스토리지 용량 관리
Amazon FSx for NetApp ONTAP은 파일 시스템의 스토리지 용량을 관리하는 데 사용할 수 있는 다양한 스토리지 관련 기능을 제공합니다.
FSx for ONTAP 스토리지 계층
스토리지 계층은 Amazon FSx for NetApp ONTAP 파일 시스템에 대한 물리적 스토리지 미디어입니다. FSx for ONTAP은 다음과 같은 스토리지 계층을 제공합니다.
SSD 계층 - 데이터 세트의 활성 부분을 위해 특별히 구축된 사용자 프로비저닝 고성능 솔리드 스테이트 드라이브(SSD) 스토리지입니다.
용량 풀 계층 - 자동으로 페타바이트까지 확장할 수 있고 자주 액세스하지 않는 데이터에 맞게 비용을 최적화하는 완전히 탄력적인 스토리지입니다.
FSx for ONTAP 볼륨은 폴더와 마찬가지로 스토리지 용량을 사용하지 않는 가상 리소스입니다. 저장되어 물리적 스토리지를 사용하는 데이터는 볼륨 내에 있습니다. 볼륨을 생성할 때 크기를 지정하며, 볼륨을 만든 후에 크기를 수정할 수 있습니다. FSx for ONTAP 볼륨은 씬 프로비저닝되며 파일 시스템 스토리지는 미리 예약되지 않습니다. 대신 필요에 따라 SSD 및 용량 풀 스토리지가 동적으로 할당됩니다. 볼륨 수준에서 구성하는 계층화 정책은 SSD 계층에 저장된 데이터가 용량 풀 계층으로 전환되는지 여부 및 시기를 결정합니다.
다음 다이어그램에서는 파일 시스템의 여러 FSx for ONTAP 볼륨에 배치된 데이터의 예제를 보여줍니다.
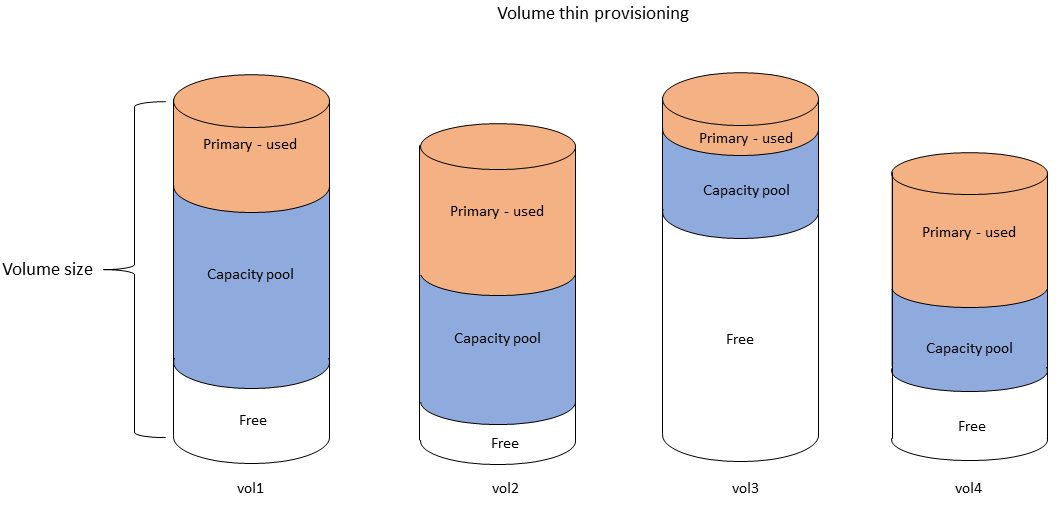
다음 다이어그램에서는 이전 다이어그램의 4개 볼륨에 있는 데이터가 파일 시스템의 물리적 스토리지 용량을 어떻게 사용하는지 보여줍니다.
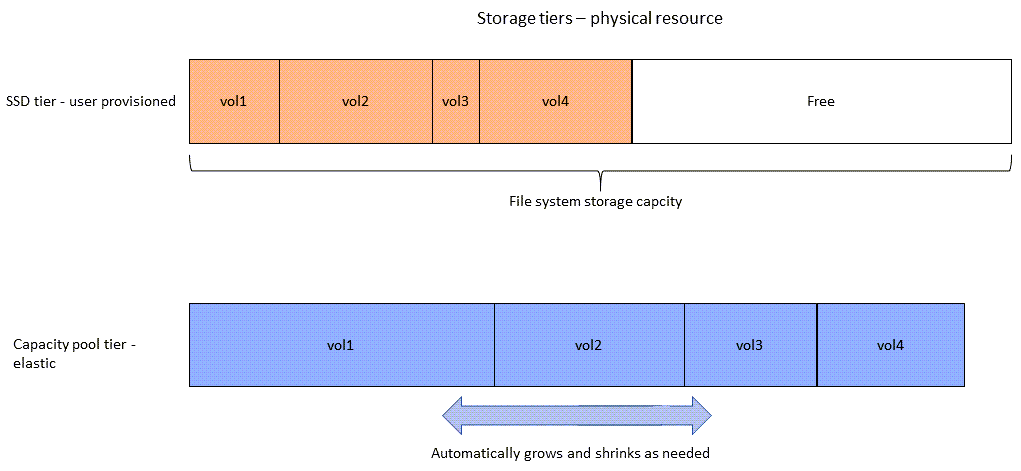
파일 시스템의 각 볼륨 요구 사항을 가장 잘 충족하는 계층화 정책을 선택하면 스토리지 비용을 줄일 수 있습니다. 자세한 내용은 볼륨 데이터 계층화 섹션을 참조하세요.
적절한 양의 파일 시스템 SSD 스토리지 선택하기
FSx for ONTAP 파일 시스템의 SSD 스토리지 용량을 선택할 때는 데이터를 저장하는 데 사용할 수 있는 SSD 스토리지의 양에 영향을 미치는 다음 항목을 염두에 두어야 합니다.
NetApp ONTAP 소프트웨어 오버헤드를 위해 예약된 스토리지 용량.
파일 메타데이터
최근에 작성된 데이터
휴지 기간에 도달하지 않은 데이터이든, 최근에 읽은 데이터를 SSD로 다시 검색했든 상관없이 SSD 스토리지에 저장하려는 파일.
SSD 스토리지 사용 방식
파일 시스템의 SSD 스토리지는 NetApp ONTAP 소프트웨어(오버헤드), 파일 메타데이터 및 데이터의 조합에 사용됩니다.
NetApp ONTAP 소프트웨어 오버헤드
다른 NetApp ONTAP 파일 시스템과 마찬가지로, 파일 시스템의 SSD 스토리지 용량의 최대 16%는 ONTAP 오버헤드용으로 예약되어 있으므로 파일을 저장하는 데 사용할 수 없습니다. ONTAP 오버헤드는 다음과 같이 할당됩니다.
11%는 NetApp ONTAP 소프트웨어용으로 예약되어 있습니다. SSD 저장 용량이 30TB(테비바이트)를 초과하는 파일 시스템의 경우 6%가 예약되어 있습니다.
5%는 두 파일 시스템의 파일 서버 간에 데이터를 동기화하는 데 필요한 집계 스냅샷에만 사용됩니다.
파일 메타데이터
파일 메타데이터는 일반적으로 파일이 사용하는 스토리지 용량의 3~7%를 차지합니다. 이 비율은 평균 파일 크기(평균 파일 크기가 작을수록 메타데이터가 더 많이 필요함) 및 파일에서 달성한 스토리지 효율성 절감량에 따라 달라집니다. 파일 메타데이터는 스토리지 효율성 절감의 혜택을 받지 못한다는 점에 유의하세요. 다음 지침을 사용하여 파일 시스템의 메타데이터에 사용되는 SSD 스토리지의 양을 추정할 수 있습니다.
| 평균 파일 크기 | 메타데이터 크기(파일 데이터의 백분율) |
|---|---|
|
4KB |
7% |
|
8KB |
3.5% |
|
32KB 이상 |
1-3% |
용량 풀 계층에 저장하려는 파일의 메타데이터에 필요한 SSD 스토리지 용량의 크기를 조정할 때는 용량 풀 계층에 저장하려는 데이터 10GiB당 SSD 스토리지 1GiB의 보수적인 비율을 사용하는 것이 좋습니다.
SSD 계층에 저장된 파일 데이터
활성 데이터 세트와 모든 파일 메타데이터 외에도 파일 시스템에 기록된 모든 데이터는 처음에 SSD 계층에 기록된 후 용량 풀 스토리지 계층으로 이동됩니다. 이는 SnapMirror를 사용하여 모든 데이터 계층화 정책으로 구성된 볼륨으로 데이터를 전송하는 경우를 제외하고는 볼륨의 계층화 정책과 상관없이 적용됩니다.
용량 풀 계층의 임의 읽기는 SSD 계층의 사용률이 90% 미만인 한 SSD 계층에 캐시됩니다. 자세한 내용은 볼륨 데이터 계층화 단원을 참조하십시오.
권장 SSD 용량 사용률
SSD 스토리지 계층의 사용률은 지속적으로 80%를 초과하지 않는 것이 좋습니다. 2세대 파일 시스템의 경우, 파일 시스템의 집계 사용률이 지속적으로 80%를 초과하지 않도록 하는 것이 좋습니다. 이러한 권장 사항은 ONTAP에 대한 NetApp의 권장 사항과 일치합니다. 파일 시스템의 SSD 계층은 용량 풀 계층에 대한 스테이징 쓰기 및 용량 풀 계층에서의 임의 읽기에도 사용되므로 액세스 패턴이 갑자기 변경되면 SSD 계층의 사용률이 빠르게 증가할 수 있습니다.
SSD 사용률이 90%이면 용량 풀 계층에서 읽은 데이터가 더 이상 SSD 계층에 캐시되지 않으므로 파일 시스템에 기록되는 새 데이터를 위해 남은 SSD 용량이 보존됩니다. 이로 인해 SSD 계층에서 캐시하여 읽는(파일 시스템의 처리량 용량에 영향을 미칠 수 있음) 대신 용량 풀 계층에서 동일한 데이터를 반복적으로 읽어 용량 풀 스토리지에서 읽을 수 있습니다.
SSD 계층 사용률이 98% 이상이면 모든 계층화 기능이 중지됩니다. 자세한 내용은 계층화 임계값 단원을 참조하십시오.
스토리지 효율성
NetApp ONTAP는 압축, 압축 및 중복 제거를 포함하는 볼륨 수준에서 블록 수준 스토리지 효율성 기능을 제공합니다. 2세대 파일 시스템의 경우, 파일 시스템의 집계 사용률이 지속적으로 80%를 초과하지 않도록 하는 것이 좋습니다. 볼륨 단위로 스토리지 효율성을 활성화할 수 있습니다. 이러한 기능을 사용하면 데이터가 차지하는 스토리지 용량을 줄여 SSD, 용량 풀, 백업 스토리지의 저장 공간을 더 적게 사용할 수 있습니다. SSD 스토리지의 데이터에 대해 각 볼륨에서 압축 및 중복 제거를 활성화할 수 있습니다. 데이터를 용량 풀 스토리지로 계층화하면 SSD 스토리지의 압축 및 중복 제거를 통해 절약되는 스토리지가 보존됩니다. 파일 시스템의 스토리지 효율성 구성에 관계없이 백업 데이터에 대해 항상 스토리지 효율성이 활성화됩니다.
다음 표는 일반적인 스토리지 절약의 예를 보여줍니다.
| 압축 전용 | 중복 제거 전용 | 압축 & 중복 제거 | |
|---|---|---|---|
| 범용 파일 공유 | 50% | 30% | 65% |
| 가상 서버 & 데스크톱 | 55% | 70% | 70% |
| 데이터베이스 수 | 65-70% | 0% | 65-70% |
| 데이터 엔지니어링 | 55% | 30% | 75% |
| 지질 데이터 | 40% | 3% | 40% |
대부분의 워크로드에서 압축 및 중복 제거를 활성화해도 파일 시스템 성능에 부정적인 영향을 미치지 않습니다. 대부분의 워크로드에서 압축은 전반적인 성능을 향상시킵니다. RAM 캐시에서 빠른 읽기 및 쓰기를 제공하기 위해 ONTAP용 FSx 파일 서버는 파일 서버와 스토리지 디스크 간에 사용할 수 있는 것보다 프런트엔드 네트워크 인터페이스 카드(NICs)에 더 높은 수준의 네트워크 대역폭을 갖추고 있습니다. 데이터 압축은 파일 서버와 스토리지 디스크 간에 전송되는 데이터의 양을 줄이므로 대부분의 워크로드에서 데이터 압축을 사용하면 전체 파일 시스템 처리 용량이 증가하는 것을 볼 수 있습니다. 데이터 압축과 관련된 처리량 용량 증가는 파일 시스템의 프런트엔드 NIC가 포화 상태가 되면 제한됩니다.
NetApp ONTAP용 Amazon FSx은 스냅샷, 씬 프로비저닝 및 FlexClone 볼륨을 포함하여 공간을 절약하는 다른 ONTAP 기능도 지원합니다.
스토리지 효율성 기능은 기본적으로 활성화되어 있지 않습니다. 다음과 같이 활성화할 수 있습니다.
파일 시스템을 생성할 때 SVM의 루트 볼륨에서.
새 볼륨을 생성할 때.
기존 볼륨을 수정할 때.
스토리지 효율성이 활성화된 파일 시스템의 스토리지 절감액을 보려면 스토리지 효율성 절감 모니터링을 참조하세요.
스토리지 효율성 절감액 계산
압축, 중복 제거, 압축, 스냅샷 및 FlexClones로 인한 스토리지 절감 효과를 계산하기 위해 LogicalDataStored 및 StorageUsed ONTAP CloudWatch용 FSx 파일 시스템 지표를 사용할 수 있습니다. 이러한 지표에는 단일 측정기준인 FileSystemId가 포함되어 있습니다. 자세한 내용은 파일 시스템 지표 단원을 참조하십시오.
스토리지 효율성 절감 효과를 바이트 단위로 계산하려면 지정된 기간 동안의
StorageUsed평균을 구하고 거기에서 동일한 기간 동안의LogicalDataStored평균을 뺍니다.스토리지 효율성 절감 효과를 총 논리적 데이터 크기의 백분율로 계산하려면 지정된 기간 동안의
StorageUsed의Average를 구하고 거기에서 동일한 기간 동안의LogicalDataStored의Average를 뺍니다. 그런 다음 그 차이를 동일한 기간 동안의LogicalDataStored의Average로 나눕니다.
SSD 크기 조정 예제
데이터의 80%가 자주 액세스되지 않는 애플리케이션을 위해 100TiB의 데이터를 저장한다고 가정해 보겠습니다. 이 시나리오에서는 데이터의 80%(80TB)가 용량 풀 계층으로 자동 계층화되고 나머지 20%(20TB)는 SSD 스토리지에 남습니다. 범용 파일 공유 워크로드의 일반적인 스토리지 효율성 절감 효과인 65%를 기준으로 하면, 이는 7TiB의 데이터에 해당합니다. 80%의 SSD 사용률을 유지하려면 활발하게 액세스하는 20TiB의 데이터에 대해 8.75TiB의 SSD 스토리지 용량이 필요합니다. 다음 계산에서 볼 수 있듯이 프로비저닝하는 SSD 스토리지의 양에는 ONTAP 소프트웨어 스토리지 오버헤드 16%도 고려해야 합니다.
ssdNeeded = ssdProvisioned * (1 - 0.16) 8.75 TiB / 0.84 = ssdProvisioned 10.42 TiB = ssdProvisioned
따라서 이 예제에서는 최소 10.42TiB의 SSD 스토리지를 프로비저닝해야 합니다. 또한 자주 액세스하지 않는 나머지 80TiB의 데이터에는 28TiB의 용량 풀 스토리지를 사용하게 됩니다.
