기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS Step Functions를 사용하여 검증, 변환 및 파티셔닝을 사용하여 ETL 파이프라인 오케스트레이션
작성자: Sandip Gangapadhyay(AWS)
코드 리포지토리: aws-step-functions-etl-pipeline-pattern | 환경: 프로덕션 | 기술: 분석, 빅 데이터, 데이터 레이크 DevOps, 서버리스 |
AWS 서비스: Amazon Athena , AWS Glue, AWS Lambda, AWS Step Functions |
요약
이 패턴은 서버리스 추출, 변환 및 로드(ETL) 파이프라인을 구축하여 성능 및 비용 최적화를 위해 대규모 CSV 데이터 세트를 검증, 변환, 압축 및 분할하는 방법을 설명합니다. 파이프라인은 AWS Step Functions에서 오케스트레이션하며 오류 처리, 자동 재시도 및 사용자 알림 기능을 포함합니다.
CSV 파일이 Amazon Simple Storage Service(Amazon S3) 버킷 소스 폴더에 업로드되면 ETL 파이프라인이 실행되기 시작합니다. 파이프라인은 소스 CSV 파일의 콘텐츠와 스키마를 검증하고, CSV 파일을 압축된 Apache Parquet 형식으로 변환하고, 데이터 세트를 연도, 월, 일로 분할하고, 분석 도구가 처리할 수 있도록 별도의 폴더에 저장합니다.
이 패턴을 자동화하는 코드는 ETL AWS Step Functions 리포지토리가 있는 파이프라인
사전 조건 및 제한 사항
사전 조건
활성 상태의 AWS 계정.
AWS 명령줄 인터페이스(AWS CLI)가 AWS 계정과 함께 설치 및 구성되어 AWS CloudFormation 스택을 배포하여 AWS 리소스를 생성할 수 있습니다. AWS CLI 버전 2가 권장됩니다. 설치 지침은 AWS CLI 설명서의 AWS CLI 버전 2 설치, 업데이트 및 제거를 참조하세요. AWS CLI 구성 지침은 AWS CLI 설명서의 구성 및 보안 인증 파일 설정을 참조하세요.
Amazon S3 버킷.
올바른 스키마가 있는 CSV 데이터 세트입니다. (이 패턴에 포함된 코드 리포지토리는
사용할 수 있는 올바른 스키마와 데이터 유형이 포함된 샘플 CSV 파일을 제공합니다.) AWS 관리 콘솔과 함께 사용할 수 있도록 지원되는 웹 브라우저입니다. (지원되는 브라우저 목록
을 참조하십시오.) AWS Glue 콘솔 액세스.
AWS Step Functions 콘솔 액세스.
제한 사항
AWS Step Functions에서 기록 로그 유지를 위한 최대 한도는 90일입니다. 자세한 내용은 AWS Step Functions 설명서의 표준 워크플로에 대한 할당량 및 할당량을 참조하세요. https://docs.aws.amazon.com/step-functions/latest/dg/limits.html
제품 버전
AWS Lambda용 Python 3.11
AWS Glue 버전 2.0
아키텍처

다이어그램에 표시된 워크플로는 다음과 같은 상위 수준 단계로 구성되어 있습니다.
사용자가 Amazon S3의 소스 폴더에 CSV 파일을 업로드합니다.
Amazon S3 알림 이벤트는 Step Functions 상태 시스템을 시작하는 AWS Lambda 함수를 시작합니다.
Lambda 함수는 원시 CSV 파일의 스키마와 데이터 유형을 검증합니다.
검증 결과에 따라:
소스 파일의 검증에 성공하면 파일은 추가 처리를 위해 스테이지 폴더로 이동합니다.
검증에 실패하면 파일이 오류 폴더로 이동하고 Amazon Simple Notification Service(Amazon)를 통해 오류 알림이 전송됩니다SNS.
Glue AWS 크롤러는 Amazon S3의 스테이지 폴더에서 원시 파일의 스키마를 생성합니다.
AWS Glue 작업은 원시 파일을 Parquet 형식으로 변환, 압축 및 분할합니다.
또한 AWS Glue 작업은 파일을 Amazon S3의 변환 폴더로 이동합니다.
Glue AWS 크롤러는 변환된 파일에서 스키마를 생성합니다. 결과 스키마는 모든 분석 작업에서 사용할 수 있습니다. Amazon Athena를 사용하여 임시 쿼리를 실행할 수 있습니다.
파이프라인이 오류 없이 완료되면 스키마 파일이 아카이브 폴더로 이동됩니다. 오류가 발생하는 경우 파일은 대신 오류 폴더로 이동됩니다.
Amazon은 파이프라인 완료 상태에 따라 성공 또는 실패를 나타내는 알림을 SNS 보냅니다.
이 패턴에 사용되는 모든 AWS 리소스는 서버리스입니다. 관리할 서버가 없습니다.
도구
AWS 서비스
AWS Glue
– AWS Glue는 고객이 분석을 위해 데이터를 쉽게 준비하고 로드할 수 있도록 하는 완전 관리형 ETL 서비스입니다. AWS Step Functions
– AWS Step Functions는 AWS Lambda 함수와 기타 서비스를 결합하여 비즈니스 크리티컬 애플리케이션을 구축할 수 있는 서버리스 오케스트레이션 AWS 서비스입니다. AWS Step Functions 그래픽 콘솔을 통해 애플리케이션의 워크플로를 일련의 이벤트 기반 단계로 볼 수 있습니다. Amazon S3
- Amazon Simple Storage Service(S3)는 업계 최고의 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. Amazon SNS
– Amazon Simple Notification Service(Amazon SNS)는 마이크로서비스, 분산 시스템 및 서버리스 애플리케이션을 분리할 수 있는 가용성, 내구성, 보안성이 뛰어나고 완전 관리형 pub/sub 메시징 서비스입니다. AWS Lambda
– AWS Lambda는 서버를 프로비저닝하거나 관리하지 않고도 코드를 실행할 수 있는 컴퓨팅 서비스입니다. AWS Lambda는 필요한 경우에만 코드를 실행하고 하루에 몇 번의 요청에서 초당 수천 건의 요청으로 자동으로 확장됩니다.
code
이 패턴의 코드는 ETL AWS Step Functions 리포지토리가 있는 파이프라인
template.yml– AWS Step Functions를 사용하여 ETL 파이프라인을 생성하기 위한 AWS CloudFormation 템플릿입니다.parameter.json- 모든 파라미터와 파라미터 값을 포함합니다. 에픽 섹션에 설명된 대로 이 파일을 업데이트하여 파라미터 값을 변경합니다.myLayer/python폴더 - 이 프로젝트에 필요한 AWS Lambda 계층을 생성하는 데 필요한 Python 패키지를 포함합니다.lambda폴더 - 다음과 같은 Lambda 함수를 포함합니다.move_file.py- 소스 데이터 세트를 아카이브, 변환 또는 오류 폴더로 이동합니다.check_crawler.py- Glue AWS 크롤러가 실패 메시지를 보내기 전에RETRYLIMIT환경 변수에서 구성한 횟수만큼 Glue 크롤러의 상태를 확인합니다.start_crawler.py– AWS Glue 크롤러를 시작합니다.start_step_function.py– AWS 단계 함수를 시작합니다.start_codebuild.py– AWS CodeBuild 프로젝트를 시작합니다.validation.py- 입력 원시 데이터 세트를 검증합니다.s3object.py- S3 버킷 내에 필요한 디렉터리 구조를 생성합니다.notification.py- 파이프라인 끝에 성공 또는 오류 알림을 보냅니다.
샘플 코드를 사용하려면 에픽 섹션의 지침을 따르십시오.
에픽
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
샘플 코드 리포지토리를 복제합니다. |
| 개발자 |
파라미터 값을 업데이트합니다. | 리포지토리의 로컬 사본에서 다음과 같이
| 개발자 |
소스 코드를 S3 버킷에 업로드합니다. | ETL 파이프라인을 자동화하는 CloudFormation 템플릿을 배포하기 전에 CloudFormation 템플릿의 소스 파일을 패키징하여 S3 버킷에 업로드해야 합니다. 이렇게 하려면 사전 구성된 프로파일로 다음 AWS CLI 명령을 실행합니다.
여기서 각 항목은 다음과 같습니다.
| 개발자 |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
CloudFormation 템플릿을 배포합니다. | CloudFormation 템플릿을 배포하려면 다음 AWS CLI 명령을 실행합니다.
여기서 각 항목은 다음과 같습니다.
| 개발자 |
진행 상황을 확인합니다. | AWS CloudFormation 콘솔 | 개발자 |
AWS Glue 데이터베이스 이름을 기록해 둡니다. | 스택의 출력 탭에는 AWS Glue 데이터베이스의 이름이 표시됩니다. 키 이름이 | 개발자 |
| 작업 | 설명 | 필요한 기술 |
|---|---|---|
ETL 파이프라인을 시작합니다. |
| 개발자 |
파티셔닝된 데이터 세트를 확인하십시오. | ETL 파이프라인이 완료되면 Amazon S3 변환 폴더( | 개발자 |
분할된 AWS Glue 데이터베이스를 확인합니다. |
| 개발자 |
쿼리를 실행하십시오. | (선택 사항) Amazon Athena를 사용하여 파티셔닝되고 변환된 데이터베이스에서 임시 쿼리를 실행합니다. 지침은 AWS 설명서의Amazon Athena를 사용하여 SQL 쿼리 실행을 참조하세요. | 데이터베이스 분석가 |
문제 해결
| 문제 | Solution |
|---|---|
AWS Glue 작업 및 AWS 크롤러에 대한 자격 증명 및 액세스 관리(IAM) 권한 | Glue 작업 또는 AWS 크롤러를 추가로 사용자 지정하는 경우 AWSGlue 작업에서 사용하는 IAM 역할에 적절한 IAM 권한을 부여하거나 AWS Lake Formation에 데이터 권한을 제공해야 합니다. 자세한 내용은 AWS 설명서 섹션을 참조하세요. |
관련 리소스
AWS 서비스 설명서
추가 정보
다음 다이어그램은 AWS Step Functions Inspector 패널의 성공적인 ETL 파이프라인을 위한 Step Functions 워크플로를 보여줍니다.
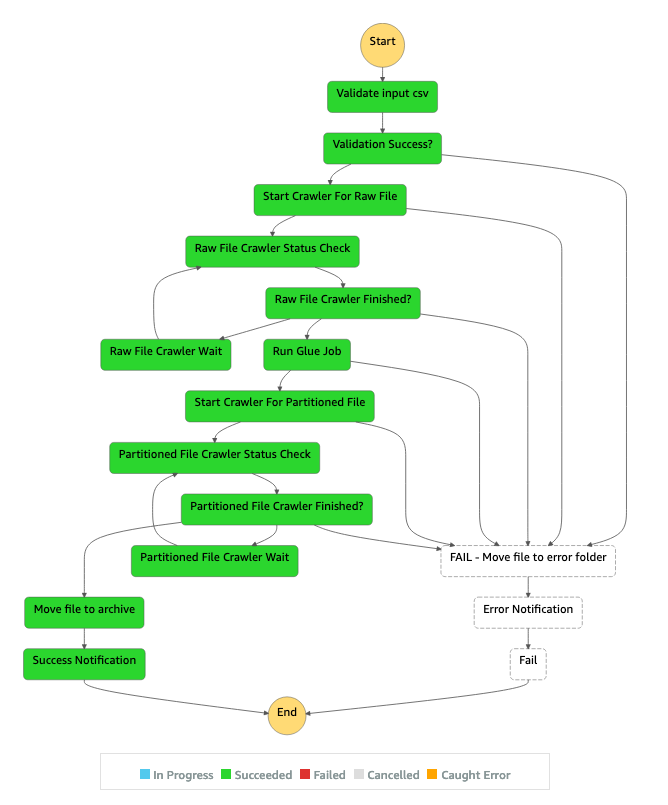
다음 다이어그램은 AWS Step Functions Inspector 패널에서 입력 검증 오류로 인해 실패한 ETL 파이프라인에 대한 Step Functions 워크플로를 보여줍니다.

