기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon MSK로 Studio 노트북 생성
이 자습서에서는 소스로 Amazon MSK 클러스터를 사용하는 Studio 노트북을 생성하는 방법을 설명합니다.
이 자습서는 다음 섹션을 포함하고 있습니다.
Amazon MSK 클러스터 설정
이 자습서에서는 일반 텍스트 액세스를 허용하는 Amazon MSK 클러스터가 필요합니다. Amazon MSK 클러스터를 아직 설정하지 않은 경우, Amazon MSK 사용 시작하기 자습서를 따라 Amazon VPC, Amazon MSK 클러스터, 주제 및 Amazon EC2 클라이언트 인스턴스를 생성하세요.
자습서에 따라 다음을 수행하십시오:
3단계: Amazon MSK 클러스터 생성의 4단계에서
ClientBroker값을TLS에서PLAINTEXT로 변경합니다.
VPC에 NAT 게이트웨이 추가
Amazon MSK 사용 시작하기 자습서에 따라 Amazon MSK 클러스터를 생성했거나 기존 Amazon VPC에 프라이빗 서브넷용 NAT 게이트웨이가 아직 없는 경우, Amazon VPC에 NAT 게이트웨이를 추가해야 합니다. 다음 다이어그램은 아키텍처입니다.
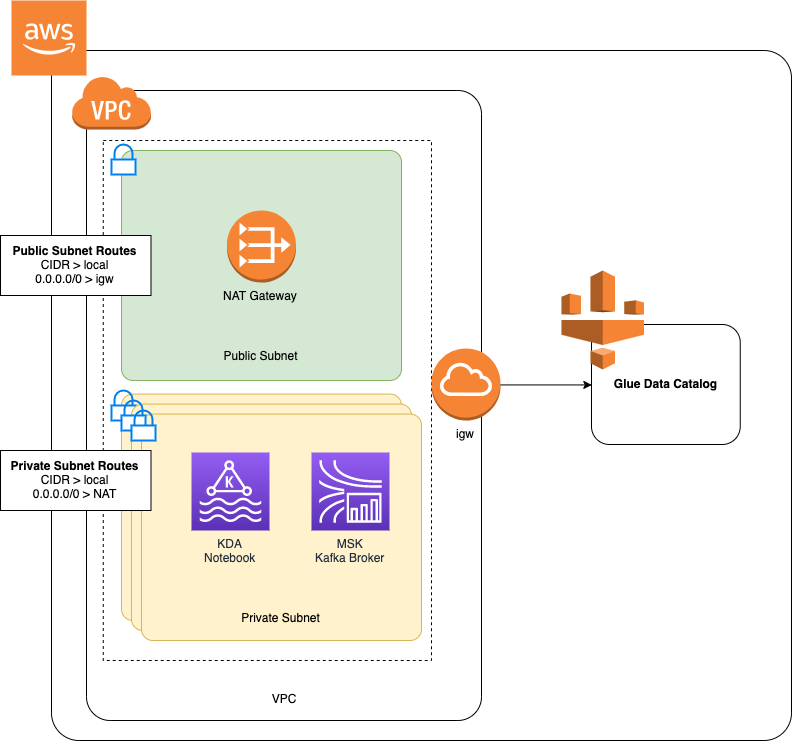
Amazon VPC용 NAT 게이트웨이를 생성하려면 다음을 수행하세요.
https://console.aws.amazon.com/vpc/
에서 Amazon VPC 콘솔을 엽니다. 왼쪽 탐색 모음에서 NAT 게이트웨이를 선택합니다.
NAT 게이트웨이 페이지에서 NAT 게이트웨이 생성을 선택합니다.
NAT 게이트웨이 생성 페이지에서 다음 값을 입력합니다.
명칭 - 선택 사항 ZeppelinGateway서브넷 AWS KafkaTutorialSubnet1 탄력적 IP 할당 ID Choose an available Elastic IP. If there are no Elastic IPs available, choose 탄력적 IP 할당, and then choose the Elasic IP that the console creates. NAT 게이트웨이 생성을 선택합니다.
왼쪽 탐색 모음에서 경로 표를 선택합니다.
[Create Route Table]을 선택합니다.
경로 표 생성 페이지에서 다음 정보를 제공합니다.
Name tag:
ZeppelinRouteTableVPC: VPC(예: AWS KafkaTutorialVPC)를 선택합니다.
생성(Create)을 선택합니다.
경로 표 목록에서 ZeppelinRouteTable을 선택합니다. 경로 탭에서 경로 편집을 선택합니다.
경로 편집 페이지에서 경로 추가를 선택합니다.
에서 대상 주소에
0.0.0.0/0을 입력합니다. 타겟에서 NAT 게이트웨이, ZeppelinGateway를 선택합니다. 경로 저장을 선택합니다. 닫기를 선택하세요.경로 표 페이지에서 ZeppelinRouteTable을 선택한 상태에서 서브넷 연결 탭을 선택합니다. 서브넷 연결 편집을 선택합니다.
서브넷 연결 편집 페이지에서 AWS KafkaTutorialSubnet2와 AWS KafkaTutorialSubnet3을 선택합니다. 저장을 선택합니다.
AWS Glue 연결 및 테이블 생성
Studio 노트북은 Amazon MSK 데이터 소스에 대한 메타데이터용 AWS Glue 데이터베이스를 사용합니다. 이 섹션에서는 Amazon MSK 클러스터에 액세스하는 방법을 설명하는 AWS Glue 연결과 Studio 노트북과 같은 클라이언트에 데이터 소스의 데이터를 제공하는 방법을 설명하는 AWS Glue 테이블을 생성합니다.
연결 생성
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/glue/
AWS Glue 콘솔을 엽니다. AWS Glue 데이터베이스가 아직 없는 경우 왼쪽 탐색 모음에서 데이터베이스를 선택합니다. 데이터베이스 추가를 선택합니다. 데이터베이스 추가 창에서 데이터베이스 이름을
default(으)로 입력합니다. 생성(Create)을 선택합니다.왼쪽 탐색 모음에서 연결을 선택합니다. 연결 추가를 선택합니다.
연결 추가 창에서 다음 값을 입력합니다.
연결 명칭에
ZeppelinConnection을 입력합니다.연결 유형에서 Kafka를 선택합니다.
Kafka 부트스트랩 서버 URL에 클러스터의 부트스트랩 브로커 문자열을 제공하세요. MSK 콘솔에서 또는 다음 CLI 명령을 입력하여 부트스트랩 브로커를 가져올 수 있습니다.
aws kafka get-bootstrap-brokers --region us-east-1 --cluster-arnClusterArnSSL 연결 필요 확인란의 선택을 취소하세요.
다음을 선택합니다.
VPC 페이지에서 다음 값을 입력합니다.
VPC에서 VPC의 이름(예: AWS KafkaTutorialVPC)을 선택합니다.
서브넷에서 AWS KafkaTutorialSubnet2를 선택합니다.
보안 그룹의 경우 사용 가능한 모든 그룹을 선택합니다.
다음을 선택합니다.
연결 속성 및 연결 액세스 페이지에서 마침을 선택합니다.
표 생성
참고
다음 단계에 설명된 대로 표을 수동으로 생성하거나 Apache Zeppelin 내의 노트북에서 Managed Service for Apache Flink용 표 커넥터 코드 생성을 사용하여 DDL 문을 통해 표을 생성할 수 있습니다. 그런 다음 테이블 AWS Glue 이 올바르게 생성되었는지 확인할 수 있습니다.
왼쪽 탐색 모음에서 표를 선택합니다. 표 페이지에서 표 추가, 표 수동 추가를 선택합니다.
표 속성 설정 페이지에서 표 명칭에
stock을 입력합니다. 이전에 만든 데이터베이스를 선택했는지 확인하세요. 다음을 선택합니다.데이터 스토어 추가 페이지에서 Kafka를 선택합니다. 주제 명칭에는 주제 명칭(예: AWS KafkaTutorialTopic)을 입력합니다. 연결에서 Zeppel In Connection을 선택합니다.
분류 페이지에서 JSON을 선택합니다. 다음을 선택합니다.
스키마 정의 페이지에서 열 추가를 선택하여 열을 추가합니다. 다음 속성을 가진 열을 추가합니다.
열 명칭 데이터 유형 시계문자열가격double다음을 선택합니다.
다음 페이지에서 설정을 확인하고 마침을 선택합니다.
-
테이블 목록에서 새로 생성한 테이블을 선택합니다.
-
표 편집을 선택하고 다음 속성을 추가합니다.
-
키:
managed-flink.proctime, 값:proctime -
키:
flink.properties.group.id, 값:test-consumer-group -
키:
flink.properties.auto.offset.reset, 값:latest -
키:
classification, 값:json
이러한 키/값 쌍이 없으면 Flink 노트북에서 오류가 발생합니다.
-
-
적용을 선택합니다.
Amazon MSK로 Studio 노트북 생성
애플리케이션에서 사용하는 리소스를 생성했으니 이제 Studio 노트북을 생성합니다.
AWS Management Console 또는를 사용하여 애플리케이션을 생성할 수 있습니다 AWS CLI.
참고
Amazon MSK 콘솔에서 기존 클러스터를 선택한 다음 실시간 데이터 처리를 선택하여 Studio 노트북을 생성할 수도 있습니다.
를 사용하여 Studio 노트북 생성 AWS Management Console
https://console.aws.amazon.com/managed-flink/home?region=us-east-1#/applications/dashboard
에서 Managed Service for Apache Flink 콘솔을 엽니다. Managed Service for Apache Flink 애플리케이션 페이지에서 Studio 탭을 선택합니다. Studio 노트북 생성을 선택합니다.
참고
Amazon MSK 또는 Kinesis Data Streams 콘솔에서 Studio 노트북을 생성하려면 입력 Amazon MSK 클러스터 또는 Kinesis 데이터 스트림을 선택한 다음 실시간 데이터 처리를 선택합니다.
Studio 노트북 생성 페이지에서 다음 정보를 입력합니다.
-
Studio 노트북 명칭
MyNotebook을 입력합니다. AWS Glue 데이터베이스의 기본값을 선택합니다.
Studio 노트북 생성을 선택합니다.
-
MyNotebook 페이지에서 구성 탭을 선택합니다. 네트워킹 섹션에서 편집을 선택합니다.
MyNotebook의 네트워킹 편집 페이지에서 Amazon MSK 클러스터를 기반으로 하는 VPC 구성을 선택합니다. Amazon MSK 클러스터용 Amazon MSK 클러스터를 선택하세요. 변경 사항 저장을 선택합니다.
MyNotebook 페이지에서 실행을 선택합니다. 상태가 실행 중으로 표시될 때까지 기다리세요.
를 사용하여 Studio 노트북 생성 AWS CLI
를 사용하여 Studio 노트북을 생성하려면 다음을 AWS CLI수행합니다.
다음 정보가 있는지 확인합니다. 애플리케이션을 생성하려면 이러한 값이 필요합니다.
계정 ID
Amazon MSK 클러스터를 포함하는 Amazon VPC의 서브넷 ID 및 보안 그룹 ID
다음 콘텐츠를 가진
create.json이라는 파일을 생성합니다: 자리 표시자 값을 정보로 바꿉니다.{ "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::AccountID:role/ZeppelinRole", "ApplicationConfiguration": { "ApplicationSnapshotConfiguration": { "SnapshotsEnabled": false }, "VpcConfigurations": [ { "SubnetIds": [ "SubnetID 1", "SubnetID 2", "SubnetID 3" ], "SecurityGroupIds": [ "VPC Security Group ID" ] } ], "ZeppelinApplicationConfiguration": { "CatalogConfiguration": { "GlueDataCatalogConfiguration": { "DatabaseARN": "arn:aws:glue:us-east-1:AccountID:database/default" } } } } }애플리케이션을 생성하려면 다음 명령을 실행합니다.
aws kinesisanalyticsv2 create-application --cli-input-json file://create.json명령이 완료되면 새 Studio 노트북의 세부 정보를 보여 주는 다음과 유사한 출력이 나타나야 합니다.
{ "ApplicationDetail": { "ApplicationARN": "arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook", "ApplicationName": "MyNotebook", "RuntimeEnvironment": "ZEPPELIN-FLINK-3_0", "ApplicationMode": "INTERACTIVE", "ServiceExecutionRole": "arn:aws:iam::012345678901:role/ZeppelinRole", ...애플리케이션을 시작하려면 다음 명령을 실행합니다. 샘플 값을 계정 ID로 바꿉니다.
aws kinesisanalyticsv2 start-application --application-arn arn:aws:kinesisanalyticsus-east-1:012345678901:application/MyNotebook\
Amazon MSK 클러스터로 데이터 전송
이 섹션에서는 Amazon EC2 클라이언트에서 Python 스크립트를 실행하여 Amazon MSK 데이터 소스로 데이터를 전송합니다.
Amazon EC2 클라이언트에 연결합니다.
다음 명령을 실행하여 Python 버전 3, Pip 및 Python용 Kafka 패키지를 설치하고 작업을 확인합니다.
sudo yum install python37 curl -O https://bootstrap.pypa.io/get-pip.py python3 get-pip.py --user pip install kafka-python다음 명령을 입력하여 클라이언트 시스템에서를 구성합니다 AWS CLI .
aws configureregion에 계정 자격 증명 및us-east-1을 제공하세요.다음 콘텐츠를 가진
stock.py이라는 파일을 생성합니다: 샘플 값을 Amazon MSK 클러스터의 부트스트랩 브로커 문자열로 바꾸고, 주제가 AWS KafkaTutorialTopic이 아닌 경우 주제 명칭을 업데이트하세요.from kafka import KafkaProducer import json import random from datetime import datetime BROKERS = "<<Bootstrap Broker List>>" producer = KafkaProducer( bootstrap_servers=BROKERS, value_serializer=lambda v: json.dumps(v).encode('utf-8'), retry_backoff_ms=500, request_timeout_ms=20000, security_protocol='PLAINTEXT') def getStock(): data = {} now = datetime.now() str_now = now.strftime("%Y-%m-%d %H:%M:%S") data['event_time'] = str_now data['ticker'] = random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']) price = random.random() * 100 data['price'] = round(price, 2) return data while True: data =getStock() # print(data) try: future = producer.send("AWSKafkaTutorialTopic", value=data) producer.flush() record_metadata = future.get(timeout=10) print("sent event to Kafka! topic {} partition {} offset {}".format(record_metadata.topic, record_metadata.partition, record_metadata.offset)) except Exception as e: print(e.with_traceback())다음 명령으로 스크립트를 실행합니다:
$ python3 stock.py다음 섹션을 완료하는 동안 스크립트는 실행 상태로 두세요.
Studio 노트북을 테스트
이 섹션에서는 Studio 노트북을 사용하여 Amazon MSK 클러스터에서 데이터를 쿼리합니다.
https://console.aws.amazon.com/managed-flink/home?region=us-east-1#/applications/dashboard
에서 Managed Service for Apache Flink 콘솔을 엽니다. Managed Service for Apache Flink 애플리케이션 페이지에서 Studio 노트북 탭을 선택합니다. MyNotebook을 선택합니다.
MyNotebook 페이지에서 Apache Zeppelin에서 열기를 선택합니다.
Apache Zeppelin 인터페이스가 새 탭에서 열립니다.
제플린에 오신 것을 환영합니다! 페이지에서 Zeppelin 새로운 노트를 선택하세요.
Zeppelin 노트 페이지에서 새로운 노트에 다음 쿼리를 입력합니다.
%flink.ssql(type=update) select * from stock실행 아이콘을 선택합니다.
애플리케이션은 Amazon MSK 클러스터의 데이터를 표시합니다.
애플리케이션에서 작동 측면을 볼 수 있도록 Apache Flink 대시보드를 열려면 FLINK JOB을 선택합니다. Flink 대시보드에 대한 자세한 내용을 알아보려면 Managed Service for Apache Flink 개발자 가이드의 Apache Flink 대시보드를 참조하세요.
Flink Streaming SQL 쿼리의 더 많은 예는 Apache Flink 설명서
