기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
분산 가용성 그룹
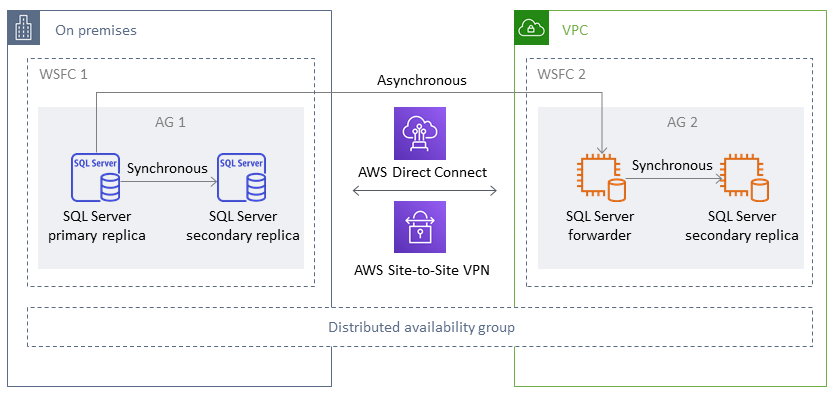
분산 가용성 그룹은 두 개의 개별 가용성 그룹에 걸쳐 있습니다. 가용성 그룹으로 구성된 가용성 그룹이라고 생각하시면 됩니다. 기본 가용성 그룹은 서로 다른 두 WSFC 클러스터에 구성됩니다. 분산 가용성 그룹에 참여하는 가용성 그룹은 동일한 위치를 공유할 필요가 없습니다. 물리적 또는 가상, 온프레미스 또는 퍼블릭 클라우드에 있을 수 있습니다. 분산 가용성 그룹의 가용성 그룹은 동일한 버전의 SQL Server를 실행할 필요가 없습니다. 대상 DB 인스턴스는 원본 DB 인스턴스보다 최신 버전의 SQL Server를 실행할 수 있습니다.
분산 가용성 그룹 아키텍처를 사용하면 미션 크리티컬 SQL Server 인스턴스 또는 데이터베이스를 유연하게 리호스팅할 수 있습니다 AWS. 이는 중요한 SQL Server 데이터베이스를 AWS에 리프트 앤 시프트(또는 리프팅 및 변환)할 수 있는 하이브리드 솔루션을 제공합니다.
분산 가용성 그룹 아키텍처를 사용하는 것이 기존 온프레미스 WFSC 클러스터를 로 확장하는 것보다 더 효율적입니다 AWS. 데이터는 온프레미스 기본에서 AWS 복제본 중 하나(전달자)로만 전송됩니다. 전달자는의 다른 보조 읽기 전용 복제본으로 데이터를 전송할 책임이 있습니다 AWS.
다음 다이어그램에서 첫 번째 WSFC 클러스터(WSFC 1)는 온프레미스로 호스팅되며 온프레미스 가용성 그룹(AG 1)이 있습니다. 두 번째 WSFC 클러스터(WSFC 2)는에서 호스팅 AWS 되며 AWS 가용성 그룹(AG 2)이 있습니다. Direct Connect
참고
어느 시점이든 쓰기 작업에 사용할 수 있는 데이터베이스는 하나뿐입니다. 나머지 보조 복제본은 읽기 작업에 사용할 수 있습니다. 읽기 워크로드를 스케일 아웃하려면 AWS의 여러 가용 영역에 읽기 전용 복제본을 추가할 수 있습니다.
분산 가용성 그룹에 대한 자세한 내용은 다음을 참조하세요.
-
AWS 데이터베이스 블로그의 분산 가용성 그룹을 사용하여 하이브리드 Microsoft SQL Server 솔루션을 설계하는 방법
-
AWS 권장 가이드 웹 사이트에서 분산 가용성 그룹을 AWS 사용하여 SQL Server를 로 마이그레이션
