쿼리 계획 단계 검토
EXPLAIN 명령을 실행하면 쿼리 계획의 각 단계를 볼 수 있습니다. 다음 예는 SQL 쿼리를 보여 주며 출력을 설명합니다. 쿼리 계획을 아래에서 위로 읽어보면 쿼리를 실행하는 데 사용한 로직 작업을 개별적으로 확인할 수 있습니다. 자세한 내용은 쿼리 계획 생성 및 해석 섹션을 참조하세요.
explain select eventname, sum(pricepaid) from sales, event where sales.eventid = event.eventid group by eventname order by 2 desc;
XN Merge (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Merge Key: sum(sales.pricepaid) -> XN Network (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Send to leader -> XN Sort (cost=1002815366604.92..1002815366606.36 rows=576 width=27) Sort Key: sum(sales.pricepaid) -> XN HashAggregate (cost=2815366577.07..2815366578.51 rows=576 width=27) -> XN Hash Join DS_BCAST_INNER (cost=109.98..2815365714.80 rows=172456 width=27) Hash Cond: ("outer".eventid = "inner".eventid) -> XN Seq Scan on sales (cost=0.00..1724.56 rows=172456 width=14) -> XN Hash (cost=87.98..87.98 rows=8798 width=21) -> XN Seq Scan on event (cost=0.00..87.98 rows=8798 width=21)
쿼리 계획 생성의 일부로 쿼리 최적화 프로그램은 계획을 스트림, 세그먼트 및 단계로 나눕니다. 쿼리 최적화 프로그램은 컴퓨팅 노드에 데이터 및 쿼리 워크로드를 분산할 준비를 위해 계획을 세분화합니다. 스트림, 세그먼트 및 단계에 대한 자세한 내용은 쿼리 계획 및 실행 워크플로우 섹션을 참조하세요.
다음 그림은 위의 쿼리 및 관련 쿼리 계획을 보여줍니다. Amazon Redshift가 컴퓨팅 노드 조각에 대해 컴파일된 코드를 생성할 때 사용하는 단계에 쿼리 작업이 매핑되는 방법을 보여줍니다. 각 쿼리 계획 작업은 세그먼트 내 다수의 단계로 매핑되고, 간혹 스트림 내 다수의 세그먼트로 매핑되기도 합니다.
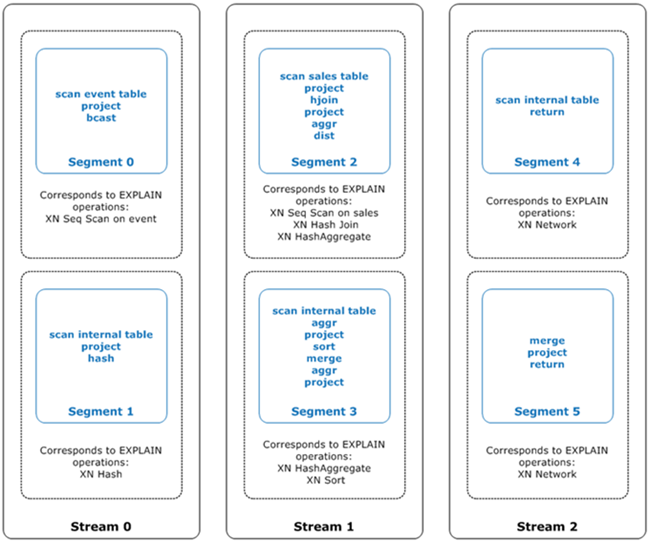
이 그림에서 쿼리 최적화 프로그램은 다음과 같이 쿼리 계획을 실행합니다.
Stream 0에서 쿼리는 순차적 스캔 작업과 함께Segment 0을 실행하여events테이블을 스캔합니다. 쿼리는 해시 작업과 함께Segment 1을 계속하여 조인에 내부 테이블에 대한 해시 테이블을 만듭니다.Stream 1에서 쿼리는 순차적 스캔 작업과 함께Segment 2을 실행하여sales테이블을 스캔합니다. 해시 조인과 함께Segment 2를 계속하여 조인 열이 둘 다 분산 키 및 정렬 키가 아닌 테이블을 조인합니다. 해시 집계와 함께Segment 2를 다시 계속하여 결과를 집계합니다. 그런 다음 쿼리는 해시 집계 작업과 함께Segment 3을 실행하여 정렬되지 않은 그룹화된 집계 함수 및 정렬 작업을 수행하여 ORDER BY 절 및 다른 정렬 작업을 평가합니다.Stream 2에서 쿼리는Segment 4및Segment 5에서 네트워크 작업을 실행하여 추가 처리를 위해 중간 결과를 리더 노드로 보냅니다.
쿼리의 마지막 세그먼트는 데이터를 반환합니다. 반환 집합이 집계되거나 정렬되면 컴퓨팅 노드는 각각 중간 결과의 조각을 리더 노드로 보냅니다. 그런 다음 리더 노드는 최종 결과를 요청하는 클라이언트로 다시 전송할 수 있도록 데이터를 병합합니다.
EXPLAIN 연산자에 대한 자세한 내용은 EXPLAIN 섹션을 참조하세요.
