기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
결과 게시 및 보기
Amazon Personalize는 각 지표에 대한 보고서를 아마존 S3에 CloudWatch 전송합니다.
-
PutEvents 데이터 및 증분 대량 데이터의 경우 Amazon Personalize는 자동으로 메트릭을 에 전송합니다. CloudWatch 에서 CloudWatch 보고서를 보고 식별하는 방법에 대한 자세한 내용은 을 참조하십시오. 에서 측정항목 보기 CloudWatch
-
모든 대량 데이터의 경우, 지표 어트리뷰션을 생성할 때 S3 버킷을 제공하면 상호작용 데이터에 대한 데이터세트 가져오기 작업을 생성할 때마다 S3 버킷에 지표 보고서를 게시하도록 선택할 수 있습니다.
지표 보고서를 S3에 게시하는 방법에 대한 자세한 내용은 S3에 지표 게시단원을 참조하세요.
에서 측정항목 보기 CloudWatch
에서 CloudWatch 지표를 보려면 지표 그래프 작성에 있는 절차를 완료하세요. 그래프로 표시할 수 있는 최소 기간은 15분입니다. 검색어에는 지표 어트리뷰션을 만들 때 지표에 지정한 이름을 지정합니다.
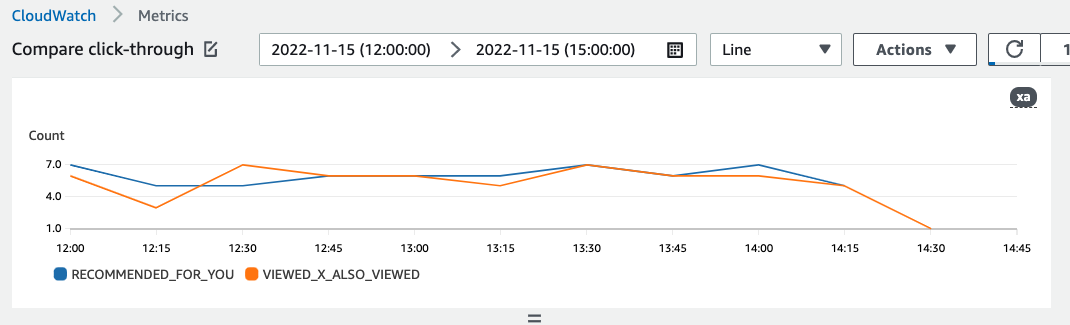
다음은 지표가 표시되는 CloudWatch 방식의 예입니다. 이 지표는 서로 다른 두 추천자에 대한 15분 마다의 클릭률을 보여줍니다.
S3에 지표 게시
S3에 지표를 게시하려면 지표 어트리뷰션에 S3 버킷의 경로를 제공합니다. 그런 다음 데이터세트 가져오기 작업을 생성할 때 S3에 보고서를 게시합니다.
작업이 완료되면 S3 버킷에서 지표를 찾을 수 있습니다. 지표를 게시할 때마다 Personalize는 S3 버킷에 새 파일을 생성합니다. 파일 이름에는 다음과 같은 가져오기 방법과 날짜가 포함됩니다.
AggregatedAttributionMetrics - ImportMethod -
Timestamp.csv
다음은 지표 보고서 CSV 파일의 처음 몇 행이 나타나는 방식의 예입니다. 이 예제의 지표는 15분 간격으로 서로 다른 두 추천자의 총 클릭 수를 보고합니다. 각 추천자는 EVENT_ATTRIBUTION_SOURCE 열의 리소스 이름(ARN)을 기준으로 식별할 수 있습니다.
METRIC_NAME,EVENT_TYPE,VALUE,MATH_FUNCTION,EVENT_ATTRIBUTION_SOURCE,TIMESTAMP
COUNTWATCHES,WATCH,12.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666925124
COUNTWATCHES,WATCH,112.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666924224
COUNTWATCHES,WATCH,10.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666924224
COUNTWATCHES,WATCH,254.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666922424
COUNTWATCHES,WATCH,112.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender1Name,1666922424
COUNTWATCHES,WATCH,100.0,samplecount,arn:aws:personalize:us-west-2:acctNum:recommender/recommender2Name,1666922424
......
.....
S3에 대량 데이터에 대한 지표 게시(콘솔)
Personalize 콘솔을 사용하여 S3 버킷에 지표를 게시하려면 데이터세트 가져오기 작업을 생성하고 S3에 이벤트 지표 게시에서 이 가져오기 작업에 대한 지표 게시를 선택합니다.
자세한 지침은 을 참조하십시오. step-by-step 대량 레코드 가져오기(콘솔)
S3에 대량 데이터에 대한 지표 게시(AWS CLI)
AWS Command Line Interface (AWS CLI) 를 사용하여 Amazon S3 버킷에 지표를 게시하려면 다음 코드를 사용하여 데이터세트 가져오기 작업을 만들고 publishAttributionMetricsToS3 플래그를 제공하십시오. 특정 작업에 대한 지표를 게시하지 않으려는 경우 플래그를 생략합니다. 각 파라미터에 대한 자세한 내용은 CreateDatasetImportJob단원을 참조하세요.
aws personalize create-dataset-import-job \
--job-name dataset import job name \
--dataset-arn dataset arn \
--data-source dataLocation=s3://bucketname/filename \
--role-arn roleArn \
--import-mode INCREMENTAL \
--publish-attribution-metrics-to-s3
Amazon S3 (AWS SDK) 에 대량 데이터에 대한 지표 게시
AWS SDK를 사용하여 Amazon S3 버킷에 지표를 게시하려면 데이터세트 가져오기 작업을 생성하고 publishAttributionMetricsToS3 true로 설정합니다. 각 파라미터에 대한 자세한 내용은 CreateDatasetImportJob단원을 참조하세요.
- SDK for Python (Boto3)
-
import boto3
personalize = boto3.client('personalize')
response = personalize.create_dataset_import_job(
jobName = 'YourImportJob',
datasetArn = 'dataset_arn',
dataSource = {'dataLocation':'s3://bucket/file.csv'},
roleArn = 'role_arn',
importMode = 'INCREMENTAL',
publishAttributionMetricsToS3 = True
)
dsij_arn = response['datasetImportJobArn']
print ('Dataset Import Job arn: ' + dsij_arn)
description = personalize.describe_dataset_import_job(
datasetImportJobArn = dsij_arn)['datasetImportJob']
print('Name: ' + description['jobName'])
print('ARN: ' + description['datasetImportJobArn'])
print('Status: ' + description['status'])
- SDK for Java 2.x
-
public static String createPersonalizeDatasetImportJob(PersonalizeClient personalizeClient,
String jobName,
String datasetArn,
String s3BucketPath,
String roleArn,
ImportMode importMode,
boolean publishToS3) {
long waitInMilliseconds = 60 * 1000;
String status;
String datasetImportJobArn;
try {
DataSource importDataSource = DataSource.builder()
.dataLocation(s3BucketPath)
.build();
CreateDatasetImportJobRequest createDatasetImportJobRequest = CreateDatasetImportJobRequest.builder()
.datasetArn(datasetArn)
.dataSource(importDataSource)
.jobName(jobName)
.roleArn(roleArn)
.importMode(importMode)
.publishAttributionMetricsToS3(publishToS3)
.build();
datasetImportJobArn = personalizeClient.createDatasetImportJob(createDatasetImportJobRequest)
.datasetImportJobArn();
DescribeDatasetImportJobRequest describeDatasetImportJobRequest = DescribeDatasetImportJobRequest.builder()
.datasetImportJobArn(datasetImportJobArn)
.build();
long maxTime = Instant.now().getEpochSecond() + 3 * 60 * 60;
while (Instant.now().getEpochSecond() < maxTime) {
DatasetImportJob datasetImportJob = personalizeClient
.describeDatasetImportJob(describeDatasetImportJobRequest)
.datasetImportJob();
status = datasetImportJob.status();
System.out.println("Dataset import job status: " + status);
if (status.equals("ACTIVE") || status.equals("CREATE FAILED")) {
break;
}
try {
Thread.sleep(waitInMilliseconds);
} catch (InterruptedException e) {
System.out.println(e.getMessage());
}
}
return datasetImportJobArn;
} catch (PersonalizeException e) {
System.out.println(e.awsErrorDetails().errorMessage());
}
return "";
}
- SDK for JavaScript v3
// Get service clients and commands using ES6 syntax.
import { CreateDatasetImportJobCommand, PersonalizeClient } from
"@aws-sdk/client-personalize";
// create personalizeClient
const personalizeClient = new PersonalizeClient({
region: "REGION"
});
// Set the dataset import job parameters.
export const datasetImportJobParam = {
datasetArn: 'DATASET_ARN', /* required */
dataSource: {
dataLocation: 's3://<name of your S3 bucket>/<folderName>/<CSVfilename>.csv' /* required */
},
jobName: 'NAME', /* required */
roleArn: 'ROLE_ARN', /* required */
importMode: "FULL", /* optional, default is FULL */
publishAttributionMetricsToS3: true /* set to true to publish metrics to Amazon S3 bucket */
};
export const run = async () => {
try {
const response = await personalizeClient.send(new CreateDatasetImportJobCommand(datasetImportJobParam));
console.log("Success", response);
return response; // For unit tests.
} catch (err) {
console.log("Error", err);
}
};
run();