기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
처리 균형 자동 조절 변환을 사용하여 런타임 최적화
처리 균형 자동 조절 변환은 더 나은 성능을 위해 작업자 사이에서 데이터를 재배포합니다. 이는 데이터가 불균형하거나 소스에서 가져온 데이터로 인해 충분한 병렬 처리가 불가능한 경우에 유용합니다. 소스가 gzip으로 압축되었거나 JDBC인 경우에 이러한 상황이 흔히 나타납니다. 데이터 재배포에도 어느 정도의 성능 비용이 발생하므로, 데이터의 균형이 이미 조절된 상태인 경우 최적화해도 보상 효과를 얻지 못할 수도 있습니다. 이 변환은 Apache Spark 재파티셔닝을 사용하여 클러스터 용량에 최적화된 여러 파티션 사이에서 데이터를 임의로 재할당합니다. 고급 사용자의 경우 여러 파티션을 수동으로 입력할 수 있습니다. 또한 지정된 열을 기준으로 데이터를 재구성하여 파티셔닝된 테이블의 쓰기를 최적화하는 데 사용할 수 있습니다. 그러면 출력 파일의 통합 기능이 더욱 강화됩니다.
-
리소스 패널을 열고 처리 균형 자동 조절을 선택하여 작업 다이어그램에 새 변환을 추가합니다. 노드를 추가할 때 선택한 노드가 상위 노드가 됩니다.
-
(선택 사항) 노드 속성 탭에서 작업 다이어그램에 노드 이름을 입력할 수 있습니다. 노드 상위 항목이 아직 선택되지 않은 경우 [노드 상위 항목(Node parents)] 목록에서 변환의 입력 소스로 사용할 노드를 선택합니다.
-
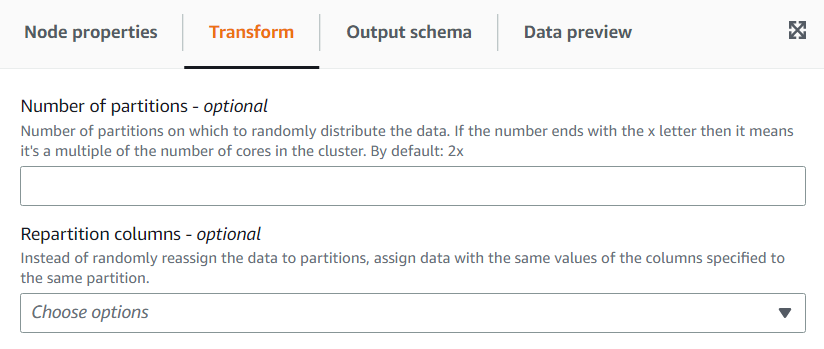
(선택 사항) 변환 탭에서 파티션 수를 입력할 수 있습니다. 일반적으로 이 값은 시스템에서 결정하도록 하는 것이 좋지만, 이 값을 제어해야 하는 경우 승수를 조정하거나 특정 값을 입력할 수 있습니다. 열을 기준으로 파티셔닝된 데이터를 저장하려는 경우 리파티션 열과 동일한 열을 선택할 수 있습니다. 이렇게 하면 각 파티션에서 파일 수를 최소화하고 파티션당 파일 수가 많아지지 않도록 방지할 수 있습니다. 파일 수가 많아지면 해당 데이터를 쿼리하는 도구의 성능이 저하될 수 있습니다.