신중한 고려 후 Amazon Kinesis Data Analytics for SQL 애플리케이션을 중단하기로 결정했습니다.
1. 2025년 9월 1일부터 Amazon Kinesis Data Analytics for SQL 애플리케이션에 대한 버그 수정은 제공되지 않습니다. 곧 중단될 예정이므로 지원이 제한될 예정이기 때문입니다.
2. 2025년 10월 15일부터 새 Kinesis Data Analytics for SQL 애플리케이션을 생성할 수 없습니다.
3. 2026년 1월 27일부터 애플리케이션이 삭제됩니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 시작하거나 작동할 수 없게 됩니다. 그 시점부터 Amazon Kinesis Data Analytics for SQL에 대한 지원을 더 이상 이용할 수 없습니다. 자세한 내용은 Amazon Kinesis Data Analytics for SQL 애플리케이션 단종 단원을 참조하십시오.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
예: 가장 자주 발생하는 값 검색(TOP_K_ITEMS_TUMBLING)
이 Amazon Kinesis Data Analytics 예에서는 TOP_K_ITEMS_TUMBLING 함수를 사용하여 텀블링 윈도우에서 가장 자주 발생하는 값을 검색하는 방법을 보여줍니다. 자세한 설명은 Amazon Managed Service for Apache Flink SQL 참조에서 TOP_K_ITEMS_TUMBLING 함수를 참조하십시오.
TOP_K_ITEMS_TUMBLING 함수는 수만 또는 수십만 개 이상의 키를 집계할 때 리소스 사용을 줄이려는 경우에 유용합니다. 이 함수는 GROUP BY 및 ORDER BY 절을 사용하여 집계하는 것과 동일한 결과를 생성합니다.
이 예에서는 다음 레코드를 Amazon Kinesis 데이터 스트림에 기록합니다:
{"TICKER": "TBV"} {"TICKER": "INTC"} {"TICKER": "MSFT"} {"TICKER": "AMZN"} ...
그런 다음 Kinesis 데이터 스트림을 스트리밍 소스로 AWS Management Console사용하여에서 Kinesis Data Analytics 애플리케이션을 생성합니다. 검색 프로세스는 스트리밍 소스에서 샘플 레코드를 읽고 다음과 같이 하나의 열(TICKER)을 사용하여 애플리케이션 내 스키마를 유추합니다.
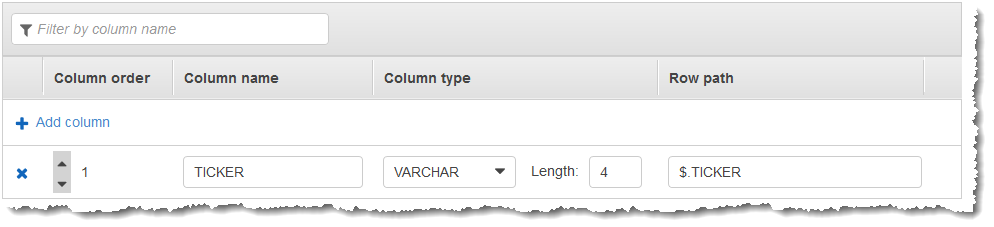
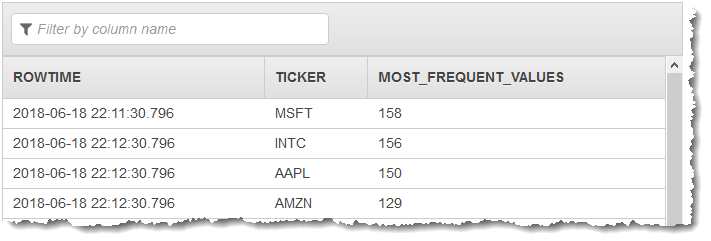
TOP_K_VALUES_TUMBLING 함수가 포함된 애플리케이션 코드를 사용하여 데이터의 윈도우 모드 집계를 생성합니다. 그런 다음 아래 스크린샷과 같이 다른 애플리케이션 내 스트림에 결과 데이터를 삽입합니다.
다음 절차에서는 입력 스트림에서 가장 자주 발생하는 값을 검색하는 Kinesis Data Analytics 애플리케이션을 생성합니다.
1단계: Kinesis 데이터 스트림 생성
Amazon Kinesis 데이터 스트림을 생성하고 다음과 같이 레코드를 채웁니다:
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/kinesis
Kinesis 콘솔을 엽니다. -
탐색 창에서 Data Streams(데이터 스트림)를 선택합니다.
-
Create Kinesis stream(Kinesis 스트림 생성)을 선택한 다음 샤드가 하나 있는 스트림을 생성합니다. 자세한 설명은 Amazon Kinesis Data Streams 개발자 가이드의 스트림 생성을 참조하십시오.
-
프로덕션 환경에서 Kinesis 데이터 스트림에 레코드를 기록하려면 Kinesis Client Library 또는 Kinesis Data Streams API를 사용하는 것이 좋습니다. 이 예에서는 간단한 설명을 위해 다음 Python 스크립트를 사용하여 레코드를 생성합니다. 코드를 실행하여 샘플 티커 레코드를 채웁니다. 이 단순한 코드는 임의의 티커 레코드를 스트림에 연속적으로 씁니다. 이후 단계에서 애플리케이션 스키마를 생성할 수 있도록 스크립트를 실행 중 상태로 둡니다.
import datetime import json import random import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return { "EVENT_TIME": datetime.datetime.now().isoformat(), "TICKER": random.choice(["AAPL", "AMZN", "MSFT", "INTC", "TBV"]), "PRICE": round(random.random() * 100, 2), } def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
2단계: Kinesis Data Analytics 애플리케이션 생성
다음과 같이 Kinesis Data Analytics 애플리케이션을 생성합니다:
https://console.aws.amazon.com/kinesisanalytics
에서 Managed Service for Apache Flink 콘솔을 엽니다. -
애플리케이션 생성을 선택하고 애플리케이션 명칭을 입력한 다음 애플리케이션 생성을 선택합니다.
-
애플리케이션 세부 정보 페이지에서 Connect streaming data(스트리밍 데이터 연결)를 선택하여 소스에 연결합니다.
-
Connect to source(소스에 연결) 페이지에서 다음을 수행합니다.
-
이전 섹션에서 생성한 스트림을 선택합니다.
-
Discover schema(스키마 발견)를 선택합니다. 유추된 스키마와, 생성된 애플리케이션 내 스트림에 대한 스키마를 유추하는 데 사용된 샘플 레코드를 콘솔이 표시할 때까지 기다립니다. 유추된 스키마에는 열이 한 개 있습니다.
-
[Save schema and update stream samples]를 선택합니다. 콘솔에서 스키마를 저장한 이후 종료를 선택합니다.
-
[Save and continue]를 선택합니다.
-
-
애플리케이션 세부 정보 페이지에서 Go to SQL editor(SQL 편집기로 이동)를 선택합니다. 애플리케이션을 시작하려면 나타나는 대화 상자에서 Yes, start application(예, 애플리케이션 시작)을 선택합니다.
-
SQL 편집기에서 애플리케이션 코드를 작성하고 다음과 같이 결과를 확인합니다.
-
다음 애플리케이션 코드를 복사하여 편집기에 붙여넣습니다:
CREATE OR REPLACE STREAM DESTINATION_SQL_STREAM ( "TICKER" VARCHAR(4), "MOST_FREQUENT_VALUES" BIGINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM * FROM TABLE (TOP_K_ITEMS_TUMBLING( CURSOR(SELECT STREAM * FROM "SOURCE_SQL_STREAM_001"), 'TICKER', -- name of column in single quotes 5, -- number of the most frequently occurring values 60 -- tumbling window size in seconds ) ); -
[Save and run SQL]을 선택합니다.
Real-time analytics(실시간 분석) 탭에서 애플리케이션이 생성한 모든 애플리케이션 내 스트림을 확인하고 데이터를 검증할 수 있습니다.
-
