Amazon Redshift는 2026년 6월 30일 이후에 Python UDF 사용을 더 이상 지원하지 않습니다. 해당 조치는 단계적으로 시행될 예정입니다. Python 수명 종료 및 마이그레이션 옵션에 대한 자세한 내용은 2025년 6월 30일에 게시된 블로그 게시물
Amazon EMR에서 데이터 로드
COPY 명령을 사용하면 클러스터의 Hadoop 분산 파일 시스템(HDFS)에 고정 너비 파일, 문자로 구분된 파일, CSV 파일 또는 JSON 형식 파일 형식으로 텍스트 파일을 쓰도록 구성된 Amazon EMR 클러스터에서 병렬로 데이터를 로드할 수 있습니다.
Amazon EMR에서 데이터를 로드하기 위한 프로세스
이 섹션에서는 Amazon EMR 클러스터에서 데이터를 로드하는 프로세스를 단계별로 살펴봅니다. 다음 섹션에서는 각 단계에서 해야 할 일을 자세히 설명합니다.
-
Amazon EMR 클러스터를 생성하고 Amazon Redshift COPY 명령을 실행하는 사용자에게는 필요한 권한이 있어야 합니다.
-
Hadoop 분산 파일 시스템(HDFS)으로 텍스트 파일을 출력하도록 클러스터를 구성합니다. Amazon EMR 클러스터 ID와 클러스터의 메인 퍼블릭 DNS(클러스터를 호스팅하는 Amazon EC2 인스턴스의 엔드포인트)가 필요합니다.
-
3단계: Amazon Redshift 클러스터 퍼블릭 키와 클러스터 노드 IP 주소 검색
퍼블릭 키를 사용하면 Amazon Redshift 클러스터 노드가 호스트와의 SSH 연결을 설정할 수 있습니다. 각 클러스터 노드의 IP 주소를 사용하여 이러한 IP 주소를 사용하는 Amazon Redshift 클러스터로부터의 액세스를 허용하도록 호스트 보안 그룹을 구성합니다.
-
4단계: 각각의 Amazon EC2 호스트의 권한 부여된 키 파일에 Amazon Redshift 클러스터 퍼블릭 키 추가
호스트가 Amazon Redshift 클러스터를 인식하고 SSH 연결을 수락하도록 호스트의 권한 부여된 키 파일에 Amazon Redshift 클러스터 퍼블릭 키를 추가합니다.
-
5단계: Amazon Redshift 클러스터의 모든 IP 주소를 수락하도록 호스트 구성
Amazon EMR 인스턴스의 보안 그룹을 수정하여 Amazon Redshift IP 주소를 수락하도록 입력 규칙을 추가합니다.
-
Amazon Redshift 데이터베이스에서 COPY 명령을 실행하여 Amazon Redshift 테이블로 데이터를 로드합니다.
1단계: IAM 권한 구성
Amazon EMR 클러스터를 생성하고 Amazon Redshift COPY 명령을 실행하는 사용자에게는 필요한 권한이 있어야 합니다.
IAM 권한을 구성하려면
-
Amazon EMR 클러스터를 생성할 사용자에 대해 다음의 권한을 추가합니다.
ec2:DescribeSecurityGroups ec2:RevokeSecurityGroupIngress ec2:AuthorizeSecurityGroupIngress redshift:DescribeClusters -
COPY 명령을 실행할 IAM 역할 또는 사용자에 대해 다음의 권한을 추가합니다.
elasticmapreduce:ListInstances -
다음 권한을 Amazon EMR 클러스터의 IAM 역할에 추가합니다.
redshift:DescribeClusters
2단계: Amazon EMR 클러스터 생성
COPY 명령은 Amazon EMR Hadoop 분산 파일 시스템(HDFS)에서 데이터를 로드합니다. Amazon EMR 클러스터를 생성할 때 클러스터의 HDFS로 데이터 파일을 출력하도록 클러스터를 구성합니다.
Amazon EMR 클러스터를 생성하려면
-
Amazon Redshift 클러스터와 동일한 AWS 리전에 Amazon EMR 클러스터를 생성합니다.
Amazon Redshift 클러스터가 VPC에 있는 경우 Amazon EMR 클러스터는 동일한 VPC 그룹에 있어야 합니다. Amazon Redshift 클러스터가 EC2-Classic 모드를 사용하는 경우(즉, VPC에 없는 경우), Amazon EMR 클러스터도 EC2-Classic 모드를 사용해야 합니다. 자세한 내용은 Amazon Redshift 관리 가이드의 Virtual Private Cloud(VPC)의 클러스터 관리 섹션을 참조하세요.
-
클러스터의 HDFS로 데이터 파일을 출력하도록 클러스터를 구성합니다. HDFS 파일 이름에는 별표(*)나 물음표(?)가 포함되면 안 됩니다.
중요
파일 이름에 별표(*)나 물음표(?)가 있으면 안 됩니다.
-
COPY 명령이 실행되는 동안 클러스터를 계속 사용할 수 있도록 Amazon EMR 클러스터 구성에서 자동 종료(Auto-terminate) 옵션에 대해 아니요(No)를 지정합니다.
중요
COPY가 완료되기 전에 변경되거나 삭제된 데이터 파일이 있다면 예상치 못한 결과가 나오거나 COPY 작업이 실패할 수 있습니다.
-
클러스터 ID와 메인 퍼블릭 DNS(클러스터를 호스팅하는 Amazon EC2 인스턴스의 엔드포인트)를 적어 둡니다. 이후 단계에서 이 정보를 사용하게 됩니다.
3단계: Amazon Redshift 클러스터 퍼블릭 키와 클러스터 노드 IP 주소 검색
각 클러스터 노드의 IP 주소를 사용하여 이러한 IP 주소를 사용하는 Amazon Redshift 클러스터로부터의 액세스를 허용하도록 호스트 보안 그룹을 구성합니다.
콘솔을 사용하여 Amazon Redshift 클러스터 퍼블릭 키와 클러스터의 클러스터 노드 IP 주소를 검색하려면
-
Amazon Redshift 관리 콘솔에 액세스합니다.
-
탐색 창에서 Clusters(클러스터) 링크를 선택합니다.
-
목록에서 해당 인스턴스를 선택합니다.
-
SSH 처리 설정 그룹을 찾습니다.
클러스터 퍼블릭 키와 노드 IP 주소를 적어 둡니다. 이후 단계에서 사용하게 됩니다.
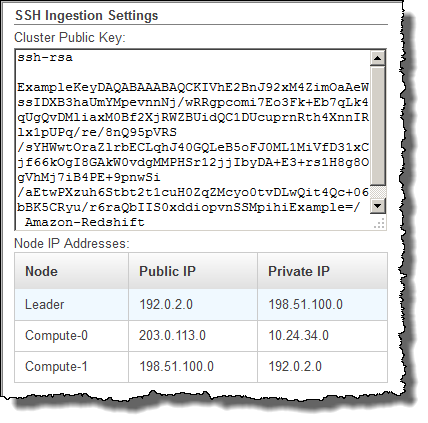
3단계의 프라이빗 IP 주소를 사용하여 Amazon Redshift로부터의 연결을 수락하도록 Amazon EC2 호스트를 구성합니다.
Amazon Redshift CLI를 사용하여 클러스터 퍼블릭 키와 클러스터의 클러스터 노드 IP 주소를 검색하려면 describe-clusters 명령을 실행합니다. 예:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
응답에는 ClusterPublicKey 값과 프라이빗 및 퍼블릭 IP 주소 목록이 포함되며, 다음과 비슷합니다.
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
Amazon Redshift API를 사용하여 클러스터 퍼블릭 키와 클러스터의 클러스터 노드 IP 주소를 검색하려면 DescribeClusters 작업을 사용합니다. 자세한 내용은 Amazon Redshift CLI Guide의 describe-clusters 또는 Amazon Redshift API Guide의 DescribeClusters 섹션을 참조하세요.
4단계: 각각의 Amazon EC2 호스트의 권한 부여된 키 파일에 Amazon Redshift 클러스터 퍼블릭 키 추가
호스트가 Amazon Redshift를 인식하고 SSH 연결을 수락하도록 모든 Amazon EMR 클러스터 노드에 대해 각 호스트의 권한 부여된 키 파일에 클러스터 퍼블릭 키를 추가합니다.
호스트의 권한 부여된 키 파일에 Amazon Redshift 클러스터 퍼블릭 키를 추가하려면
-
SSH 연결을 사용하여 호스트에 액세스합니다.
SSH를 사용하여 인스턴스에 연결에 대한 자세한 내용은 Amazon EC2 User Guide의 Connect to Your Instance 섹션을 참조하세요.
-
콘솔 또는 CLI 응답 텍스트에서 Amazon Redshift 퍼블릭 키를 복사합니다.
-
퍼블릭 키의 내용을 복사하여 호스트의
/home/<ssh_username>/.ssh/authorized_keys파일에 붙여 넣습니다. 접두사 "ssh-rsa"와 접미사Amazon-Redshift"를 포함하여 완전한 문자열을 포함시킵니다. 예:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
5단계: Amazon Redshift 클러스터의 모든 IP 주소를 수락하도록 호스트 구성
호스트 인스턴스로의 인바운드 트래픽을 허용하려면 보안 그룹을 편집하고 각각의 Amazon Redshift 클러스터 노드에 하나의 Inbound 규칙을 추가합니다. 유형에서 포트 22의 TCP 프로토콜이 포함된 SSH를 선택합니다. 소스에서 3단계: Amazon Redshift 클러스터 퍼블릭 키와 클러스터 노드 IP 주소 검색에서 가져온 Amazon Redshift 클러스터 노드 프라이빗 IP 주소를 입력합니다. Amazon EC2 보안 그룹에 규칙 추가에 대한 자세한 내용은 Amazon EC2 User Guide의 Authorizing Inbound Traffic for Your Instances 섹션을 참조하세요.
6단계: COPY 명령을 실행하여 데이터 로드
COPY 명령을 실행하여 Amazon EMR 클러스터에 연결하고 데이터를 Amazon Redshift 테이블에 로드합니다. Amazon EMR 클러스터는 COPY 명령이 완료될 때까지 계속 실행되어야 합니다. 예를 들어 자동 종료되도록 클러스터를 구성하지 마세요.
중요
COPY가 완료되기 전에 변경되거나 삭제된 데이터 파일이 있다면 예상치 못한 결과가 나오거나 COPY 작업이 실패할 수 있습니다.
COPY 명령에서 Amazon EMR 클러스터 ID와 HDFS 파일 경로 및 파일 이름을 지정합니다.
COPY sales FROM 'emr://myemrclusterid/myoutput/part*' CREDENTIALS IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
와일드카드 문자 별표( * )와 물음표( ? )를 파일 이름 인수의 일부로 사용할 수 있습니다. 예를 들어 part*는 파일 part-0000, part-0001 등등을 로드합니다. 폴더 이름만 지정하면 COPY가 폴더의 모든 파일을 로드하려고 합니다.
중요
와일드카드 문자를 사용하거나 폴더 이름만을 사용하는 경우, 원치 않는 파일이 로드되지 않는지 확인하세요. 그럴 경우, COPY 명령이 실패합니다. 예를 들어 일부 프로세스에서는 로그 파일이 출력 폴더로 로드되는 경우도 있습니다.
