Spark 커넥터를 사용한 인증
다음 다이어그램은 Amazon S3, Amazon Redshift, Spark 드라이버 및 Spark 실행기 간의 인증을 설명합니다.
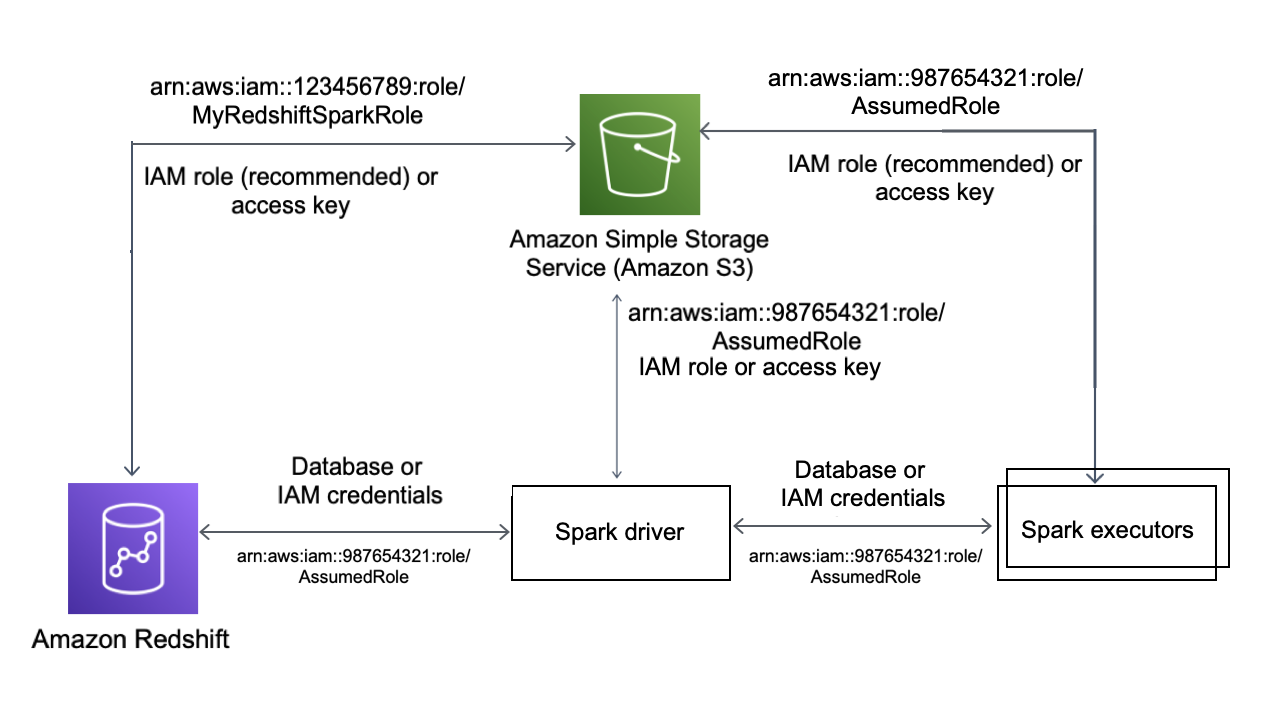
Redshift와 Spark 간의 인증
Amazon Redshift 제공 JDBC 드라이버 버전 2 드라이버를 사용하여 로그인 보안 인증 정보를 지정하여 Spark 커넥터로 Amazon Redshift에 연결할 수 있습니다. IAM을 사용하려면 IAM 인증을 사용하도록 JDBC URL을 구성하세요. Amazon EMR 또는 AWS Glue에서 Redshift 클러스터에 연결하려면 IAM 역할에 임시 IAM 자격 증명을 검색하는 데 필요한 권한이 있는지 확인하세요. 다음 목록은 IAM 역할이 자격 증명을 검색하고 Amazon S3 작업을 실행하는 데 필요한 모든 권한을 설명합니다.
-
Redshift:GetClusterCredentials(프로비저닝된 Redshift 클러스터용)
-
Redshift:DescribeClusters(프로비저닝된 Redshift 클러스터용)
-
Redshift:GetWorkgroup(Amazon Redshift Serverless 작업 그룹)
-
Redshift:GetCredentials(Amazon Redshift Serverless 작업 그룹)
GetClusterCredentials에 대한 자세한 내용은 GetClusterCredentials에 대한 리소스 정책을 참조하세요.
또한 COPY 및 UNLOAD 작업 중에 Amazon Redshift가 IAM 역할을 맡을 수 있는지 확인해야 합니다.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
최신 JDBC 드라이버를 사용하는 경우 드라이버는 Amazon Redshift 자체 서명 인증서에서 ACM 인증서로의 전환을 자동으로 관리합니다. 하지만 JDBC URL에 SSL 옵션을 지정해야 합니다.
다음은 Amazon Redshift에 연결하기 위해 JDBC 드라이버 URL 및 aws_iam_role을 지정하는 방법의 예입니다.
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Amazon S3와 Spark 간의 인증
IAM 역할을 사용하여 Spark와 Amazon S3 간에 인증하는 경우 다음 방법 중 하나를 사용하세요.
-
Java용 AWS SDK는 DefaultAWSCredentialsProviderChain 클래스에 의해 구현된 기본 자격 증명 공급자 체인을 사용하여 자동으로 AWS 자격 증명을 찾으려고 시도합니다. 자세한 내용은 기본 자격 증명 공급자 체인 사용을 참조하세요.
-
Hadoop 구성 속성
을 통해 AWS 키를 지정할 수 있습니다. 예를 들어 tempdir구성이s3n://파일 시스템을 가리키는 경우 Hadoop XML 구성 파일에서fs.s3n.awsAccessKeyId및fs.s3n.awsSecretAccessKey속성을 설정하거나sc.hadoopConfiguration.set()을 호출하여 Spark의 전역 Hadoop 구성을 변경합니다.
예를 들어 s3n 파일 시스템을 사용하는 경우 다음을 추가합니다.
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
s3a 파일 시스템을 사용하는 경우 다음을 추가합니다.
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
Python을 사용하는 경우 다음 작업을 사용합니다.
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
tempdirURL에서 인증 키를 인코딩합니다. 예를 들어 URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/dir은 키 쌍(ACCESSKEY,SECRETKEY)을 인코딩합니다.
Redshift와 Amazon S3 간의 인증
쿼리에서 COPY 및 UNLOAD 명령을 사용하는 경우 사용자 대신 쿼리를 실행할 수 있도록 Amazon Redshift에 대한 Amazon S3 액세스 권한도 부여해야 합니다. 이렇게 하려면 먼저 다른 AWS 서비스에 액세스할 수 있도록 Amazon Redshift에 권한을 부여한 다음 IAM 역할을 사용하여 COPY 및 UNLOAD 작업에 권한을 부여합니다.
가장 좋은 방법은 권한 정책을 IAM 역할에 연결한 다음 필요에 따라 사용자 및 그룹에 할당하는 것입니다. 자세한 내용은 Amazon Redshift의 Identity and Access Management를 참조하세요.
AWS Secrets Manager와의 통합
AWS Secrets Manager에 저장된 시크릿에서 Redshift 사용자 이름 및 암호 보안 인증 정보를 검색할 수 있습니다. Redshift 보안 인증을 자동으로 제공하려면 secret.id 파라미터를 사용하세요. Redshift 보안 인증 시크릿을 만드는 방법에 대한 자세한 내용은 AWS Secrets Manager 데이터베이스 보안 암호 생성을 참조하세요.
| GroupID | ArtifactID | 지원되는 리비전 | 설명 |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | Java용 AWS Secrets Manager SQL 연결 라이브러리를 사용하면 Java 개발자가 AWS Secrets Manager에 저장된 암호를 사용하여 SQL 데이터베이스에 쉽게 연결할 수 있습니다. |
참고
인정 조항: 이 문서에는 Apache 2.0 라이선스
