AWS Glue 관찰성 메트릭을 사용한 모니터링
참고
AWS Glue 관찰성 지표는 AWS Glue 4.0 이상 버전에서 사용할 수 있습니다.
AWS Glue 관찰성 메트릭을 사용하면 Apache Spark의 AWS Glue 내부에서 일어나는 일에 대한 통찰력을 얻어 문제의 분류 및 분석을 개선할 수 있습니다. 관찰성 지표는 Amazon CloudWatch 대시보드를 통해 시각화되며 오류의 근본 원인 분석을 수행하고 성능 병목 현상을 진단하는 데 사용할 수 있습니다. 대규모 문제 디버깅에 소요되는 시간을 줄여 문제를 더 빠르고 효과적으로 해결하는 데 집중할 수 있습니다.
AWS Glue 관찰성은 다음 네 그룹으로 분류된 Amazon CloudWatch 메트릭을 제공합니다.
-
신뢰성(예: 오류 클래스) - 주어진 시간 범위에서 해결해야 할 가장 일반적인 장애 원인을 쉽게 식별할 수 있습니다.
-
성능(예: Skewness) - 성능 병목 지점을 식별하고 조정 기법을 적용합니다. 예를 들어 작업 왜곡으로 인해 성능이 저하되는 경우 Spark Adaptive Query Execution을 활성화하고 스큐 조인 임곗값을 미세 조정하는 것이 좋습니다.
-
처리량(예: 소스/싱크당 처리량) - 데이터 읽기 및 쓰기 추세를 모니터링합니다. 또한 이상 현상에 대한 Amazon CloudWatch 경보를 구성할 수 있습니다.
-
리소스 사용률(예: 작업자, 메모리 및 디스크 사용률) - 용량 사용률이 낮은 작업을 효율적으로 찾을 수 있습니다. 이러한 작업에 대해 AWS Glue Auto Scaling을 활성화할 수 있습니다.
AWS Glue 관찰성 메트릭 시작하기
참고
새로운 지표는 AWS Glue Studio 콘솔에서 기본적으로 활성화됩니다.
AWS Glue Studio에서 관찰성 지표를 구성하려면 다음을 수행합니다.
-
AWS Glue 콘솔에 로그인하고 콘솔 메뉴에서 ETL 작업을 선택합니다.
-
내 작업 섹션에서 작업 이름을 클릭하여 작업을 선택합니다.
-
[작업 세부 정보(Job details)] 탭을 선택합니다.
-
하단으로 스크롤하여 고급 속성을 선택한 다음 작업 관찰성 지표를 선택합니다.
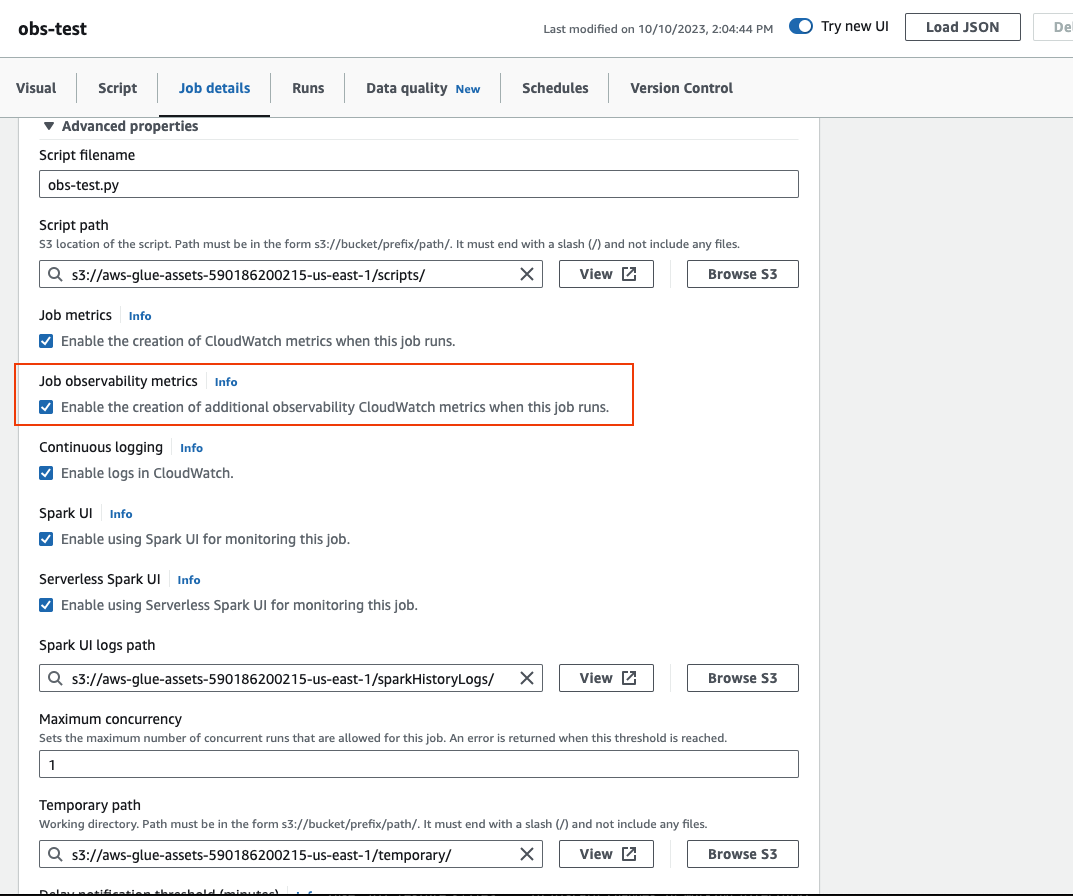
AWS CLI를 사용하여 AWS Glue 관찰성 지표를 활성화하려면 다음을 수행합니다.
-
입력
--default-argumentsJSON 파일의 다음 키-값을 맵에 추가합니다.--enable-observability-metrics, true
AWS Glue 관찰성 사용
AWS Glue 관찰성 지표는 Amazon CloudWatch를 통해 제공되므로 Amazon CloudWatch 콘솔, AWS CLI, SDK 또는 API를 사용하여 관찰성 지표 데이터 포인트를 쿼리할 수 있습니다. AWS Glue 관찰성 지표를 사용하는 사용 사례의 예는 Using Glue Observability for monitoring resource utilization to reduce cost
Amazon CloudWatch 콘솔에서 AWS Glue 관찰성 사용
Amazon CloudWatch 콘솔에서 메트릭을 쿼리하고 시각화는 방법:
-
Amazon CloudWatch 콘솔을 열고 모든 지표를 선택합니다.
-
사용자 지정 네임스페이스에서 AWS Glue를 선택합니다.
-
작업 관찰성 지표, 소스별 관찰 가능성 지표 또는 싱크당 관찰 가능성 지표를 선택합니다.
-
특정 지표 이름, 작업 이름, 작업 실행 ID를 검색하고 선택합니다.
-
그래프로 표시된 지표 탭에서 원하는 통계, 기간 및 기타 옵션을 구성합니다.
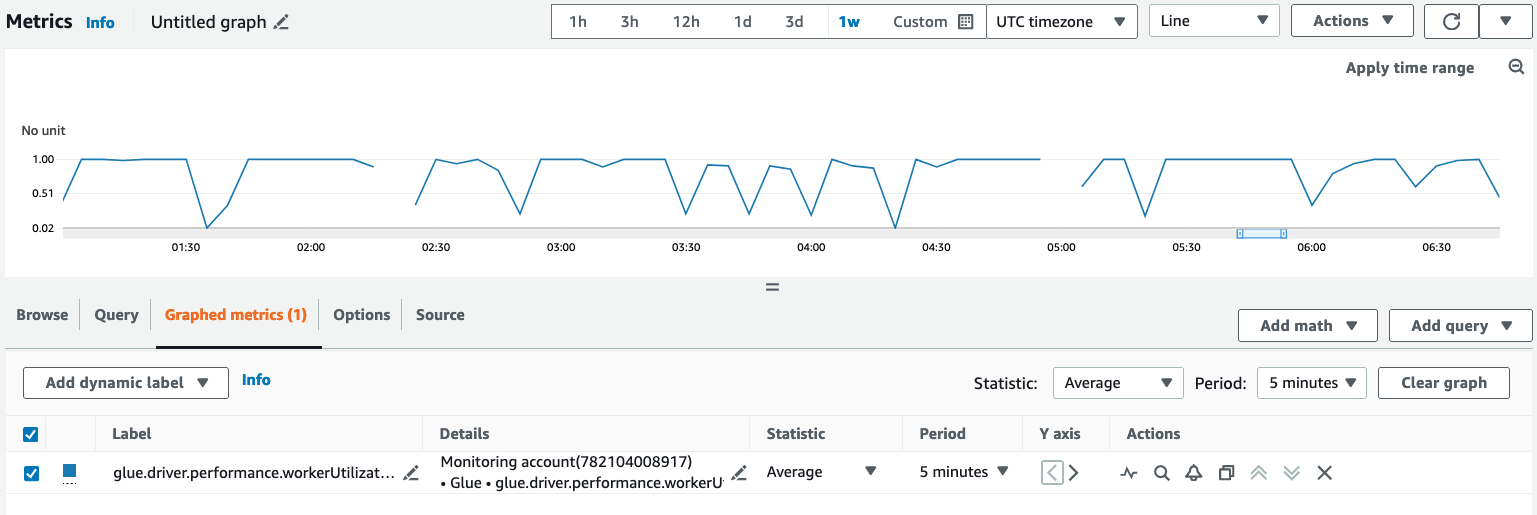
AWS CLI를 사용하여 관찰성 지표를 쿼리하려면 다음을 수행합니다.
-
지표 정의 JSON 파일을 생성하고
your-Glue-job-name및your-Glue-job-run-id를 변경합니다.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
get-metric-data명령 실행:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
관찰성 메트릭
AWS Glue 관찰성은 다음 지표의 프로필을 작성하고 30초마다 Amazon CloudWatch로 전송하며, 이러한 지표 중 일부는 AWS Glue Studio 작업 실행 모니터링 페이지에서 확인할 수 있습니다.
| 지표 | 설명 | 범주 |
|---|---|---|
| glue.driver.skewness.stage |
지표 범주: job_performance Spark 스테이지 실행 왜도: 이 지표는 입력 데이터 왜도 또는 변환(예: 왜곡된 조인)으로 인해 발생할 수 있는 실행 왜도를 캡처합니다. 이 지표의 값은 [0, 무한] 범위에 속합니다. 여기서 0은 스테이지의 모든 작업 중 최대 작업 실행 시간과 중간 작업 실행 시간의 비율이 특정 스테이지 왜도 인자보다 작다는 것을 의미합니다. 기본 스테이지 왜도 인자는 `5`이며 spark conf: spark.metrics.conf.driver.source.glue.jobPerformance.skewnessFactor를 통해 덮어쓸 수 있습니다. 스테이지 왜도 값이 1이면 비율이 단계 왜도 인자의 두 배임을 의미합니다. 스테이지 왜도 값은 현재 왜도를 반영하여 30초마다 업데이트됩니다. 스테이지가 끝날 때의 값은 최종 스테이지 왜도를 반영합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(Job_Performance) 유효 통계: 평균, 최대, 최소, 백분위수 단위: 수 |
job_performance |
| glue.driver.skewness.job |
지표 범주: job_performance 작업 왜도는 작업 스테이지 왜도의 가중치 평균입니다. 가중치 평균은 실행하는 데 시간이 오래 걸리는 스테이지에 더 많은 가중치를 부여합니다. 이는 매우 왜곡된 스테이지가 실제로 다른 스테이지에 비해 매우 짧은 시간 동안 실행되는 경우를 피하기 위한 것입니다. 따라서 왜도는 전체 작업 성능에 있어 중요하지 않으며 왜도를 해결하려고 노력할 필요가 없습니다. 이 지표는 각 단계가 완료될 때마다 업데이트되므로 마지막 값은 실제 전체 작업 왜도를 반영합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(Job_Performance) 유효 통계: 평균, 최대, 최소, 백분위수 단위: 수 |
job_performance |
| glue.succeed.ALL |
지표 범주: 오류 실패 범주의 그림을 완성하기 위한 총 작업 실행 성공 횟수 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(개수), ObservabilityGroup(오류) 유효 통계: SUM 단위: 수 |
error |
| glue.error.ALL |
지표 범주: 오류 실패 범주의 그림을 완성하기 위한 총 작업 실행 오류 횟수 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(개수), ObservabilityGroup(오류) 유효 통계: SUM 단위: 수 |
error |
| glue.error.[error category] |
지표 범주: 오류 이것은 실제로 작업 실행이 실패할 때만 업데이트되는 지표 세트입니다. 오류 분류는 분류 및 디버깅에 도움이 됩니다. 작업 실행이 실패하면 실패의 원인이 되는 오류가 분류되고 해당 오류 범주 지표가 1로 설정됩니다. 이를 통해 시간 경과에 따른 오류 분석은 물론 모든 작업에 대한 오류 분석을 수행하여 가장 일반적인 오류 범주를 식별하고 문제 해결을 시작할 수 있습니다. AWS Glue에는 OUT_OF_MEMORY(드라이버 및 실행기), PERMISSION, SYNTAX 및 THROTTLING 오류 범주를 포함한 28개의 오류 범주가 있습니다. 오류 범주는 COMPILATION, LAUNCH, TIMEOUT 오류 범주도 포함합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(개수), ObservabilityGroup(오류) 유효 통계: SUM 단위: 수 |
error |
| glue.driver.workerUtilization |
지표 범주: resource_utilization 할당된 작업자 중 실제로 사용된 작업자의 비율입니다. 상황이 좋지 않다면 Auto Scaling이 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) 유효 통계: 평균, 최대, 최소, 백분위수 단위: 퍼센트 |
resource_utilization |
| glue.driver.memory.heap.[available | used] |
지표 범주: resource_utilization 작업 실행 중 드라이버의 사용 가능/사용된 힙 메모리입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
지표 범주: resource_utilization 작업 실행 중 드라이버가 사용한 힙 메모리(%)입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.driver.memory.non-heap.[available | used] |
지표 범주: resource_utilization 작업 실행 중 드라이버가 사용 가능한 또는 사용한 힙이 아닌 메모리입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
지표 범주: resource_utilization 작업 실행 중 드라이버가 사용한 힙이 아닌 메모리(%)입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.driver.memory.total.[available | used] |
지표 범주: resource_utilization 작업 실행 중 드라이버가 사용 가능한 또는 사용한 총 메모리입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.driver.memory.total.used.percentage |
지표 범주: resource_utilization 작업 실행 중 드라이버가 사용한 총 메모리(%)입니다. 이는 특히 시간 경과에 따른 메모리 사용량 추세를 파악하는 데 도움이 되며 메모리 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.ALL.memory.heap.[available | used] |
지표 범주: resource_utilization 실행기의 사용 가능한/사용된 힙 메모리입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
지표 범주: resource_utilization 실행기가 사용한 힙 메모리(%)입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.ALL.memory.non-heap.[available | used] |
지표 범주: resource_utilization 실행기의 사용 가능한/사용된 힙이 아닌 메모리입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
지표 범주: resource_utilization 실행기가 사용한 힙이 아닌 메모리(%)입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.ALL.memory.total.[available | used] |
지표 범주: resource_utilization 실행기의 사용 가능한/사용된 총 메모리입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 바이트 |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
지표 범주: resource_utilization 실행기의 총 메모리 사용률(%)입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
지표 범주: resource_utilization 작업 실행 중 드라이버의 사용 가능한/사용된 디스크 공간입니다. 이는 특히 시간 경과에 따른 디스크 사용량 추세를 파악하는 데 도움이 되며 디스크 공간 부족 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 기가바이트 |
resource_utilization |
| glue.driver.disk.used.percentage] |
지표 범주: resource_utilization 작업 실행 중 드라이버의 사용 가능한/사용된 디스크 공간입니다. 이는 특히 시간 경과에 따른 디스크 사용량 추세를 파악하는 데 도움이 되며 디스크 공간 부족 관련 오류를 디버깅할 뿐만 아니라 잠재적인 오류를 방지하는 데도 도움이 될 수 있습니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.ALL.disk.[available_GB | used_GB] |
지표 범주: resource_utilization 실행기의 사용 가능한/사용된 디스크 공간입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 기가바이트 |
resource_utilization |
| glue.ALL.disk.used.percentage |
지표 범주: resource_utilization 실행기의 사용 가능한/사용된/사용된(%) 디스크 공간입니다. ALL은 모든 실행기를 의미합니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization) Valid Statistics: Average 단위: 퍼센트 |
resource_utilization |
| glue.driver.bytesRead |
지표 범주: 처리량 이 작업 실행에서 입력 소스당 및 모든 소스에 대해 읽은 바이트 수입니다. 이를 통해 데이터양과 시간 경과에 따른 변화를 파악할 수 있으므로 데이터 왜도와 같은 문제를 해결하는 데 도움이 됩니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization), Source(소스 데이터 위치) Valid Statistics: Average 단위: 바이트 |
처리량 |
| glue.driver.[recordsRead | filesRead] |
지표 범주: 처리량 이 작업 실행에서 입력 소스당 및 모든 소스에 대해 읽은 레코드/파일 수입니다. 이를 통해 데이터양과 시간 경과에 따른 변화를 파악할 수 있으므로 데이터 왜도와 같은 문제를 해결하는 데 도움이 됩니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization), Source(소스 데이터 위치) Valid Statistics: Average 단위: 수 |
처리량 |
| glue.driver.partitionsRead |
지표 범주: 처리량 이 작업 실행에서 Amazon S3 입력 소스당 및 모든 소스에 대해 읽은 파티션 수입니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization), Source(소스 데이터 위치) Valid Statistics: Average 단위: 수 |
처리량 |
| glue.driver.bytesWrittten |
지표 범주: 처리량 이 작업 실행에서 출력 싱크당 및 모든 싱크에 대해 작성된 바이트 수입니다. 이를 통해 데이터양과 시간이 지남에 따라 어떻게 변화하는지 파악할 수 있으므로 처리 왜도와 같은 문제를 해결하는 데 도움이 됩니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization), Sink(싱크 데이터 위치) Valid Statistics: Average 단위: 바이트 |
처리량 |
| glue.driver.[recordsWritten | filesWritten] |
지표 범주: 처리량 이 작업 실행에서 출력 싱크당 및 모든 싱크에 대해 작성된 레코드/파일 수입니다. 이를 통해 데이터양과 시간이 지남에 따라 어떻게 변화하는지 파악할 수 있으므로 처리 왜도와 같은 문제를 해결하는 데 도움이 됩니다. 유효 차원: JobName(AWS Glue 작업 이름), JobRunId(JobRun ID 또는 ALL), Type(게이지), ObservabilityGroup(resource_utilization), Sink(싱크 데이터 위치) Valid Statistics: Average 단위: 수 |
처리량 |
오류 범주
| 오류 범주 | 설명 |
|---|---|
| COMPILATION_ERROR | Scala 코드를 컴파일하는 동안 오류가 발생합니다. |
| CONNECTION_ERROR | 서비스/원격 호스트/데이터베이스 서비스 등에 연결하는 동안 오류가 발생합니다. |
| DISK_NO_SPACE_ERROR |
드라이버/실행기의 디스크에 공간이 남아 있지 않은 경우 오류가 발생합니다. |
| OUT_OF_MEMORY_ERROR | 드라이버/실행기의 메모리에 공간이 남아 있지 않은 경우 오류가 발생합니다. |
| IMPORT_ERROR | 종속성을 가져올 때 오류가 발생합니다. |
| INVALID_ARGUMENT_ERROR | 입력 인수가 유효하지 않거나 잘못된 경우 오류가 발생합니다. |
| PERMISSION_ERROR | 서비스, 데이터 등에 대한 권한이 없는 경우 오류가 발생합니다. |
| RESOURCE_NOT_FOUND_ERROR |
데이터, 위치 등이 종료되지 않을 경우 오류가 발생합니다. |
| QUERY_ERROR | Spark SQL 쿼리 실행으로 인해 오류가 발생합니다. |
| SYNTAX_ERROR | 스크립트에 구문 오류가 있는 경우 오류가 발생합니다. |
| THROTTLING_ERROR | 서비스 동시성 한도에 도달하거나 서비스 할당량 한도를 초과하는 경우 오류가 발생합니다. |
| DATA_LAKE_FRAMEWORK_ERROR | Hudi, Iceberg 등과 같은 AWS Glue 기본 지원 데이터 레이크 프레임워크에서 오류가 발생합니다. |
| UNSUPPORTED_OPERATION_ERROR | 지원되지 않는 작업을 수행하는 경우 오류가 발생합니다. |
| RESOURCES_ALREADY_EXISTS_ERROR | 생성하거나 추가하려는 리소스가 이미 존재하는 경우 오류가 발생합니다. |
| GLUE_INTERNAL_SERVICE_ERROR | AWS Glue 내부 서비스 문제가 있는 경우 오류가 발생합니다. |
| GLUE_OPERATION_TIMEOUT_ERROR | AWS Glue 작업 시간이 초과되는 경우 오류가 발생합니다. |
| GLUE_VALIDATION_ERROR | AWS Glue 작업에 필요한 값을 검증할 수 없는 경우 오류가 발생합니다. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | 동일한 소스 버킷에서 동일한 작업이 실행되고 동일한/다른 대상에 동시에 작성되는 경우 오류가 발생합니다(동시성 > 1). |
| LAUNCH_ERROR | AWS Glue 작업 시작 단계에서 오류가 발생합니다. |
| DYNAMODB_ERROR | Amazon DynamoDB 서비스에서 일반 오류가 발생합니다. |
| GLUE_ERROR | AWS Glue 서비스에서 일반 오류가 발생합니다. |
| LAKEFORMATION_ERROR | AWS Lake Formation 서비스에서 일반 오류가 발생합니다. |
| REDSHIFT_ERROR | Amazon Redshift 서비스에서 일반 오류가 발생합니다. |
| S3_ERROR | Amazon S3 서비스에서 일반 오류가 발생합니다. |
| SYSTEM_EXIT_ERROR | 일반 시스템 종료 오류입니다. |
| TIMEOUT_ERROR | 작업 시간 초과로 인해 작업이 실패하면 일반 오류가 발생합니다. |
| UNCLASSIFIED_SPARK_ERROR | Spark에서 일반 오류가 발생합니다. |
| UNCLASSIFIED_ERROR | 기본 오류 범주입니다. |
제한 사항
참고
glueContext를 초기화해야만 지표를 게시할 수 있습니다.
소스 차원에서 값은 소스 유형에 따라 Amazon S3 경로 또는 테이블 이름입니다. 또한 소스가 JDBC이고 쿼리 옵션이 사용되는 경우 쿼리 문자열은 소스 차원에 설정됩니다. 값이 500자보다 길면 500자 이내로 잘립니다. 다음은 값의 제한 사항입니다.
-
ASCII가 아닌 문자는 제거됩니다.
소스 이름에 ASCII 문자가 포함되어 있지 않으면 <비 ASCII 입력>으로 변환됩니다.
처리량 지표의 제한 사항 및 고려 사항
-
DataFrame 및 DataFrame 기반 DynamicFrame(예: JDBC, Amazon S3의 Parquet에서 읽기)은 지원되지만 RDD 기반 DynamicFrame(예: Amazon S3에서 csv, json 읽기 등)은 지원되지 않습니다. 기술적으로는 Spark UI에 표시되는 모든 읽기 및 쓰기가 지원됩니다.
-
데이터 소스가 카탈로그 테이블이고 형식이 JSON, CSV, 텍스트 또는 Iceberg인 경우
recordsRead지표가 내보내집니다. -
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWritten,glue.driver.throughput.filesWritten지표는 JDBC 및 Iceberg 테이블에서 사용할 수 없습니다. -
지표가 지연될 수 있습니다. 작업이 약 1분 안에 완료되면 Amazon CloudWatch 지표에 처리량 지표가 표시되지 않을 수 있습니다.
