신중한 고려 후 Amazon Kinesis Data Analytics for SQL 애플리케이션을 중단하기로 결정했습니다.
1. 2025년 9월 1일부터 Amazon Kinesis Data Analytics for SQL 애플리케이션에 대한 버그 수정은 제공되지 않습니다. 곧 중단될 예정이므로 지원이 제한될 예정이기 때문입니다.
2. 2025년 10월 15일부터 새 Kinesis Data Analytics for SQL 애플리케이션을 생성할 수 없습니다.
3. 2026년 1월 27일부터 애플리케이션이 삭제됩니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 시작하거나 작동할 수 없게 됩니다. 그 시점부터 Amazon Kinesis Data Analytics for SQL에 대한 지원을 더 이상 이용할 수 없습니다. 자세한 내용은 Amazon Kinesis Data Analytics for SQL 애플리케이션 단종 단원을 참조하십시오.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
예: 쿼리에서 부분적 결과 집계
Amazon Kinesis 데이터 스트림에 처리 시간이 정확히 일치하지 않는 이벤트 시간이 있는 레코드가 포함되어 있는 경우, 텀블링 윈도의 결과 선택에는 창에 도착했다고 되어 잇지만 실제로는 그렇지 아니한 레코드가 포함됩니다. 이 경우 텀블링 윈도우에는 원하는 결과의 일부분만 포함됩니다. 이 문제를 해결하려면 다음과 같은 여러 가지 접근 방식을 사용할 수 있습니다.
-
텀블링 윈도우만 사용하고, upsert를 사용하여 데이터베이스 또는 데이터 웨어하우스를 통한 사후 처리에서 부분적 결과를 집계합니다. 이 접근 방법은 애플리케이션을 처리하는 데 효율적입니다. 집계 연산자(
sum,min,max등)에 대해 지연 데이터를 무기한 처리합니다. 이 접근 방식의 단점은 데이터베이스 계층에서 추가 애플리케이션 로직을 개발하고 유지 관리해야 한다는 것입니다. -
부분적 결과를 조기에 생성하지만 슬라이딩 윈도우 기간 동안 전체 결과를 계속 생성하는 텀블링 및 슬라이딩 윈도우를 사용합니다. 이 접근 방식은 데이터베이스 계층에서 추가 애플리케이션 로직을 추가할 필요가 없도록 upsert 대신 덮어쓰기를 사용하여 만기 데이터를 처리합니다. 이 접근 방식의 단점은 이것이 더 많은 Kinesis 처리 단위(KPU)를 사용하지만 여전히 두 개의 결과를 생성하므로 일부 사용 사례에는 효과적이지 않을 수 있다는 것입니다.
텀블링 및 슬라이딩 윈도우에 대한 자세한 설명은 윈도우 모드 쿼리 섹션을 참조하십시오.
다음 절차에서는 텀블링 윈도우 집계가 최종 결과를 생성하기 위해 결합해야 하는 두 개의 부분적 결과(CALC_COUNT_SQL_STREAM 애플리케이션 내 스트림으로 전송됨)를 생성합니다. 그런 다음 애플리케이션은 두 개의 부분적 결과를 결합하는 두 번째 집계(DESTINATION_SQL_STREAM 애플리케이션 내 스트림으로 전송됨)를 생성합니다.
이벤트 시간을 사용하여 부분적 결과를 집계하는 애플리케이션을 생성하려면
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/kinesis
Kinesis 콘솔을 엽니다. -
탐색 창에서 Data Analytics(데이터 분석)를 선택합니다. 교재 Amazon Kinesis Data Analytics for SQL 애플리케이션 시작하기의 설명에 따라 Kinesis Data Analytics 애플리케이션을 생성합니다.
-
SQL 편집기에서 애플리케이션 코드를 다음으로 바꿉니다.
CREATE OR REPLACE STREAM "CALC_COUNT_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (TICKER VARCHAR(4), TRADETIME TIMESTAMP, TICKERCOUNT DOUBLE); CREATE PUMP "CALC_COUNT_SQL_PUMP_001" AS INSERT INTO "CALC_COUNT_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER_SYMBOL", STEP("SOURCE_SQL_STREAM_001"."ROWTIME" BY INTERVAL '1' MINUTE) as "TradeTime", COUNT(*) AS "TickerCount" FROM "SOURCE_SQL_STREAM_001" GROUP BY STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE), STEP("SOURCE_SQL_STREAM_001"."APPROXIMATE_ARRIVAL_TIME" BY INTERVAL '1' MINUTE), TICKER_SYMBOL; CREATE PUMP "AGGREGATED_SQL_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" ("TICKER","TRADETIME", "TICKERCOUNT") SELECT STREAM "TICKER", "TRADETIME", SUM("TICKERCOUNT") OVER W1 AS "TICKERCOUNT" FROM "CALC_COUNT_SQL_STREAM" WINDOW W1 AS (PARTITION BY "TRADETIME" RANGE INTERVAL '10' MINUTE PRECEDING);애플리케이션 코드의
SELECT문이SOURCE_SQL_STREAM_001에서 주가 변동이 1%보다 큰 행을 필터링하여 펌프를 사용하여 또 다른 애플리케이션 내 스트림CHANGE_STREAM에 삽입합니다. -
[Save and run SQL]을 선택합니다.
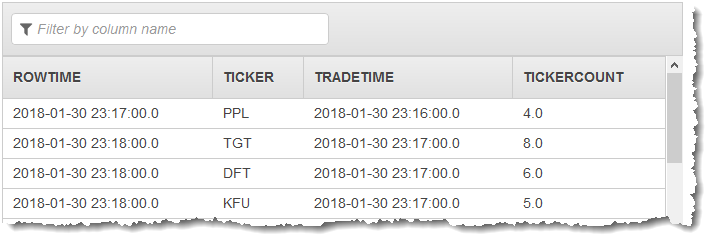
첫 번째 펌프는 다음과 비슷한 CALC_COUNT_SQL_STREAM에 스트림을 출력합니다. 결과 집합은 불완전합니다.
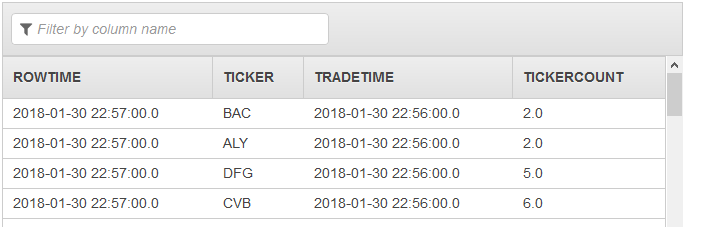
그런 다음 두 번째 펌프는 전체 결과 집합이 포함된 DESTINATION_SQL_STREAM에 스트림을 출력합니다.