기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 스캔량을 줄이십시오.
시작하려면 필요한 데이터만 로드하는 것이 좋습니다. 각 데이터 소스에 대해 Spark 클러스터에 로드되는 데이터의 양을 줄이는 것만으로도 성능을 개선할 수 있습니다. 이 접근 방식이 적절한지 평가하려면 다음 측정치를 사용하세요.
Spark UI 섹션에 설명된 대로 CloudWatch지표에서 Amazon S3의 읽은 바이트를 확인하고 Spark UI에서 자세한 내용을 확인할 수 있습니다.
CloudWatch 메트릭스
Amazon S3의 대략적인 읽기 크기는 ETL데이터 이동 (바이트) 에서 확인할 수 있습니다. 이 지표는 이전 보고서 이후 모든 실행자가 Amazon S3에서 읽은 바이트 수를 보여줍니다. 이를 사용하여 Amazon S3의 ETL 데이터 이동을 모니터링하고 읽기와 외부 데이터 소스의 수집 속도를 비교할 수 있습니다.
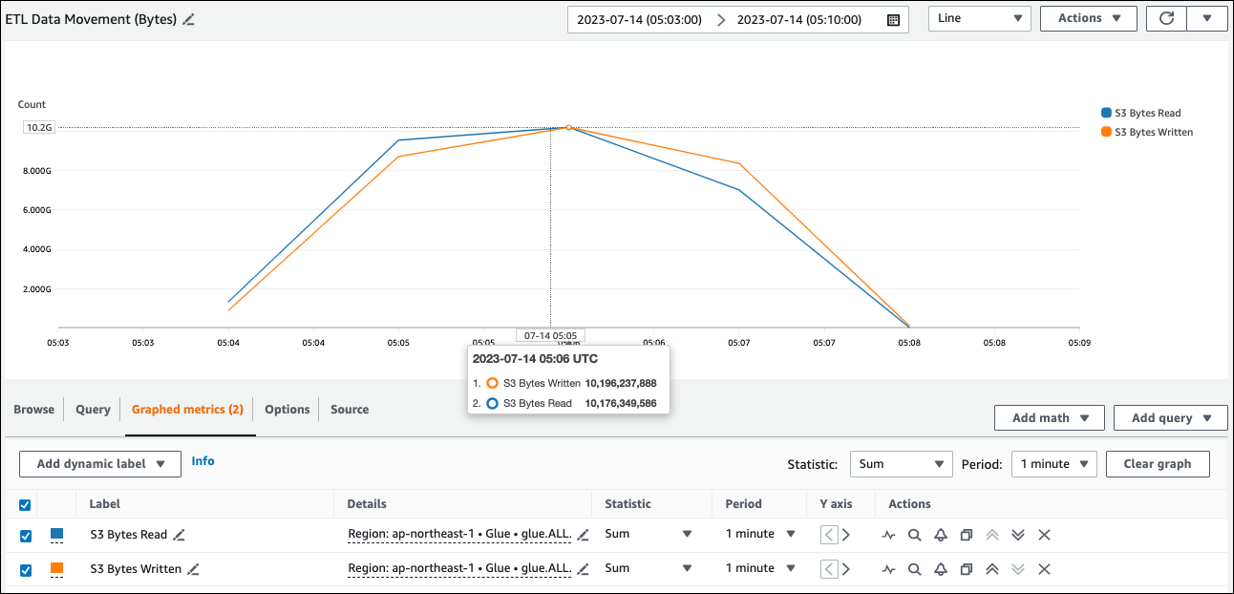
S3바이트 읽기 데이터 포인트가 예상보다 큰 경우 다음 해결 방법을 고려해 보십시오.
Spark UI
Spark UI의 AWS Glue 스테이지 탭에서 입력 및 출력 크기를 확인할 수 있습니다. 다음 예제에서 스테이지 2는 47.4GiB 입력과 47.7GiB 출력을 읽고, 스테이지 5에서는 61.2MiB 입력과 56.6MiB 출력을 읽습니다.

작업에서 Spark SQL 또는 DataFrame 접근 방식을 사용하는 경우 /D 탭에 이러한 단계에 대한 추가 통계가 표시됩니다. AWS Glue SQL ataFrame 이 경우 2단계에서는 읽은 파일 수: 430, 읽은 파일 크기: 47.4 GiB, 출력 행 수: 160,796,570을 보여줍니다.
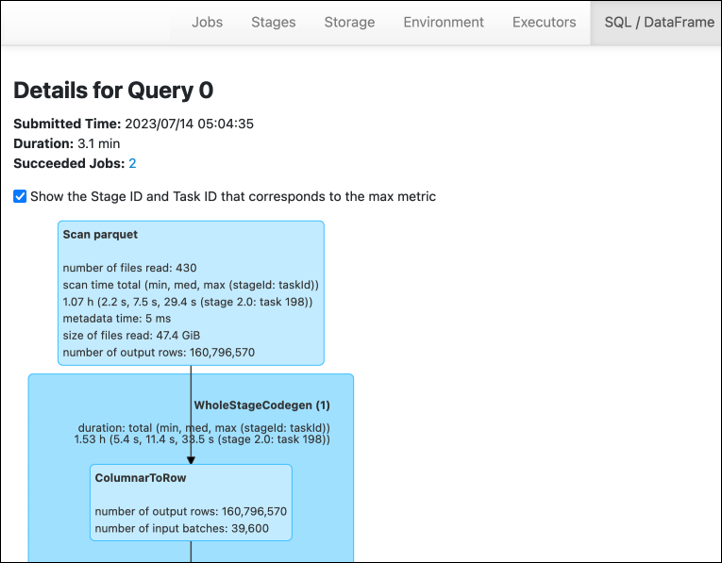
읽고 있는 데이터와 사용 중인 데이터 간에 크기가 크게 차이가 나는 경우 다음 해결 방법을 시도해 보십시오.
Amazon S3
Amazon S3에서 읽을 때 작업에 로드되는 데이터의 양을 줄이려면 데이터 세트의 파일 크기, 압축, 파일 형식 및 파일 레이아웃 (파티션) 을 고려하십시오. AWS Glue Spark 작업은 원시 데이터에 주로 사용되지만 효율적인 분산 처리를 위해서는 데이터 소스 형식의 기능을 검사해야 합니다. ETL
-
파일 크기 — 입력과 출력의 파일 크기를 적당한 범위 (예: 128MB) 이내로 유지하는 것이 좋습니다. 너무 작은 파일과 너무 큰 파일은 문제를 일으킬 수 있습니다.
작은 파일이 많으면 다음과 같은 문제가 발생합니다.
-
동일한 양의 데이터를 저장하는 소수의 객체에 비해 많은 객체를 요청 (예:
ListGet, 또는Head) 하려면 오버헤드가 필요하기 때문에 Amazon S3에서 네트워크 I/O 부하가 심합니다. -
Spark 드라이버에 I/O 및 처리 부하가 심하면 파티션과 작업이 많이 생성되고 병렬 처리가 과도하게 발생합니다.
반면, 파일 유형이 분할할 수 없고 (예: gzip) 파일이 너무 크면 Spark 응용 프로그램은 단일 작업으로 전체 파일 읽기가 완료될 때까지 기다려야 합니다.
작은 파일마다 Apache Spark 태스크를 생성할 때 발생하는 과도한 병렬 처리를 줄이려면 파일 그룹화를 사용하십시오. DynamicFrames 이 방법을 사용하면 Spark 드라이버에서 예외가 발생할 가능성이 줄어듭니다. OOM 파일 그룹화를 구성하려면
groupFiles및groupSize매개변수를 설정합니다. 다음 코드 예제에서는 ETL 스크립트에서 이러한 매개 변수와 함께 를 사용합니다. AWS Glue DynamicFrame APIdyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
압축 - S3 객체의 크기가 수백 메가바이트인 경우 압축을 고려해 보십시오. 압축 형식은 다양하며 크게 두 가지 유형으로 분류할 수 있습니다.
-
gzip과 같이 분할할 수 없는 압축 형식의 경우 작업자 한 명이 전체 파일의 압축을 풀어야 합니다.
-
bzip2 또는 LZO (인덱싱됨) 과 같은 분할 가능한 압축 형식을 사용하면 파일을 부분적으로 압축 해제하여 병렬화할 수 있습니다.
Spark (및 기타 일반적인 분산 처리 엔진) 의 경우 소스 데이터 파일을 엔진이 병렬로 처리할 수 있는 청크로 분할합니다. 이러한 유닛을 흔히 스플릿이라고 합니다. 데이터가 분할 가능한 형식이 되면 최적화된 AWS Glue 리더는 에 특정 블록만 검색하는
Range옵션을 제공하여 S3 객체에서GetObjectAPI 분할을 검색할 수 있습니다. 이 방법이 실제로 어떻게 작동하는지 보려면 다음 다이어그램을 살펴보십시오.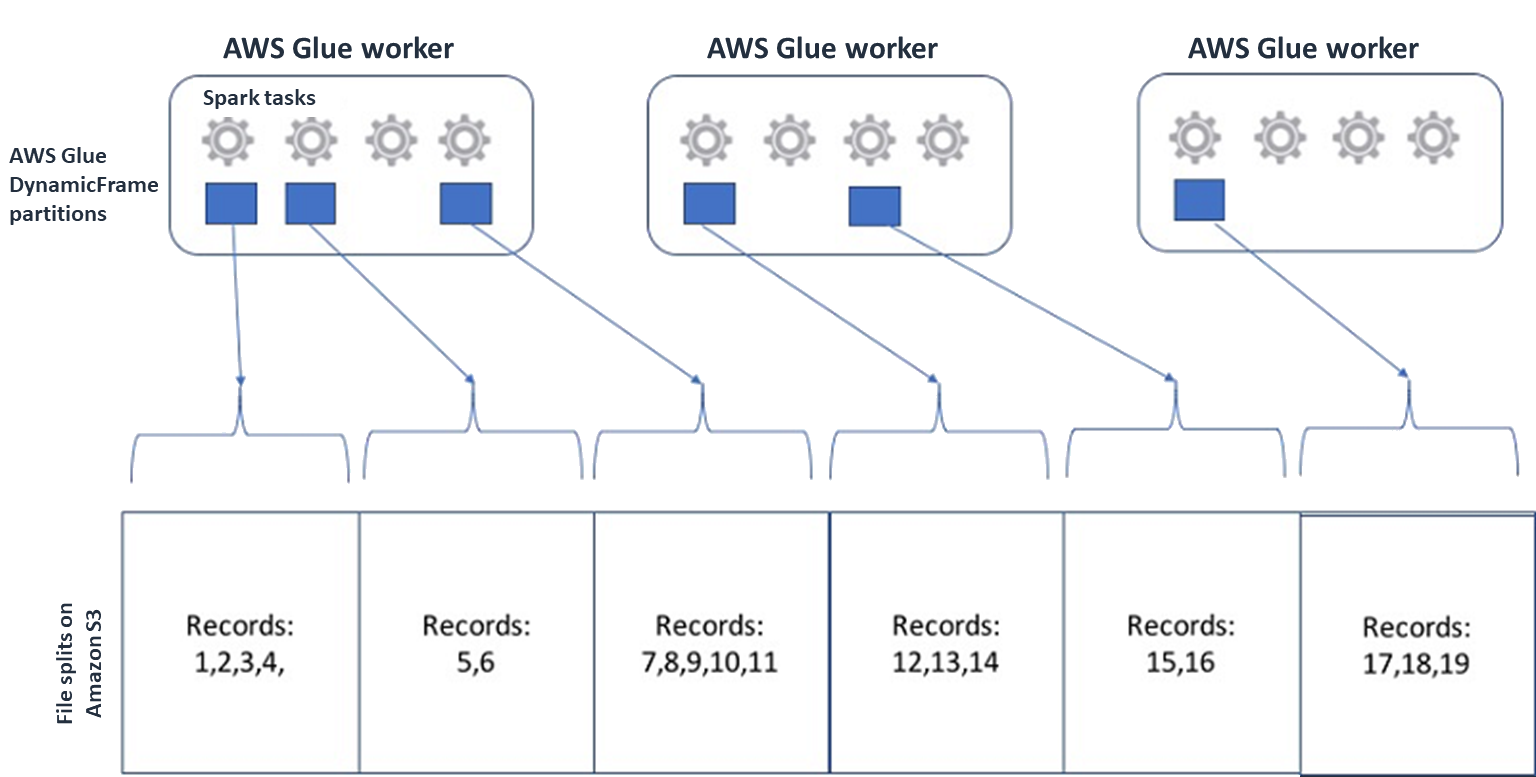
파일 크기가 최적이거나 파일을 분할할 수 있는 한 압축된 데이터를 사용하면 애플리케이션 속도를 크게 높일 수 있습니다. 데이터 크기가 작을수록 Amazon S3에서 스캔한 데이터와 Amazon S3에서 Spark 클러스터로 전달되는 네트워크 트래픽이 줄어듭니다. 반면, 데이터를 압축하고 압축 해제하려면 더 많은 CPU 작업이 필요합니다. 필요한 컴퓨팅 양은 압축 알고리즘의 압축률에 따라 조정됩니다. 분할 가능한 압축 형식을 선택할 때는 이 절충점을 고려하십시오.
참고
gzip 파일은 일반적으로 분할할 수 없지만 gzip으로 개별 파켓 블록을 압축하여 해당 블록을 병렬화할 수 있습니다.
-
-
파일 형식 — 열 형식을 사용합니다. 아파치 파켓과 아파치는
널리 사용되는 컬럼형 데이터 ORC 형식입니다 . 열 기반 압축을 사용하고 데이터 유형에 따라 각 열을 인코딩 및 압축하여 데이터를 효율적으로 파켓하고 ORC 저장합니다. Parquet 인코딩에 대한 자세한 내용은 Parquet 인코딩 정의를 참조하십시오. 파켓 파일도 분할할 수 있습니다. 컬럼 형식은 값을 열별로 그룹화하고 블록으로 함께 저장합니다. 열 형식 사용 시 사용하지 않을 열에 해당하는 데이터 블록을 건너뛸 수 있습니다. Spark 애플리케이션은 필요한 열만 검색할 수 있습니다. 일반적으로 압축률이 높거나 데이터 블록을 건너뛰면 Amazon S3에서 읽는 바이트 수가 줄어들어 성능이 향상됩니다. 또한 두 형식 모두 I/O를 줄이기 위한 다음과 같은 푸시다운 접근 방식을 지원합니다.
-
프로젝션 푸시다운 — 프로젝션 푸시다운은 애플리케이션에 지정된 열만 검색하는 기법입니다. 다음 예와 같이 Spark 애플리케이션에서 열을 지정합니다.
-
DataFrame 예:
df.select("star_rating") -
스파크 SQL 예시:
spark.sql("select start_rating from <table>")
-
-
프리디케이트 푸시다운 — 프리디케이트 푸시다운은 AND 조항을 효율적으로 처리하기 위한 기법입니다.
WHEREGROUP BY두 형식 모두 열 값을 나타내는 데이터 블록을 포함합니다. 각 블록에는 최대값 및 최소값과 같은 블록에 대한 통계가 들어 있습니다. Spark는 이러한 통계를 사용하여 애플리케이션에서 사용되는 필터 값에 따라 블록을 읽을지 아니면 건너뛰어야 하는지를 결정할 수 있습니다. 이 기능을 사용하려면 다음 예와 같이 조건에 필터를 더 추가하세요.-
DataFrame 예:
df.select("star_rating").filter("star_rating < 2") -
스파크 SQL 예시:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
파일 레이아웃 — 데이터 사용 방식에 따라 서로 다른 경로의 객체에 S3 데이터를 저장하면 관련 데이터를 효율적으로 검색할 수 있습니다. 자세한 내용은 Amazon S3 설명서의 접두사를 사용한 객체 구성을 참조하십시오. AWS Glue Amazon S3 경로를 기준으로 데이터를 분할하여 키와 값을 Amazon S3 접두사에
key=value같은 형식으로 저장할 수 있습니다. 데이터를 분할하면 각 다운스트림 분석 애플리케이션에서 스캔하는 데이터의 양을 제한하여 성능을 개선하고 비용을 절감할 수 있습니다. 자세한 내용은 출력을 위한 ETL 파티션 관리를 참조하십시오. AWS Glue파티셔닝은 테이블을 여러 부분으로 나누고 다음 예와 같이 연도, 월, 일과 같은 열 값을 기준으로 그룹화된 파일에 관련 데이터를 보관합니다.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...의 테이블을 사용하여 데이터세트를 모델링하여 데이터셋의 파티션을 정의할 수 있습니다. AWS Glue Data Catalog그런 다음 다음과 같이 파티션 프루닝을 사용하여 데이터 스캔량을 제한할 수 있습니다.
-
For AWS Glue DynamicFrame, 설정
push_down_predicate(또는catalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
DataFrameSpark의 경우 파티션을 프루닝할 고정 경로를 설정합니다.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Spark의 SQL 경우 where 절을 설정하여 데이터 카탈로그에서 파티션을 정리할 수 있습니다.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
를 사용하여 데이터를 쓸 때 날짜별로 파티션을 AWS Glue나누려면 다음과 DataFrame 같이 열에 날짜 정보를 포함하여 DynamicFrame or partitionBy()
를 설정합니다 partitionKeys. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
이렇게 하면 출력 데이터 소비자의 성능이 향상될 수 있습니다.
입력 데이터세트를 생성하는 파이프라인을 변경할 수 있는 권한이 없는 경우 파티셔닝은 옵션이 아닙니다. 대신 글로브 패턴을 사용하여 불필요한 S3 경로를 제외할 수 있습니다. 가져올 때 제외를 설정하십시오. DynamicFrame 예를 들어, 다음 코드는 2023년에 01~09개월의 날짜를 제외합니다.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )데이터 카탈로그의 테이블 속성에서 제외를 설정할 수도 있습니다.
-
키:
exclusions -
값:
["**year=2023/month=0[1-9]/**"]
-
-
-
너무 많은 Amazon S3 파티션 — 수천 개의 값이 있는 ID 열과 같이 광범위한 값을 포함하는 열로 Amazon S3 데이터를 분할하지 마십시오. 가능한 파티션 수는 파티션을 나눈 모든 필드를 곱하기 때문에 이렇게 하면 버킷의 파티션 수가 크게 늘어날 수 있습니다. 파티션이 너무 많으면 다음과 같은 문제가 발생할 수 있습니다.
-
데이터 카탈로그에서 파티션 메타데이터를 검색하는 데 걸리는 지연 시간 증가
-
더 많은 Amazon S3 API 요청 (
ListGet, 및Head) 이 필요한 소형 파일 수 증가
예를 들어
partitionKeys,partitionBy또는 에서 날짜 유형을 설정하는 경우 날짜 수준yyyy/mm/dd파티셔닝은 많은 사용 사례에 적합합니다. 하지만 너무 많은 파티션이 생성되어 전체적으로 성능에 부정적인 영향을 미칠yyyy/mm/dd/<ID>수 있습니다.반면 실시간 처리 애플리케이션과 같은 일부 사용 사례에는 다음과 같은 파티션이 많이 필요합니다
yyyy/mm/dd/hh. 사용 사례에 대규모 파티션이 필요한 경우 AWS Glue 파티션 인덱스를 사용하여 데이터 카탈로그에서 파티션 메타데이터를 검색하는 데 걸리는 지연 시간을 줄이는 것이 좋습니다. -
데이터베이스 및 JDBC
데이터베이스에서 정보를 검색할 때 데이터 스캔을 줄이려면 쿼리에 where 술어 (또는 절) 를 지정할 수 있습니다. SQL SQL인터페이스를 제공하지 않는 데이터베이스는 쿼리 또는 필터링을 위한 자체 메커니즘을 제공합니다.
Java 데이터베이스 연결 (JDBC) 연결을 사용하는 경우 다음 매개 변수에 대한 where 절과 함께 선택 쿼리를 제공하십시오.
-
의 DynamicFrame 경우 sampleQuery옵션을 사용하십시오. 를 사용하는
create_dynamic_frame.from_catalog경우 다음과 같이additional_options인수를 구성하십시오.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )using create_dynamic_frame.from_options경우 다음과 같이connection_options인수를 구성하십시오.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
의 DataFrame 경우 쿼리
옵션을 사용하십시오. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Amazon Redshift의 경우 AWS Glue 4.0 이상을 사용하여 Amazon Redshift Spark 커넥터의 푸시다운 지원을 활용하십시오.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
다른 데이터베이스의 경우 해당 데이터베이스의 설명서를 참조하십시오.
AWS Glue 옵션
