기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
API 구성 패턴
이 패턴은 API 컴포저 또는 애그리게이터를 사용하여 데이터를 소유하는 개별 마이크로서비스를 호출하여 쿼리를 구현합니다. 그런 다음 인 메모리 조인을 수행하여 결과를 결합합니다.
다음 다이어그램은 이 패턴이 구현되는 방식을 보여 줍니다.
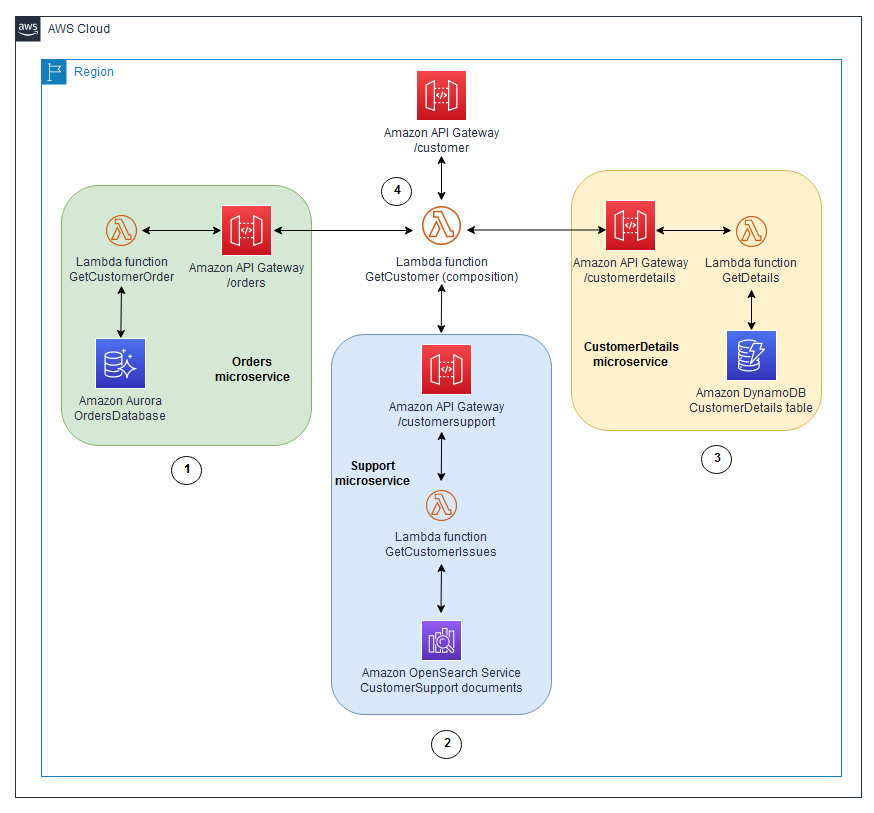
이 다이어그램은 다음 워크플로를 보여줍니다.
-
API Gateway는 Aurora 데이터베이스에서 고객 주문을 추적하는 ‘주문’ 마이크로서비스가 있는 ‘/customer’ API를 제공합니다.
-
‘지원’ 마이크로서비스는 고객 지원 문제를 추적하여 Amazon OpenSearch Service 데이터베이스에 저장합니다.
-
‘CustomerDetails’ 마이크로서비스는 DynamoDB 테이블의 고객 속성(예: 주소, 전화번호 또는 결제 세부 정보)을 유지 관리합니다.
-
‘GetCustomer’ Lambda 함수는 이러한 마이크로서비스에 대한 API를 실행하고 데이터를 요청자에게 반환하기 전에 데이터에 대한 인 메모리 조인을 수행합니다. 이를 통해 사용자 대면 API에 대한 네트워크 호출 한 번으로 고객 정보를 쉽게 검색할 수 있으며 인터페이스가 매우 단순해집니다.
API 구성 패턴은 여러 마이크로서비스에서 데이터를 수집하는 가장 간단한 방법을 제공합니다. 하지만 API 구성 패턴을 사용하면 다음과 같은 단점이 있습니다.
-
복잡한 쿼리와 인 메모리 조인이 필요한 대규모 데이터세트에는 적합하지 않을 수 있습니다.
-
API 컴포저에 연결된 마이크로서비스의 수를 늘리면 전체 시스템의 가용성이 떨어집니다.
-
데이터베이스 요청이 증가하면 네트워크 트래픽 또한 증가하여, 운영 비용이 증가합니다.
