1로 지정합니다. 즉, 다른 레이아웃을 지정하지 않는 한 표준 Linux 도구를 사용하여 Amazon FSx for Lustre에서 만든 각 파일은 단일 디스크에 저장됩니다.
2020년 12월 18일 이후에 생성된 파일 시스템의 경우 기본 레이아웃은 크기가 1GiB 미만인 파일이 하나의 스트라이프에 저장되는 프로그레시브 파일 레이아웃이고 큰 파일에는 스트라이프 수 5가 할당됩니다.
2023년 8월 25일 이후에 생성된 파일 시스템의 경우 기본 레이아웃은 프로그레시브 파일 레이아웃에서 설명하는 4구성 요소 프로그레시브 파일 레이아웃입니다.
생성 날짜와 상관없이 모든 파일 시스템에서 Amazon S3에서 가져온 파일은 기본 레이아웃을 사용하지 않고 대신 파일 시스템
ImportedFileChunkSize파라미터의 레이아웃을 사용합니다. S3에서 가져온 파일 크기가ImportedFileChunkSize보다 크면 스트라이프 수가(FileSize / ImportedFileChunksize) + 1인 여러 OST에 저장됩니다.ImportedFileChunkSize의 기본값은 1GiB입니다.
lfs getstripe 명령을 사용하여 파일 또는 디렉터리의 레이아웃 구성을 볼 수 있습니다.
lfs getstripepath/to/filename
이 명령은 파일의 스트라이프 수, 스트라이프 크기 및 스트라이프 오프셋을 보고합니다. 스트라이프 수는 파일이 스트라이핑된 OST 수입니다. 스트라이프 크기는 OST에 저장된 연속 데이터의 양입니다. 스트라이프 오프셋은 파일이 스트라이핑되는 첫 번째 OST의 인덱스입니다.
스트라이핑 구성 수정
파일의 레이아웃 파라미터는 파일이 처음 생성될 때 설정됩니다. lfs setstripe 명령을 사용하여 지정된 레이아웃에 비어 있는 새 파일을 생성합니다.
lfs setstripefilename--stripe-countnumber_of_OSTs
이 lfs setstripe 명령은 새 파일의 레이아웃에만 영향을 줍니다. 파일을 만들기 전에 이 명령을 사용하여 파일의 레이아웃을 지정할 수 있습니다. 디렉터리의 레이아웃을 정의할 수도 있습니다. 디렉터리에 설정된 레이아웃은 해당 디렉터리에 추가되는 모든 새 파일에 적용되지만 기존 파일에는 적용되지 않습니다. 새로 만드는 모든 하위 디렉터리도 새 레이아웃을 상속하며, 이 레이아웃은 해당 하위 디렉터리 내에 새로 만드는 모든 파일 또는 디렉터리에 적용됩니다.
기존 파일의 레이아웃을 수정하려면 lfs migrate 명령을 사용합니다. 이 명령은 필요에 따라 파일을 복사하여 명령에서 지정한 레이아웃에 따라 내용을 배포합니다. 예를 들어 파일을 추가하거나 크기를 늘려도 스트라이프 수는 변경되지 않으므로 파일을 마이그레이션하여 파일 레이아웃을 변경해야 합니다. 또는 lfs setstripe 명령을 사용하여 새 파일을 만들어 레이아웃을 지정하고 원본 내용을 새 파일에 복사한 다음 새 파일의 이름을 변경하여 원본 파일을 대체할 수 있습니다.
기본 레이아웃 구성이 워크로드에 최적화되지 않는 경우가 있을 수 있습니다. 예를 들어, 수십 개의 OST와 수 기가바이트의 파일이 있는 파일 시스템의 경우, 기본 스트라이프 수 값인 5개 OST를 초과하여 파일을 스트라이핑하면 성능이 향상될 수 있습니다. 스트라이프 수가 적은 대용량 파일을 만들면 I/O 성능 병목 현상이 발생할 수 있으며 OST가 가득 찰 수도 있습니다. 이 경우 이러한 파일에 대해 스트라이프 수가 더 많은 디렉터리를 만들 수 있습니다.
대용량 파일(특히 크기가 1GB보다 큰 파일)의 스트라이프 레이아웃을 설정하는 것은 다음과 같은 이유로 중요합니다.
대용량 파일을 읽고 쓸 때 여러 OST 및 관련 서버가 IOPS, 네트워크 대역폭 및 CPU 리소스를 제공할 수 있도록 하여 처리량을 개선합니다.
일부 OST가 전체 워크로드 성능을 제한하는 핫스팟이 될 가능성을 줄입니다.
대용량 파일 하나가 OST를 가득 채우지 못하여 디스크 전체 오류가 발생할 수 있는 문제를 방지합니다.
모든 사용 사례에 최적화된 단일 레이아웃 구성은 없습니다. 파일 레이아웃에 대한 자세한 지침은 Lustre.org 설명서의 파일 레이아웃(스트라이핑) 및 여유 공간 관리
스트라이프 레이아웃은 대용량 파일, 특히 파일 크기가 일반적으로 수백 메가바이트 이상인 사용 사례에서 가장 중요합니다. 이러한 이유로 새 파일 시스템의 기본 레이아웃에서는 크기가 1GiB를 초과하는 파일에 대해 스트라이프 수를 5개로 지정합니다.
스트라이프 수는 대용량 파일을 지원하는 시스템에 맞게 조정해야 하는 레이아웃 파라미터입니다. 스트라이프 수는 스트라이프 파일의 청크를 담을 OST 볼륨 수를 지정합니다. 예를 들어 스트라이프 수가 2이고 스트라이프 크기가 1MiB인 경우 Lustre는 파일의 1MiB 청크를 두 OST 각각에 대체 기록합니다.
유효 스트라이프 수는 실제 OST 볼륨 수와 지정한 스트라이프 수 값 중 적은 수입니다. 특수 스트라이프 수의
-1값을 사용하여 모든 OST 볼륨에 스트라이프를 배치하도록 지정할 수 있습니다.파일이 너무 작아서 모든 OST 볼륨의 공간을 차지할 수 없는 경우에도 특정 작업의 경우 Lustre가 레이아웃의 모든 OST로 네트워크 왕복을 해야 하기 때문에 작은 파일에 대해 큰 스트라이프 수를 설정하는 것은 최적이 아닙니다.
크기에 따라 파일 레이아웃을 변경할 수 있는 프로그레시브 파일 레이아웃(PFL)을 설정할 수 있습니다. PFL 구성을 사용하면 각 파일에 대해 구성을 명시적으로 설정할 필요 없이 크고 작은 파일이 조합된 파일 시스템을 간편하게 관리할 수 있습니다. 자세한 내용은 프로그레시브 파일 레이아웃 섹션을 참조하세요.
스트라이프 크기는 기본적으로 1MiB입니다. 스트라이프 오프셋 설정은 특별한 경우에 유용할 수 있지만 일반적으로 지정하지 않고 기본값을 사용하는 것이 가장 좋습니다.
프로그레시브 파일 레이아웃
디렉터리의 프로그레시브 파일 레이아웃(PFL) 구성을 지정하여 작은 파일과 큰 파일을 채우기 전에 각각 다른 스트라이프 구성을 지정할 수 있습니다. 예를 들어 새 파일 시스템에 데이터를 쓰기 전에 최상위 디렉터리에 PFL을 설정할 수 있습니다.
PFL 구성을 지정하려면 다음 명령과 같이 lfs setstripe 명령을 -E 옵션과 함께 사용하여 크기가 다른 파일의 레이아웃 구성 요소를 지정합니다.
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
이 명령은 네 가지 레이아웃 구성 요소를 설정합니다.
첫 번째 구성 요소(
-E 100M -c 1)는 최대 100MiB 크기의 파일에 대한 스트라이프 수 값 1을 나타냅니다.두 번째 구성 요소(
-E 10G -c 8)는 최대 10GiB 크기의 파일에 대한 스트라이프 수 8을 나타냅니다.세 번째 구성 요소(
-E 100G -c 16)는 최대 100GiB 크기의 파일에 대한 스트라이프 수가 16개임을 나타냅니다.네 번째 구성 요소(
-E -1 -c 32)는 100GiB보다 큰 파일의 스트라이프 수가 32개임을 나타냅니다.
중요
PFL 레이아웃으로 만든 파일에 데이터를 추가하면 해당 레이아웃 구성 요소가 모두 채워집니다. 예를 들어 위에 표시된 4가지 구성 요소 명령을 사용하여 1MiB 파일을 만든 다음 파일 끝에 데이터를 추가하면 파일의 레이아웃이 스트라이프 수 -1, 즉 시스템의 모든 OST를 포함하도록 확장됩니다. 이는 모든 OST에 데이터가 기록된다는 것을 의미하지는 않지만, 파일 길이 읽기와 같은 작업을 수행하면 모든 OST에 병렬로 요청이 전송되므로 파일 시스템에 상당한 네트워크 부하가 가중됩니다.
따라서 나중에 데이터가 추가될 수 있는 작거나 중간 길이의 파일에서는 스트라이프 수를 제한해야 한다는 점을 유의하세요. 일반적으로 새 레코드가 추가되면 로그 파일이 커지므로 Amazon FSx for Lustre는 상위 디렉터리에 지정된 기본 스트라이프 구성과 상관없이 추가 모드에서 생성되는 모든 파일에 기본 스트라이프 개수 1을 할당합니다.
2023년 8월 25일 이후에 생성된 Amazon FSx for Lustre 파일 시스템의 기본 PFL 구성은 다음 명령으로 설정됩니다.
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
중대형 파일에 대한 동시 액세스 빈도가 높은 워크로드를 사용하는 고객은 4개 구성 요소 예제 레이아웃에서 볼 수 있듯이 작은 크기에서 더 많은 스트라이프를 사용하고 가장 큰 파일은 모든 OST에 스트라이핑하는 레이아웃을 사용하는 것이 좋습니다.
성능 및 사용량 모니터링
Amazon FSx for Lustre는 1분마다 각 디스크(MDT 및 OST)에 대한 사용량 지표를 Amazon CloudWatch에 내보냅니다.
전체 파일 시스템 사용량 세부 정보를 보려면 각 지표의 합계 통계를 보면 됩니다. 예를 들어, DataReadBytes 통계 합계는 파일 시스템의 모든 OST에서 확인한 총 읽기 처리량을 보고합니다. 마찬가지로 FreeDataStorageCapacity 통계 합계는 파일 시스템의 파일 데이터에 사용할 수 있는 총 스토리지 용량을 보고합니다.
파일 시스템 성능 모니터링에 대한 자세한 내용은 Amazon FSx for Lustre 파일 시스템 모니터링 섹션을 참조하세요.
