기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
사용자 정의 함수 최적화
사용자 정의 함수 (UDFs) 및 RDD.map 에서는 PySpark 종종 성능이 크게 저하됩니다. 이는 Spark의 기본 Scala 구현에서 Python 코드를 정확하게 표현하는 데 필요한 오버헤드 때문입니다.
다음 다이어그램은 작업 아키텍처를 보여줍니다. PySpark 를 사용하면 PySpark Spark 드라이버가 Py4J 라이브러리를 사용하여 Python에서 Java 메서드를 호출합니다. Spark SQL 또는 DataFrame 내장 함수를 호출할 때 함수는 최적화된 실행 계획을 JVM 사용하여 각 실행기에서 실행되므로 Python과 Scala 간에 성능 차이가 거의 없습니다.
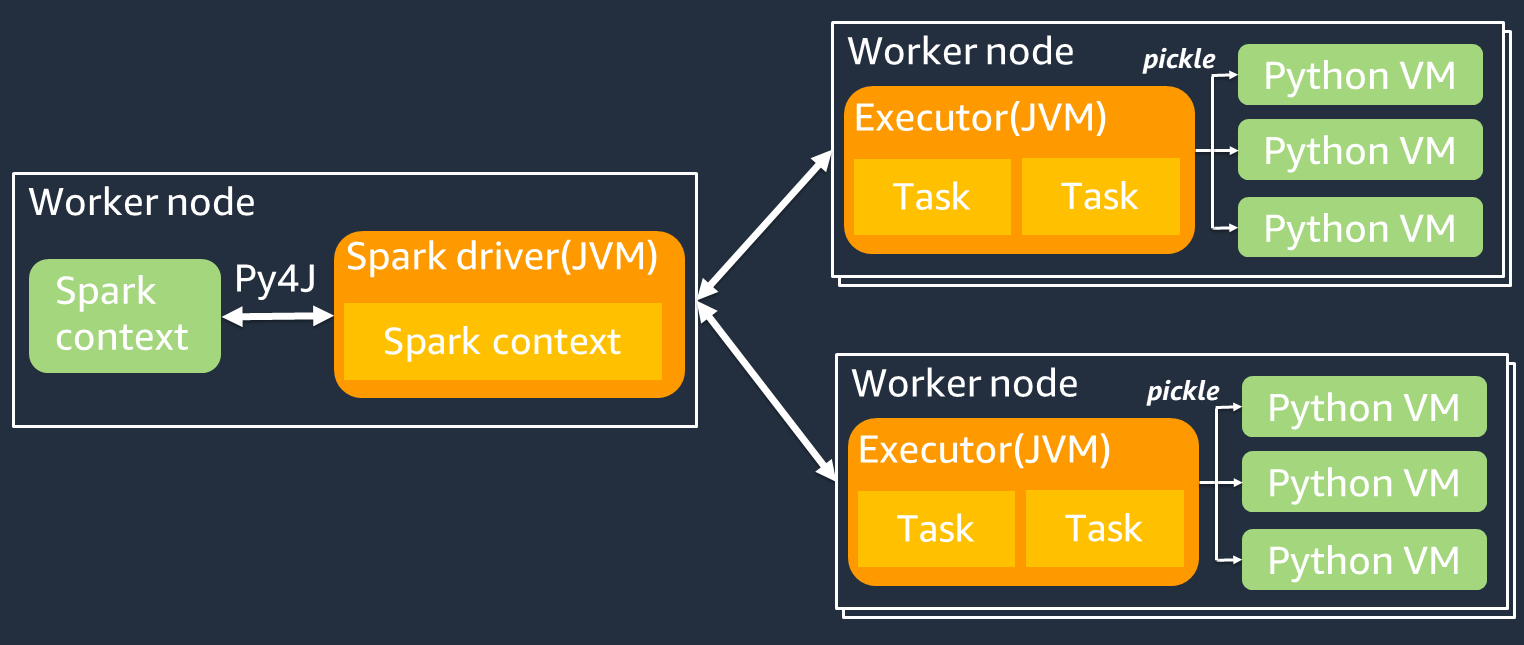
를 사용하는 것과 같이 자체 Python 로직을 사용하는 map/ mapPartitions/ udf 경우 작업은 Python 런타임 환경에서 실행됩니다. 두 환경을 관리하면 오버헤드 비용이 발생합니다. 또한 JVM 런타임 환경의 내장 함수에서 사용하려면 메모리의 데이터를 변환해야 합니다. Pickle은 Python 런타임과 JVM Python 런타임 간의 교환에 기본적으로 사용되는 직렬화 형식입니다. 하지만 이 직렬화 및 역직렬화 비용은 매우 높기 때문에 Java나 Scala로 UDFs 작성하는 것이 Python보다 빠릅니다. UDFs
직렬화 및 역직렬화 오버헤드를 피하려면 다음 사항을 고려하세요. PySpark
-
내장 Spark SQL 함수 사용 — 자체 함수 UDF 또는 맵 함수를 Spark 또는 내장 함수로 대체해 보세요. SQL DataFrame Spark SQL 또는 DataFrame 내장 함수를 실행할 때는 각 실행기에서 작업을 처리하기 때문에 Python과 Scala의 성능 차이는 거의 없습니다. JVM
-
Scala 또는 Java로 구현 UDFs — Java 또는 UDF Scala로 작성된 함수는 에서 실행되므로 사용을 고려해 보십시오. JVM
-
벡터화된 워크로드에는 Apache Arrow 기반 사용 — 화살표 기반 사용을 UDFs 고려해 보세요. UDFs 이 기능을 벡터라이즈드 (Pandas) 라고도 합니다. UDF UDF Apache Arrow는
Python 프로세스 간에 데이터를 효율적으로 전송하는 데 사용할 AWS Glue 수 있는 언어에 구애받지 않는 인메모리 데이터 형식입니다. JVM 이것은 현재 Pandas 또는 NumPy 데이터를 사용하는 Python 사용자에게 가장 유용합니다. 화살표는 열 형식 (벡터화) 형식입니다. 사용법은 자동으로 이루어지지 않으므로 최대한 활용하고 호환성을 보장하기 위해 구성이나 코드를 약간 변경해야 할 수 있습니다. 자세한 내용 및 제한 사항은 의 Apache Arrow를 참조하십시오. PySpark
다음 예제는 표준 UDF Python의 기본 증분을 Vectorized와 Spark의 기본 UDF 증분을 비교합니다. SQL
표준 Python UDF
예제 시간은 3.20 (초) 입니다.
예제 코드
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
실행 계획
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
벡터화 UDF
예제 시간은 0.59 (초) 입니다.
벡터화된 UDF 결과는 이전 예제보다 5배 더 빠릅니다. UDF Physical Plan확인해보면 이 애플리케이션이 Apache ArrowEvalPython Arrow로 벡터화되었음을 알 수 있습니다. Vectorized를 활성화하려면 코드에 지정해야 UDF 합니다. spark.sql.execution.arrow.pyspark.enabled = true
예제 코드
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
실행 계획
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
스파크 SQL
예제 시간은 0.087 (초) 입니다.
SQLSpark는 Vectorized보다 훨씬 빠릅니다. UDF Python 런타임 없이 JVM 각 실행기에서 작업이 실행되기 때문입니다. 를 내장 함수로 대체할 수 UDF 있다면 그렇게 하는 것이 좋습니다.
예제 코드
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
판다를 빅데이터에 활용하기
이미 판다에
