기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
튜토리얼: Amazon OpenSearch Ingestion을 사용하여 컬렉션에 데이터 수집
이 튜토리얼에서는 Amazon OpenSearch Ingestion을 사용하여 간단한 파이프라인을 구성하고 Amazon OpenSearch Serverless 컬렉션에 데이터를 수집하는 방법을 보여줍니다. 파이프라인은 OpenSearch Ingestion이 프로비저닝하고 관리하는 리소스입니다. 파이프라인을 사용하여 OpenSearch Service의 다운스트림 분석 및 시각화를 위해 데이터를 필터링, 강화, 변환, 정규화 및 집계할 수 있습니다.
프로비저닝된 OpenSearch Service 도메인으로 데이터를 수집하는 방법을 보여주는 튜토리얼은 튜토리얼: Amazon OpenSearch Ingestion을 사용하여 도메인에 데이터 수집을 참조하세요.
이 자습서에서는 다음 단계를 완료합니다.
이 튜토리얼에서는 다음 리소스를 생성합니다.
-
파이프라인이 쓸
ingestion-collection이라는 컬렉션입니다. -
ingestion-pipeline-serverless이라는 파이프라인
필수 권한
이 자습서를 완료하려면 사용자 또는 역할에 다음과 같은 최소 권한이 포함된 연결된 자격 증명 기반 정책이 있어야 합니다. 이러한 권한을 가지고 파이프라인 역할을 생성하고, 정책(iam:Create* 및 iam:Attach*)을 연결하고, 컬렉션(aoss:*)을 생성 또는 수정하고, 파이프라인(osis:*) 작업을 수행할 수 있습니다.
또한 파이프라인 역할을 자동으로 생성하고 컬렉션에 데이터를 쓰도록 OpenSearch Ingestion에 전달하려면 몇 가지 IAM 권한이 필요합니다.
1단계: 컬렉션 생성
먼저, 데이터를 수집할 컬렉션을 생성합니다. 컬렉션 이름을 ingestion-collection로 지정하겠습니다.
-
https://console.aws.amazon.com/aos/home
에서 Amazon OpenSearch Service 콘솔로 이동합니다. -
왼쪽 탐색에서 컬렉션을 선택하고 컬렉션 생성을 선택합니다.
-
서버리스 생성 필드에서 클래식으로 전환을 선택합니다.
-
컬렉션 이름을 ingestion-collection으로 지정하세요.
-
보안에서 표준 생성을 선택합니다.
-
네트워크 액세스 설정에서 액세스 유형을 공개로 변경합니다.
-
다른 모든 설정을 기본값으로 유지하고 Next(다음)를 선택합니다.
-
이제 컬렉션에 대한 데이터 액세스 정책을 구성합니다. 액세스 정책 설정 자동 매칭을 선택 취소합니다.
-
정의 방법에는 JSON을 선택하고 편집기에 다음 정책을 붙여 넣습니다. 이 정책은 두 가지 기능을 합니다.
-
파이프라인 역할이 컬렉션에 쓸 수 있도록 허용합니다.
-
컬렉션에서 읽을 수 있도록 허용합니다. 나중에 일부 샘플 데이터를 파이프라인으로 수집한 후 컬렉션을 쿼리하여 데이터가 성공적으로 수집되고 인덱스에 기록되었는지 확인합니다.
[ { "Rules": [ { "Resource": [ "index/ingestion-collection/*" ], "Permission": [ "aoss:CreateIndex", "aoss:UpdateIndex", "aoss:DescribeIndex", "aoss:ReadDocument", "aoss:WriteDocument" ], "ResourceType": "index" } ], "Principal": [ "arn:aws:iam::your-account-id:role/OpenSearchIngestion-PipelineRole", "arn:aws:iam::your-account-id:role/Admin" ], "Description": "Rule 1" } ]
-
-
AWS 계정 ID를 포함하도록
Principal요소를 수정합니다. 두 번째 위탁자는 나중에 컬렉션을 쿼리하는 데 사용할 수 있는 사용자 또는 역할을 지정합니다. -
다음을 선택합니다. 액세스 정책 이름을 pipeline-collection-access로 지정하고 다음을 다시 선택합니다.
-
컬렉션 구성을 검토하고 Submit(제출)을 선택합니다.
2단계: 파이프라인 생성
이제 컬렉션이 있으므로 파이프라인을 생성할 수 있습니다.
파이프라인을 만들려면
-
Amazon OpenSearch Service 콘솔 내 왼쪽 탐색 창에서 파이프라인을 선택합니다.
-
[파이프라인 생성]을 선택합니다.
-
빈 파이프라인을 선택한 다음, 블루프린트 선택을 선택합니다.
-
이 자습서에서는 HTTP 소스
플러그인을 사용하는 파이프라인을 만들어 봅니다. 플러그인은 JSON 배열 형식의 로그 데이터를 받아들입니다. 단일 OpenSearch Serverless 컬렉션을 싱크로 지정하고 모든 데이터를 my_logs인덱스로 수집하겠습니다.소스 메뉴에서 HTTP를 선택합니다. 경로에 /logs를 입력합니다.
-
이 튜토리얼에서는 간소화를 위해 파이프라인에 대한 공개 액세스를 구성해 보겠습니다. 소스 네트워크 옵션에서 퍼블릭 액세스를 선택합니다. VPC에 대한 액세스를 구성하는 방법에 대한 자세한 정보는 Amazon OpenSearch Ingestion 파이프라인에 대한 VPC 액세스 구성 섹션을 참조하세요.
-
다음을 선택합니다.
-
프로세서에 날짜를 입력하고 추가를 선택합니다.
-
수신된 시작 시간을 활성화합니다. 다른 모든 설정은 기본값으로 둡니다.
-
다음을 선택합니다.
-
싱크 세부 정보를 구성합니다. OpenSearch 리소스 유형에서 컬렉션(서버리스)을 선택합니다. 그런 다음 이전 섹션에서 생성한 OpenSearch Service 컬렉션을 선택합니다.
네트워크 정책 이름을 기본값으로 둡니다. 인덱스 이름에 my_logs를 입력합니다. 아직 없는 경우 OpenSearch Ingestion이 컬렉션에 이 인덱스를 자동으로 생성합니다.
-
다음을 선택합니다.
-
파이프라인 이름을 ingestion-pipeline-serverless로 지정합니다. 용량 설정을 기본값으로 둡니다.
-
파이프라인 역할에서 새 서비스 역할 생성 및 사용을 선택합니다. 이 파이프라인 역할은 파이프라인이 컬렉션 싱크에 쓰고 풀 기반 소스에서 읽는 데 필요한 권한을 제공합니다. 이 옵션을 선택하면 IAM에서 역할을 수동으로 생성하는 대신 OpenSearch Ingestion이 역할을 생성하도록 허용할 수 있습니다. 자세한 내용은 Amazon OpenSearch Ingestion 내 역할 및 사용자 설정 단원을 참조하십시오.
-
서비스 역할 이름 접미사에 PipelineRole을 입력합니다. IAM에서 역할은
arn:aws:iam::형식입니다.your-account-id:role/OpenSearchIngestion-PipelineRole -
다음을 선택합니다. 파이프라인 구성을 검토하고 파이프라인 생성을 선택합니다. 파이프라인이 활성화되려면 5~10분이 걸립니다.
3단계: 일부 샘플 데이터 수집
파이프라인이 Active 상태가 되면 데이터 수집을 시작할 수 있습니다. 서명 버전 4를 사용하여 파이프라인에 대한 모든 HTTP 요청에 서명해야 합니다. Postman
참고
요청에 서명하는 주체에게는 osis:Ingest IAM 권한이 있어야 합니다.
먼저 파이프라인 설정 페이지에서 수집 URL을 가져옵니다.
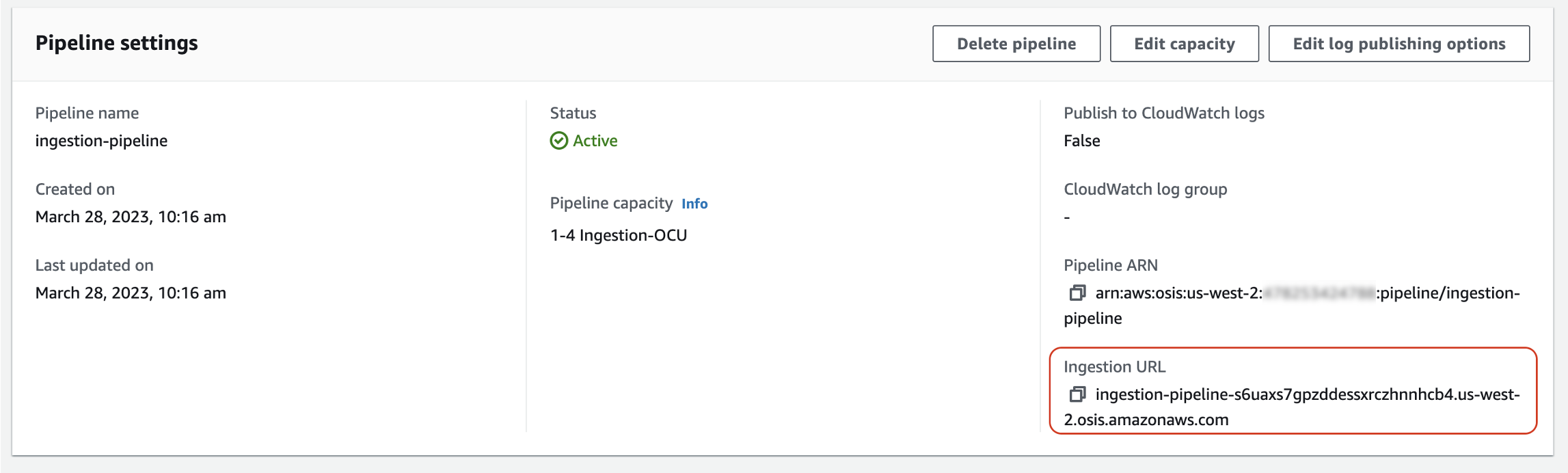
그런 다음 일부 샘플 데이터를 수집 경로로 전송합니다. 다음 샘플 요청은 awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
200 OK 응답이 표시되어야 합니다.
이제 my_logs 인덱스를 쿼리하여 로그 항목이 성공적으로 수집되었는지 확인하세요.
awscurl --service aoss --regionus-east-1\ -X GET \ https://collection-id.us-east-1.aoss.amazonaws.com/my_logs/_search | json_pp
샘플 응답:
{ "took":348, "timed_out":false, "_shards":{ "total":0, "successful":0, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"my_logs", "_id":"1%3A0%3ARJgDvIcBTy5m12xrKE-y", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2023-04-26T05:22:16.204Z" } } ] } }
관련 리소스
이 튜토리얼에서는 HTTP를 통해 단일 문서를 수집하는 간단한 사용 사례를 제시했습니다. 프로덕션 시나리오에서는 하나 이상의 파이프라인으로 데이터를 전송하도록 클라이언트 애플리케이션(예: Fluent Bit, Kubernetes 또는 OpenTelemetry Collector)을 구성합니다. 파이프라인은 이 튜토리얼의 간단한 예제보다 더 복잡할 수 있습니다.
클라이언트 구성 및 데이터 수집을 시작하려면 다음 리소스를 참조하세요.
