CONNECT BY 절
계층 구조에서 행 간의 관계를 지정합니다. CONNECT BY를 사용하여 테이블을 자체에 조인하고 계층적 데이터를 처리하여 계층적 순서로 행을 선택할 수 있습니다. 예를 들어 조직도와 목록 데이터를 반복적으로 반복하는 데 사용할 수 있습니다.
계층적 쿼리는 다음 순서로 처리됩니다.
FROM 절에 조인이 있는 경우 조인이 먼저 처리됩니다.
CONNECT BY 절이 평가됩니다.
WHERE 절이 평가됩니다.
구문
[START WITH start_with_conditions] CONNECT BY connect_by_conditions
참고
START 및 CONNECT는 예약어가 아니지만, 쿼리에서 START 및 CONNECT를 테이블 별칭으로 사용하는 경우에는 런타임 시 오류가 발생하지 않도록 구분된 식별자(큰따옴표) 또는 AS를 사용하세요.
SELECT COUNT(*) FROM Employee "start" CONNECT BY PRIOR id = manager_id START WITH name = 'John'
SELECT COUNT(*) FROM Employee AS start CONNECT BY PRIOR id = manager_id START WITH name = 'John'
파라미터
- start_with_conditions
-
계층 구조의 루트 행을 지정하는 조건
- connect_by_conditions
-
계층 구조의 상위 행과 하위 행 간의 관계를 지정하는 조건입니다. 하나 이상의 조건이 부모 행을 참조하는 데 사용되는
PRIOR column = expression -- or expression > PRIOR column
연산자
CONNECT BY 쿼리에서 다음 연산자를 사용할 수 있습니다.
- LEVEL
-
계층 구조에서 현재 행 수준을 반환하는 의사 열입니다. 루트 행에 대해 1, 루트 행의 자식에 대해 2 등을 반환합니다.
- PRIOR
-
계층 구조에서 현재 행의 상위 행에 대한 표현식을 평가하는 단항 연산자입니다.
예시
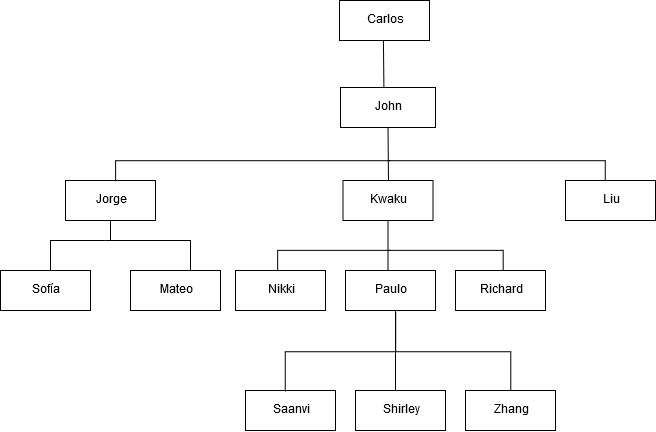
다음 예는 John에게 직간접적으로 보고하는 직원 수를 반환하는 CONNECT BY 쿼리입니다(4단계 미만).
SELECT id, name, manager_id FROM employee WHERE LEVEL < 4 START WITH name = 'John' CONNECT BY PRIOR id = manager_id;
다음은 쿼리 결과입니다.
id name manager_id ------+----------+-------------- 101 John 100 102 Jorge 101 103 Kwaku 101 110 Liu 101 201 Sofía 102 106 Mateo 102 110 Nikki 103 104 Paulo 103 105 Richard 103 120 Saanvi 104 200 Shirley 104 205 Zhang 104
이 예에 대한 테이블 정의는 다음과 같습니다.
CREATE TABLE employee ( id INT, name VARCHAR(20), manager_id INT );
다음은 테이블에 삽입된 행입니다.
INSERT INTO employee(id, name, manager_id) VALUES (100, 'Carlos', null), (101, 'John', 100), (102, 'Jorge', 101), (103, 'Kwaku', 101), (110, 'Liu', 101), (106, 'Mateo', 102), (110, 'Nikki', 103), (104, 'Paulo', 103), (105, 'Richard', 103), (120, 'Saanvi', 104), (200, 'Shirley', 104), (201, 'Sofía', 102), (205, 'Zhang', 104);
다음은 John의 부서의 조직도입니다.