기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Neptune ML 기능 사용 방법 개요
Amazon Neptune ML 기능은 그래프 데이터베이스 내에서 기계 학습 모델을 활용하기 위한 간소화된 워크플로를 제공합니다. 이 프로세스에는 Neptune에서 CSV 형식으로 데이터 내보내기, 모델 훈련을 위해 준비하기 위한 데이터 사전 처리, Amazon SageMaker AI를 사용하여 기계 학습 모델 훈련, 예측을 제공하는 추론 엔드포인트 생성, Gremlin 쿼리에서 직접 모델 쿼리 등 여러 주요 단계가 포함됩니다. Neptune 워크벤치는 이러한 단계를 관리하고 자동화하는 데 도움이 되는 편리한 라인 및 셀 매직 명령을 제공합니다. 기계 학습 기능을 그래프 데이터베이스에 직접 통합하면 Neptune ML을 통해 사용자는 Neptune 그래프에 저장된 풍부한 관계형 데이터를 사용하여 중요한 인사이트를 도출하고 예측할 수 있습니다.
Neptune ML을 사용하기 위한 워크플로우 시작
Amazon Neptune에서 Neptune ML 기능을 사용하려면 일반적으로 다음과 같은 5단계를 거쳐야 합니다.
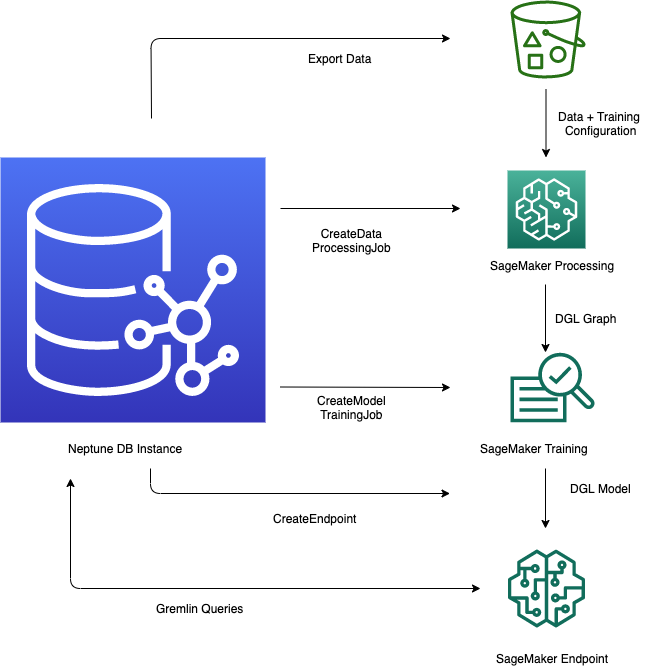
-
데이터 내보내기 및 구성 – 데이터 내보내기 단계에서는 Neptune-Export 서비스 또는
neptune-export명령줄 도구를 사용하여 Neptune에서 Amazon Simple Storage Service(S3)로 CSV 형식의 데이터를 내보냅니다. 이름이training-data-configuration.json으로 지정된 구성 파일이 동시에 자동으로 생성되며, 이 파일은 내보낸 데이터를 훈련 가능한 그래프에 로드하는 방법을 지정합니다. -
데이터 전처리 – 이 단계에서는 내보낸 데이터 세트를 표준 기법을 통해 사전 처리하여 모델 훈련에 사용할 준비를 합니다. 숫자형 데이터에 대해 특성 정규화를 수행하고
word2vec를 사용하여 텍스트 특성을 인코딩할 수 있습니다. 이 단계가 끝나면 모델 훈련 단계에서 사용할 수 있도록 내보낸 데이터 세트에서 딥 그래프 라이브러리(DGL) 그래프가 생성됩니다.이 단계는 계정의 SageMaker AI 처리 작업을 사용하여 구현되며, 결과 데이터는 사용자가 지정한 Amazon S3 위치에 저장됩니다.
-
모델 훈련 – 모델 훈련 단계에서는 예측에 사용할 기계 학습 모델을 훈련합니다.
모델 훈련은 두 단계로 이루어집니다.
첫 번째 단계에서는 SageMaker AI 처리 작업을 사용하여 모델 훈련에 사용할 모델 및 모델 하이퍼파라미터 범위의 유형을 지정하는 모델 훈련 전략 구성 세트를 생성합니다.
그런 다음 두 번째 단계에서는 SageMaker AI 모델 조정 작업을 통해 다양한 하이퍼파라미터 구성을 시도하고 가장 좋은 성과를 보인 모델을 생성한 훈련 작업을 선택합니다. 조정 작업은 처리된 데이터에 대해 미리 지정된 수의 모델 훈련 작업 시험을 실행합니다. 이 단계가 끝나면 최적 훈련 작업의 훈련된 모델 파라미터를 사용하여 추론을 위한 모델 아티팩트를 생성합니다.
-
Amazon SageMaker AI에서 추론 엔드포인트 생성 – 추론 엔드포인트는 최적 훈련 작업을 통해 생성된 모델 아티팩트와 함께 시작되는 SageMaker AI 엔드포인트 인스턴스입니다. 각 모델은 단일 엔드포인트에 연결되어 있습니다. 엔드포인트는 그래프 데이터베이스에서 들어오는 요청을 수락하고 요청의 입력에 대한 모델 예측을 반환할 수 있습니다. 엔드포인트를 생성한 후에는 삭제할 때까지 활성 상태를 유지합니다.
Gremlin을 사용하여 기계 학습 모델 쿼리 – Gremlin 쿼리 언어의 확장을 사용하여 추론 엔드포인트에서 예측을 쿼리할 수 있습니다.
참고
Neptune 워크벤치에는 라인 매직과 셀 매직이 포함되어 있어 다음과 같은 단계를 관리하는 데 많은 시간을 절약할 수 있습니다.
