기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
이 섹션에서는 Amazon Rekognition Image 및 Amazon Rekognition Video를 사용한 이미지와 비디오에서의 레이블 감지에 대한 정보를 다룹니다.
레이블 또는 태그는 콘텐츠를 기반으로 이미지나 비디오에서 발견되는 객체 또는 개념(장면과 행동을 포함한)을 가리킵니다. 예를 들면 열대 해변에 있는 사람들을 찍은 이미지에는 야자수(객체), 해변(장면), 달리기(행동), 야외(개념)와 같은 레이블이 포함될 수 있습니다.
Rekognition 레이블 감지 작업에서 지원하는 레이블
참고
Amazon Rekognition은 특정 이미지에 나오는 사람의 신체적 외양을 기반으로 성별 이분법적인(남성, 여성, 소녀 등) 예측을 내놓습니다. 이러한 종류의 예측은 사람의 성 정체성을 범주화하도록 설계되지 않았으므로 이러한 결정을 내리는 데 Amazon Rekognition을 사용하지 않아야 합니다. 예를 들어, 연기를 위해 긴 머리 가발과 귀걸이를 착용한 남성 배우를 여성으로 예측할 수 있습니다.
Amazon Rekognition을 사용한 성별 이분법적 예측은 특정 사용자 식별 없이 전체 성별 분포 통계를 분석해야 하는 사용 사례에 가장 적합합니다. 소셜 미디어 플랫폼에서 남성 대비 여성 사용자의 비율을 예로 들 수 있습니다.
개인의 권리, 사생활 또는 서비스 액세스에 영향을 미칠 수 있는 결정을 내리는 데에는 성별 이분법적 예측을 사용하지 않는 것을 권장합니다.
Amazon Rekognition은 레이블을 영어로 반환합니다. Amazon Translate
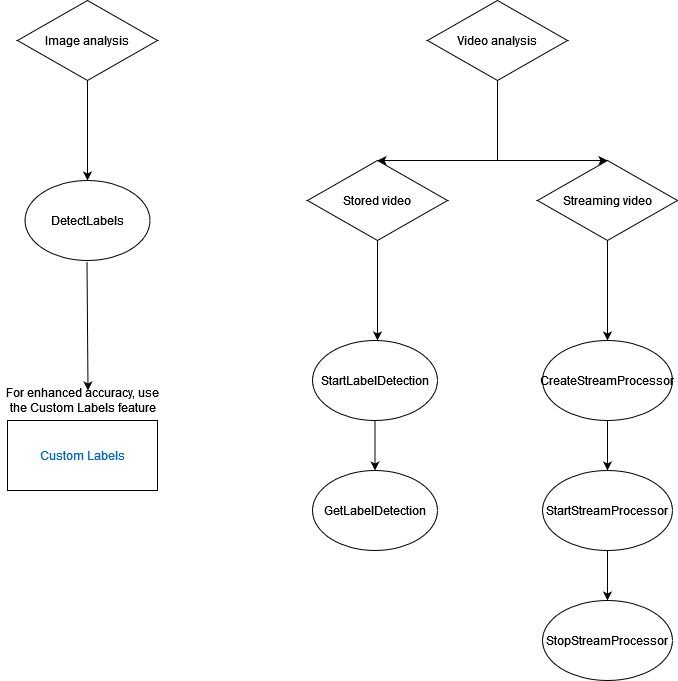
다음 다이어그램은 Amazon Rekognition Image 또는 Amazon Rekognition Video 작업 사용 목표에 따른 직접 호출 작업의 순서를 보여줍니다.
레이블 응답 객체
경계 상자
Amazon Rekognition Image 및 Amazon Rekognition Video는 차량, 가구, 의류, 반려동물 등 일반적 객체 레이블에 대해 경계 상자를 반환할 수 있습니다. 경계 상자 정보는 이보다 일반적이지 않은 객체 레이블에 대해서는 반환되지 않습니다. 경계 상자를 사용하여 이미지에서 객체의 정확한 위치를 찾거나, 감지된 객체의 인스턴스 수를 계산하거나, 경계 상자 치수를 사용하여 객체의 크기를 측정할 수 있습니다.
예를 들어 다음 이미지에서 Amazon Rekognition Image는 사람의 존재, 스케이트보드, 주차된 차량 및 기타 정보를 감지할 수 있습니다. Amazon Rekognition Image는 감지된 사람과 자동차나 바퀴와 같은 기타 감지된 객체에 대해서도 경계 상자를 반환합니다.

신뢰도 점수
Amazon Rekognition Video와 Amazon Rekognition Image는 감지된 각 레이블의 정확성에 대해 Amazon Rekognition이 얼마나 확신하는지를 나타내는 백분율 점수를 제공합니다.
상위 개념
Amazon Rekognition Image와 Amazon Rekognition Video는 상위 레이블의 계층적 분류 체계를 사용하여 레이블을 분류합니다. 예를 들어 도로를 횡단하는 사람이 보행자로 감지될 수 있습니다. 보행자의 부모 레이블은 인물입니다. 응답에서 두 레이블이 모두 반환됩니다. 모든 상위 레이블이 반환되고, 지정된 레이블이 부모 및 기타 상위 레이블의 목록을 포함합니다. 예를 들어, 존재할 경우 조부모 및 증조부모 레이블이 포함됩니다. 부모 레이블을 사용하여 관련된 레이블의 그룹을 만들고 하나 이상의 이미지에서 비슷한 레이블을 쿼리하도록 허용할 수 있습니다. 예를 들어 모든 차량을 쿼리하면 한 이미지에서 자동차가 반환되고 다른 이미지에서 오토바이가 반환될 수 있습니다.
Categories
Amazon Rekognition Image 및 Amazon Rekognition Video는 레이블 카테고리에 대한 정보를 반환합니다. 레이블은 '차량 및 자동차', '식음료'와 같이 공통 기능 및 맥락에 기반하여 개별 레이블을 그룹화하는 카테고리의 일부입니다. 레이블 카테고리는 상위 카테고리의 하위 카테고리일 수 있습니다.
에일리어스
Amazon Rekognition Image와 Amazon Rekognition Video는 레이블을 반환하는 것 외에도 레이블과 연결된 모든 별칭을 반환합니다. 별칭은 의미가 같은 레이블 또는 반환된 기본 레이블과 시각적으로 서로 바꿀 수 있는 레이블을 말합니다. 예를 들어, 'Cell Phone'은 'Mobile Phone'의 별칭입니다.
이전 버전에서는 Amazon Rekognition Image가 'Mobile Phone'을 포함하는 동일한 기본 레이블 이름 목록에서 'Cell Phone'과 같은 별칭을 반환했습니다. Amazon Rekognition Image는 이제 “별칭” 필드에 ‘Cell Phone’을, 기본 레이블 이름 목록에 'Mobile Phone'을 반환합니다. 애플리케이션이 이전 버전의 Rekognition에서 반환된 구조에 의존한다면 이미지 또는 동영상 레이블 감지 작업에서 반환되는 현재 응답을 모든 레이블과 별칭이 기본 레이블로 반환되는 이전의 응답 구조로 변환해야 할 수 있습니다.
DetectLabels API(이미지의 레이블 감지용)의 현재 응답을 이전 응답 구조로 변환해야 하는 경우 DetectLabels 응답의 변환의 코드 예제를 참조하세요.
GetLabelDetection API(저장된 동영상의 레이블 감지용)의 현재 응답을 이전 응답 구조로 변환해야 하는 경우 GetLabelDetection 응답의 변환의 코드 예제를 참조하세요.
이미지 속성
Amazon Rekognition Image는 전체 이미지의 이미지 품질(선명도, 밝기, 대비)에 대한 정보를 반환합니다. 이미지의 전경과 배경에 대해서도 선명도와 밝기가 반환됩니다. 또한 이미지 속성을 사용하여 전체 이미지, 전경, 배경 및 경계 상자가 있는 객체의 주 색상을 감지할 수도 있습니다.

다음은 현재 이미지에 대한 DetectLabels 작업의 응답에 포함된 ImageProperties 데이터의 예입니다.
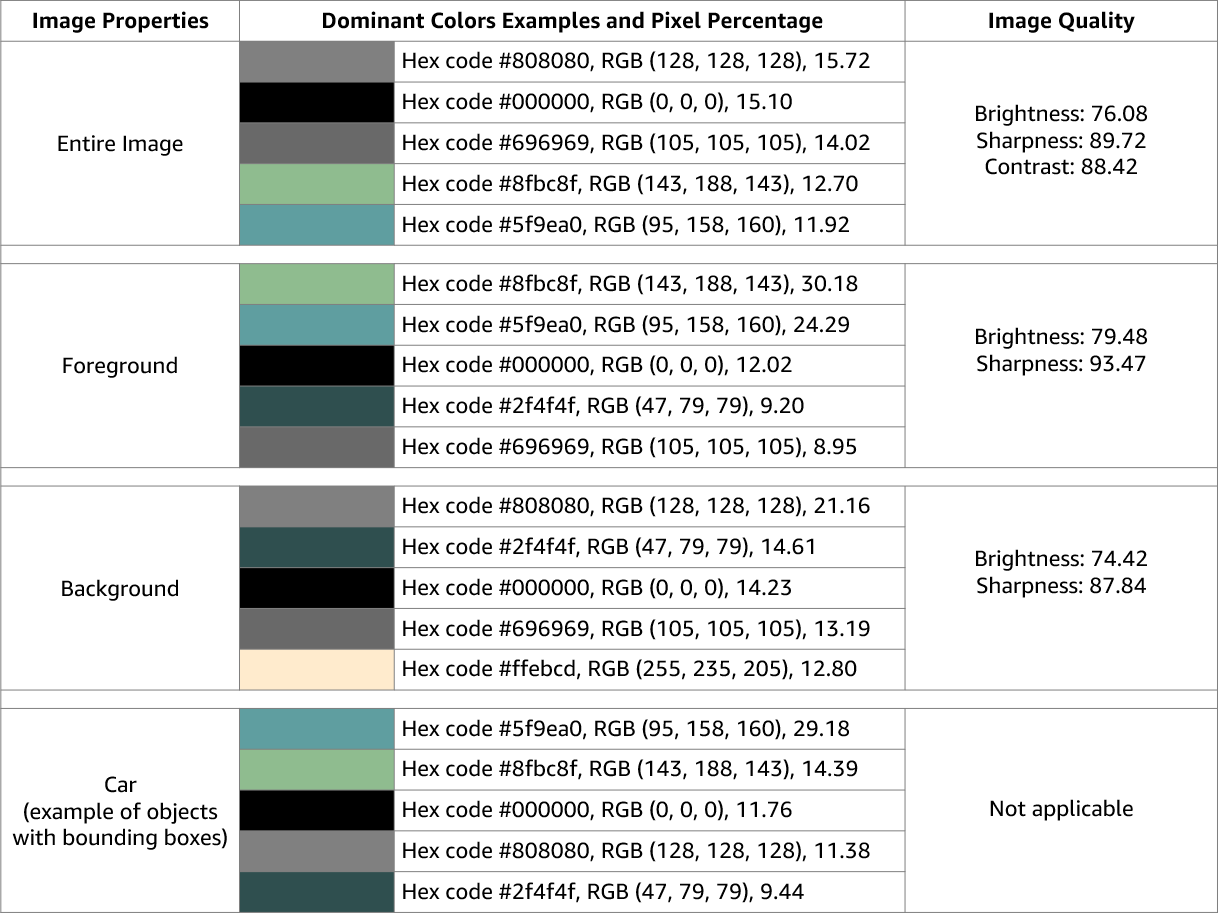
Amazon Rekognition Video에서는 이미지 속성을 사용할 수 없습니다.
모델 버전
Amazon Rekognition Image 및 Amazon Rekognition Video는 이미지 또는 저장된 비디오에서 레이블을 감지하는 데 사용되는 레이블 감지 모델의 버전을 반환합니다.
포함 및 제외 필터
Amazon Rekognition Image 및 Amazon Rekognition Video 레이블 감지 작업에서 반환되는 결과를 필터링할 수 있습니다. 레이블 및 카테고리에 대한 필터링 기준을 제공하여 결과를 필터링하세요. 레이블 필터는 포함 또는 제외 필터일 수 있습니다.
DetectLabels를 사용하여 얻은 결과의 필터링에 대한 자세한 내용은 이미지에서 레이블 감지 섹션을 참조하세요.
GetLabelDetection으로 얻은 결과의 필터링에 대한 자세한 내용은 비디오에서 레이블 감지 섹션을 참조하세요.
결과 정렬 및 집계
특정 Amazon Rekognition Video 작업에서 얻은 결과를 타임스탬프 및 비디오 세그먼트에 따라 정렬하고 집계할 수 있습니다. 레이블 감지 또는 콘텐츠 조절 작업의 결과를 각각GetLabelDetection 또는 GetContentModeration으로 가져올 때는 SortBy 및 AggregateBy 인수를 사용하여 결과가 반환되는 방식을 지정할 수 있습니다. SortBy를 TIMESTAMP 또는 NAME(레이블 이름)과 함께 사용하고 TIMESTAMPS나 SEGMENTS를 AggregateBy 인수와 함께 사용할 수 있습니다.
