기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
AWS 최신 데이터 아키텍처
이 가이드에서는에서 데이터 전략 프레임워크를 구현하는 방법을 설명하지 않습니다 AWS. 이는 AWS 설명서, 블로그 게시물 및 기타 가이드에서 다루는 광범위한 주제입니다(리소스 섹션 참조). 그러나 다음 다이어그램은 대략적인 개요를 제공합니다. 에서 최신 데이터 아키텍처 AWS의 주요 구성 요소를 설명하고 로드맵에 있을 수 있는 대부분의 서비스를 다룹니다.
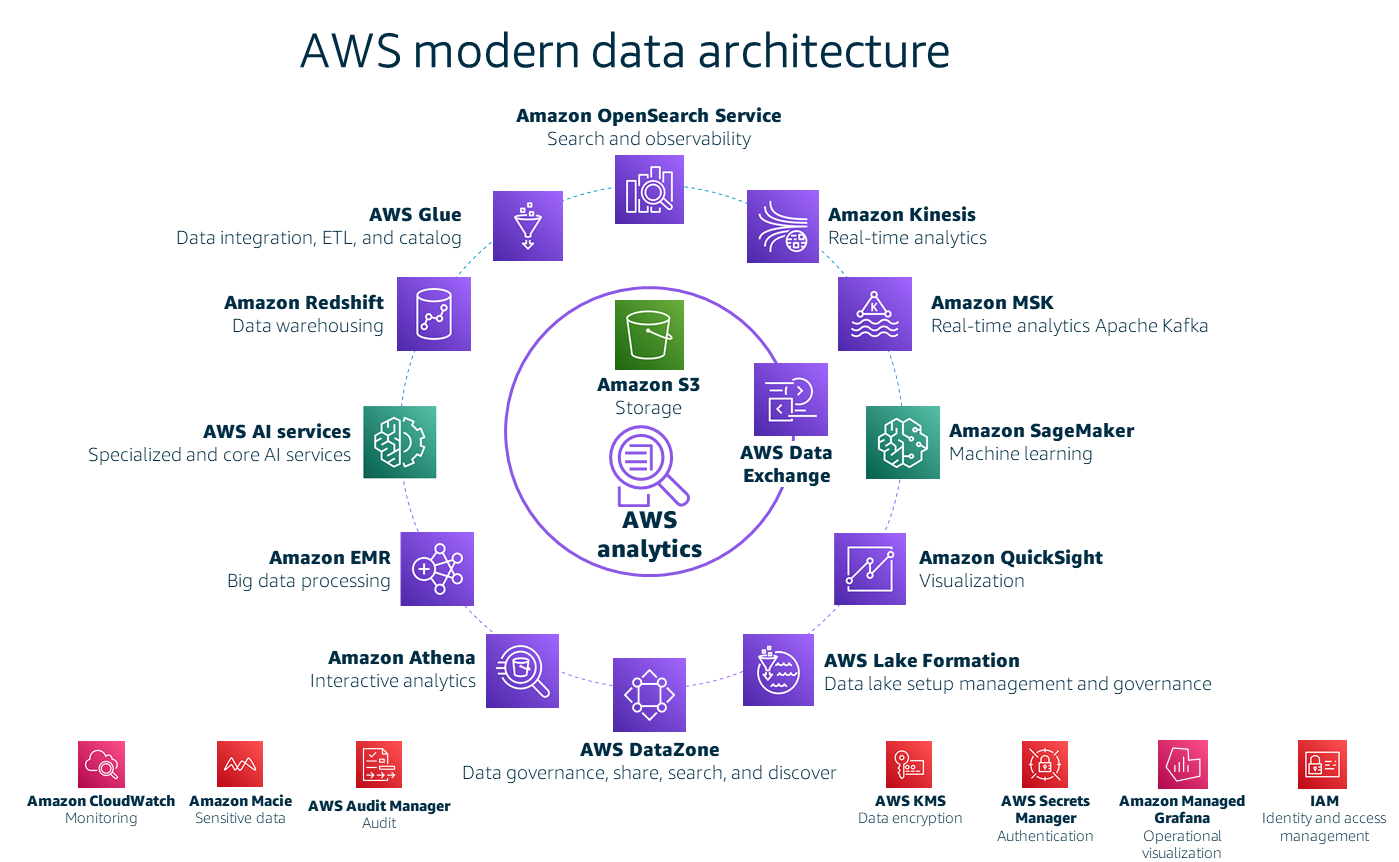
이 아키텍처의 주요 구성 요소는 앞에서 설명한 최신 데이터 전략의 기술 원칙을 지원합니다.
-
통합되고 비용 효율적이며 확장 가능한 스토리지 계층을 사용하면 모든 데이터 생산자와 소비자가 데이터와 상호 작용할 수 있는 기술적 기능을 갖게 됩니다.
Amazon Simple Storage Service(Amazon S3)
는 저렴한 비용으로 통합, 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. -
보안은 필수입니다. 데이터 개인 정보 보호 규칙을 적용하고, 암호화로 데이터 보호를 제공하고, 감사를 활성화하고, 자동화된 규정 준수를 제공합니다.
데이터 프라이버시, 보호 및 규정 준수를 자동화된 방식으로 적용하고 감사를 활성화하려면 AWS Key Management Service (AWS KMS)
, AWS Identity and Access Management (IAM) , AWS Audit Manager , 및 Amazon Macie AWS Secrets Manager 를 사용할 수 있습니다. -
데이터를 관리하여 회사 간에 공유합니다. 사용자가 필요한 데이터를 찾고 사용할 수 있도록 고유한 데이터 카탈로그와 비즈니스 용어집을 제공합니다.
AWS Lake Formation
는 데이터를 관리하고 회사 전체에서 공유할 수 있도록 지원합니다. 또한 Amazon DataZone (미리 보기)을 사용하여에 고유한 데이터 카탈로그AWS Glue 와 비즈니스 용어집을 생성하여 직원이 필요한 데이터를 찾을 수 있습니다. -
올바른 작업에 적합한 서비스를 선택합니다. 구성 요소를 선택할 때 기능, 확장성, 데이터 지연 시간, 서비스 실행에 필요한 노력, 복원력, 통합 및 자동화를 고려합니다.
Amazon Athena
, Amazon EMR , AWS Glue , Amazon OpenSearch Service , Amazon Kinesis , Amazon Redshift , Amazon Managed Streaming for Apache Kafka(Amazon MSK) 및 Amazon QuickSight 을 고려하여 작업을 관리할 수 있습니다. 예를 들어 Kinesis 또는 Amazon를 사용하여 실시간 스트리밍MSK, Amazon EMR 또는를 사용하여 데이터 처리 AWS Glue, OpenSearch Service를 사용하여 검색, Athena를 사용하여 임시 쿼리, Amazon Redshift를 사용하여 데이터 웨어하우징을 수행할 수 있습니다. -
인공 지능(AI) 및 기계 학습(ML)을 사용합니다.
AWS AI 서비스
에서 인공 지능 사용을 활성화하고 Amazon SageMaker AI 에서 기계 학습을 활성화할 수 있습니다. -
비즈니스 인력을 위한 추상화와 함께 데이터 리터러시 및 도구를 제공합니다.
데이터 리터러시, 도구 및 추상화를 제공하는 프로세스는 아키텍처의 일부가 아니지만 Amazon DataZone
(미리 보기), AWS Lake Formation 및 Amazon QuickSight 을 데이터 추상화 도구로 사용할 수 있습니다. -
데이터 이니셔티브의 가설을 테스트하고 결과를 측정합니다.
Amazon OpenSearch Service
대시보드 또는 Amazon QuickSight 을 사용하여 비즈니스 성과 지표 및 테스트 결과를 처리하고 가설을 검증할 수 있습니다.
다양한 사용 사례에 대한 샘플 아키텍처 예제는 AWS 아키텍처 센터
