기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
테이블을 사용하여 사용자 지정 어휘 생성
사용자 지정 어휘를 만들 때는 테이블 형식을 사용하는 것이 좋습니다. 어휘 테이블은 네 개의 열((Phrase, SoundsLike, IPA, and DisplayAs))로 구성되어야 하며, 어떤 순서로든 포함될 수 있습니다.
| 구절 | SoundsLike | IPA | DisplayAs |
|---|---|---|---|
|
필수 사항입니다. 테이블의 모든 행에는 이 열의 항목이 포함되어야 합니다. 이 열에는 스페이스를 사용하지 마세요. 항목에 여러 단어가 포함된 경우 각 단어를 하이픈(-)으로 구분합니다. 예: 두문자어의 경우 발음되는 모든 문자를 마침표로 구분해야 합니다. 마지막 마침표도 발음해야 합니다. 두문자어가 복수형인 경우 두문자어와 's' 사이에 하이픈을 사용해야 합니다. 예를 들어, 'CLI'는 구절이 단어와 두문자어로 구성된 경우 이 두 구성 요소를 하이픈으로 구분해야 합니다. 예를 들어, 'DynamoDB'는 이 열에 숫자를 포함하지 마세요. 숫자는 철자로 입력해야 합니다. 예를 들어, 'VX02Q'는 |
|
|
선택 사항입니다. 이 열의 행은 비워 둘 수 있습니다. 이 열에는 스페이스를 사용할 수 있습니다. 트랜스크립션 출력에서 항목이 어떻게 보이길 원하는지 정의합니다. 예를 들어, 이 열의 행이 비어 있는 경우 이 열에 숫자( |
테이블을 만들 때 참고할 사항:
-
테이블에는 네 개의 열 머리글이 (Phrase, SoundsLike, IPA, and DisplayAs) 모두 포함되어야 합니다.
Phrase열에는 각 행에 항목이 하나씩 있어야 합니다. 를 통해IPA발음 입력을 제공하는 기능은 더 이상 지원되지 않으므로 열을 비워 두어도 됩니다.SoundsLike이 열의 모든 값은 무시됩니다. -
각 열은 TAB 또는 쉼표(,)로 구분해야 합니다. 이는 사용자 지정 어휘 파일의 모든 행에 적용됩니다. 행에 빈 열이 있는 경우에도 각 열에 구분자(TAB 또는 쉼표)를 포함해야 합니다.
-
IPA및DisplayAs열 내에만 스페이스가 허용됩니다. 스페이스를 사용하여 열을 구분하지 마세요. -
IPA사용자 지정SoundsLike어휘에는 더 이상 지원되지 않습니다. 열을 비워 두십시오. 이 열의 모든 값은 무시됩니다. 향후 이 칼럼에 대한 지원을 제거할 예정입니다. -
DisplayAs열은 기호와 특수 문자(예: C++)를 지원합니다. 다른 모든 열은 해당 언어의 문자 집합 페이지에 나열된 문자를 지원합니다. -
Phrase열에 숫자를 포함하려면 철자를 입력해야 합니다. 숫자(0-9)는DisplayAs열에서만 지원됩니다. -
테이블을
LF형식의 일반 텍스트(*.txt) 파일로 저장해야 합니다. 다른 형식(예:CRLF)을 사용하는 경우 사용자 지정 어휘를 처리할 수 없습니다. -
사용자 지정 어휘 파일을 Amazon S3 버킷에 업로드하고 를 사용하여
CreateVocabulary처리해야 트랜스크립션 요청에 포함시킬 수 있습니다. 지침은 사용자 지정 어휘 테이블 생성 단원을 참조하세요.
참고
두문자어 또는 문자를 개별적으로 발음해야 하는 기타 단어는 마침표로 구분된 단일 문자로 입력합니다(A.B.C.). 두문자어의 복수 형태를 입력하려면(예: 'ABCs') 하이픈으로 두문자어에서 's'를 구분합니다(A.B.C.-s). 대문자 또는 소문자를 사용해 두문자어를 정의할 수 있습니다. 모든 언어에서 두문자어가 지원되는 것은 아닙니다. 지원되는 언어 및 언어별 기능를 참조하세요.
다음은 샘플 사용자 지정 어휘 테이블입니다(여기서 [TAB]은 탭 문자를 나타냄).
Phrase[TAB]SoundsLike[TAB]IPA[TAB]DisplayAs
Los-Angeles[TAB][TAB][TAB]Los Angeles
Eva-Maria[TAB][TAB][TAB]
A.B.C.-s[TAB][TAB][TAB]ABCs
Amazon-dot-com[TAB][TAB][TAB]Amazon.com
C.L.I.[TAB][TAB][TAB]CLI
Andorra-la-Vella[TAB][TAB][TAB]Andorra la Vella
Dynamo-D.B.[TAB][TAB][TAB]DynamoDB
V.X.-zero-two[TAB][TAB][TAB]VX02
V.X.-zero-two-Q.[TAB][TAB][TAB]VX02Q시각적 명확성을 위해 동일한 테이블에 열이 정렬되어 있습니다. 사용자 지정 어휘 테이블의 열 사이에 스페이스를 추가하지 마세요. 위의 예와 같이 테이블이 잘못 정렬되어 보일 수 있습니다.
Phrase [TAB]SoundsLike [TAB]IPA [TAB]DisplayAs
Los-Angeles [TAB] [TAB] [TAB]Los Angeles
Eva-Maria [TAB] [TAB] [TAB]
A.B.C.-s [TAB] [TAB] [TAB]ABCs
amazon-dot-com [TAB] [TAB] [TAB]amazon.com
C.L.I. [TAB] [TAB] [TAB]CLI
Andorra-la-Vella[TAB] [TAB] [TAB]Andorra la Vella
Dynamo-D.B. [TAB] [TAB] [TAB]DynamoDB
V.X.-zero-two [TAB] [TAB] [TAB]VX02
V.X.-zero-two-Q.[TAB] [TAB] [TAB]VX02Q사용자 지정 어휘 테이블 생성
에서 사용할 사용자 지정 어휘 표를 처리하려면 다음 예를 참조하십시오. Amazon Transcribe
-
AWS Management Console
에 로그인합니다. -
탐색 창에서 사용자 지정 어휘를 선택합니다. 그러면 기존 어휘를 확인하거나 새 어휘를 만들 수 있는 사용자 지정 어휘 페이지가 열립니다.
-
어휘 생성을 선택합니다.
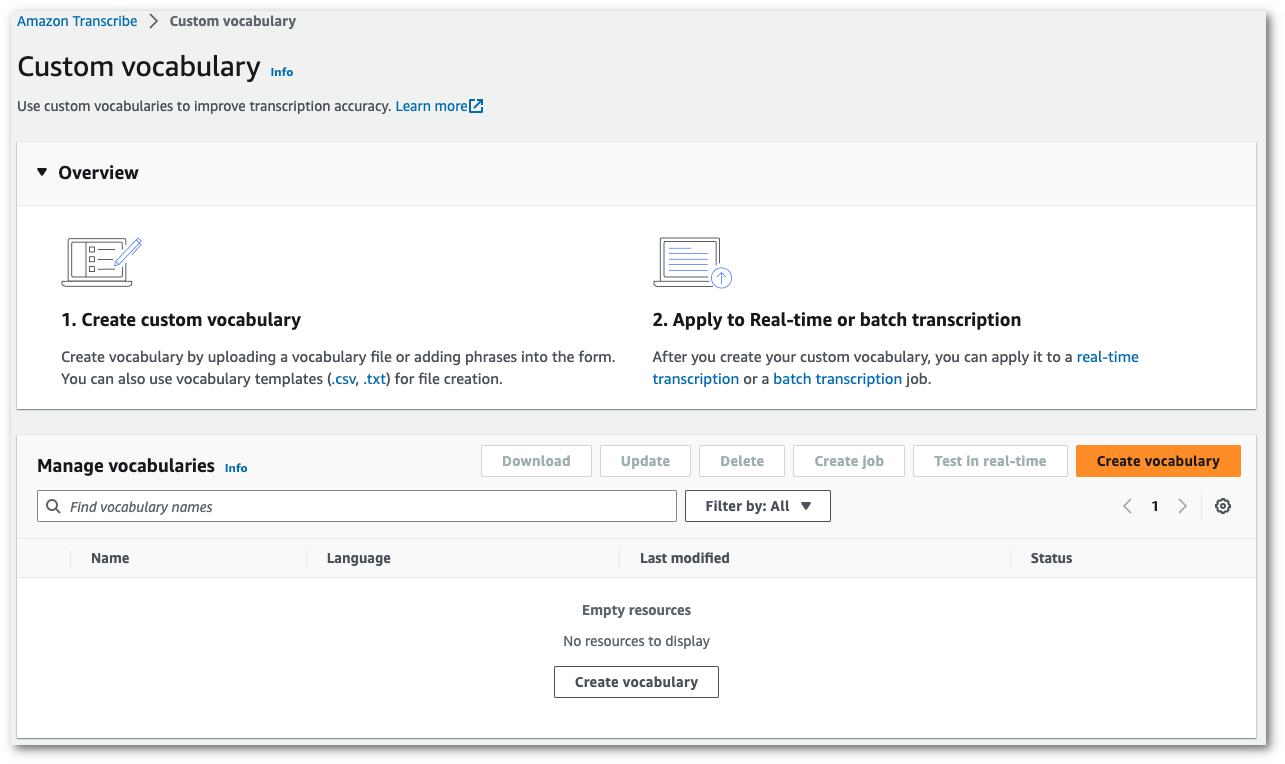
그러면 어휘 생성 페이지로 이동합니다. 새 사용자 지정 어휘의 이름을 입력합니다.
여기에는 다음과 같은 3가지 옵션이 있습니다.
-
컴퓨터에서 txt 또는 csv 파일을 업로드합니다.
사용자 지정 어휘를 새로 만들거나 시작하는 데 도움이 되는 템플릿을 다운로드할 수 있습니다. 그러면 어휘 보기 및 편집 창에 어휘가 자동으로 채워집니다.
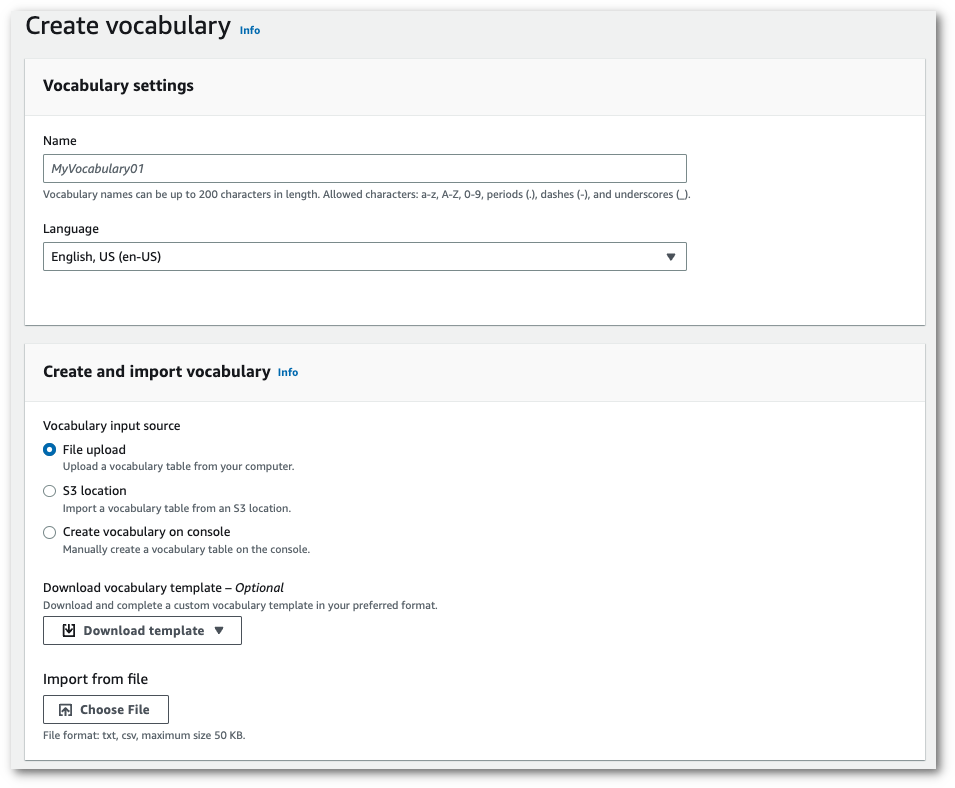
-
특정 위치에서 txt 또는 csv 파일을 가져옵니다. Amazon S3
사용자 지정 어휘를 새로 만들거나 시작하는 데 도움이 되는 템플릿을 다운로드할 수 있습니다. 완성된 어휘 파일을 Amazon S3 버킷에 업로드하고 요청에 해당 URI를 지정합니다. 그러면 어휘 보기 및 편집 창에 어휘가 자동으로 채워집니다.
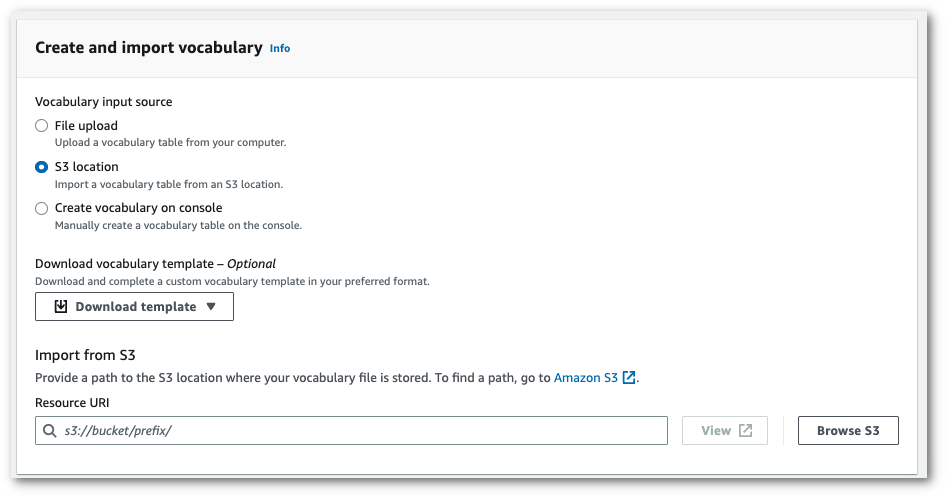
-
콘솔에서 어휘를 수동으로 생성합니다.
어휘 보기 및 편집 창으로 스크롤하여 10개 행 추가를 선택합니다. 이제 용어를 수동으로 입력할 수 있습니다.
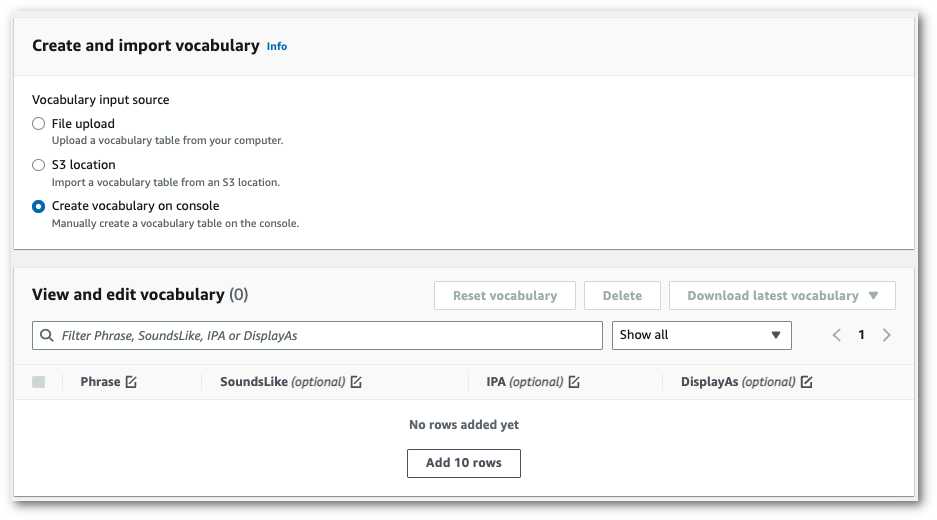
-
-
어휘 보기 및 편집 창에서 어휘를 편집할 수 있습니다. 변경하려면 수정할 항목을 클릭합니다.
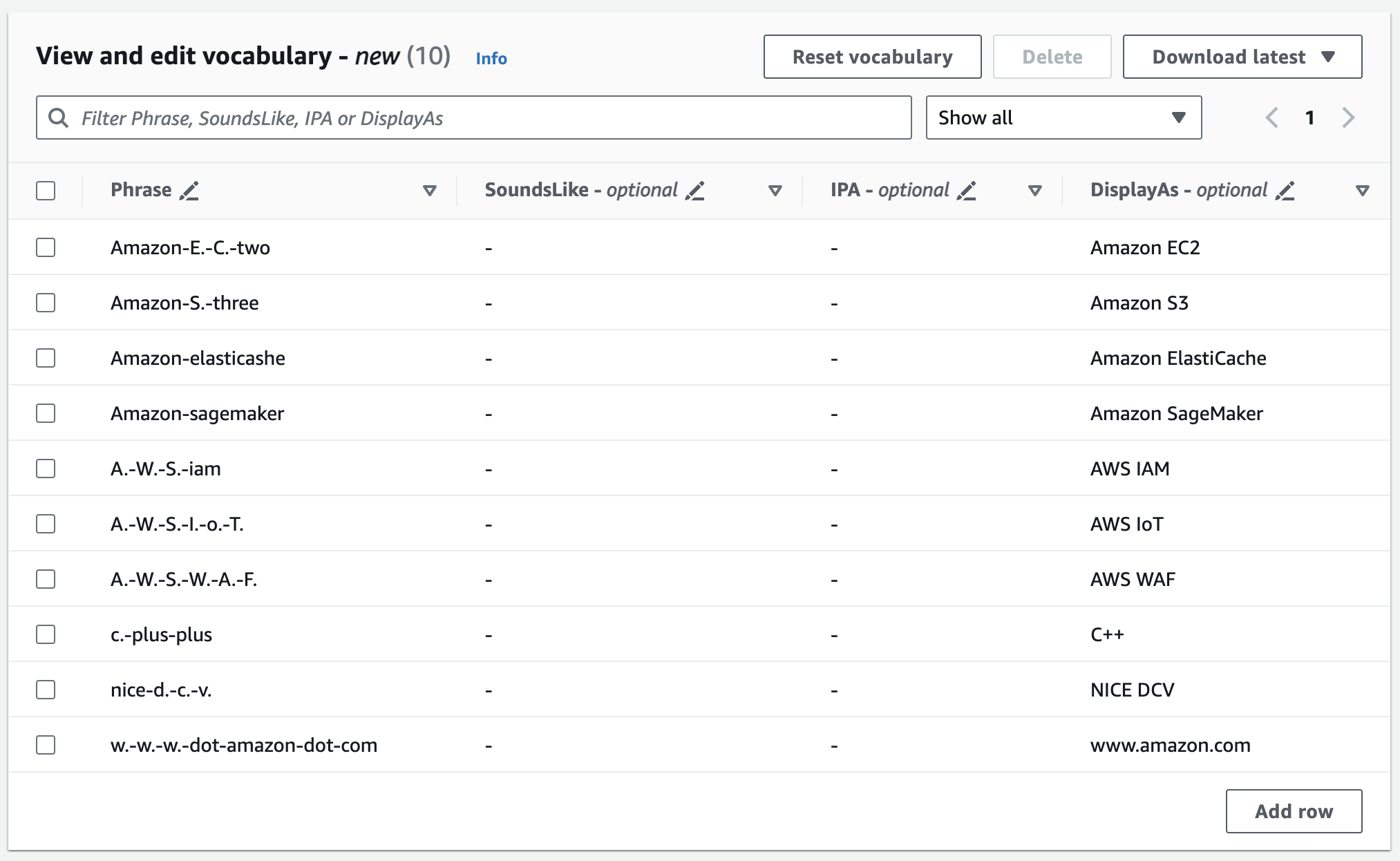
오류가 발생하면 자세한 오류 메시지가 표시되므로 어휘를 처리하기 전에 문제를 수정할 수 있습니다. 단, 어휘 생성을 선택하기 전에 모든 오류를 수정하지 않으면 어휘 요청이 실패한다는 점에 유의하세요.
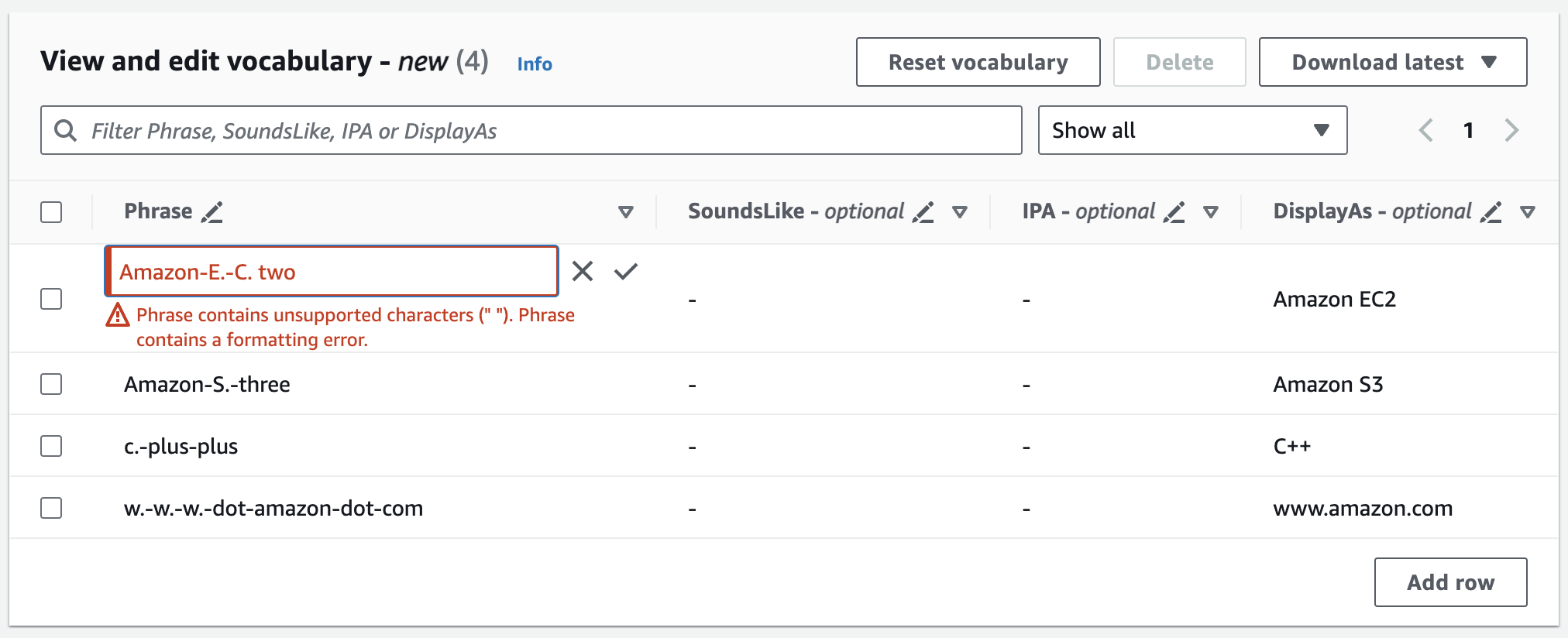
변경 내용을 저장하려면 체크 표시(✓)를 선택하고 변경 내용을 삭제하려면 'X'를 선택합니다.
-
필요에 따라 사용자 지정 어휘에 태그를 추가합니다. 모든 필드를 작성하고 어휘에 만족하면 페이지 하단에서 어휘 생성을 선택합니다. 그러면 사용자 지정 어휘 페이지로 돌아가서 사용자 지정 어휘의 상태를 볼 수 있습니다. 상태가 '보류 중'에서 '준비'로 변경되면 사용자 지정 어휘를 트랜스크립션과 함께 사용할 수 있습니다.

-
상태가 '실패'로 변경되면 사용자 지정 어휘의 이름을 선택하여 해당 정보 페이지로 이동합니다.
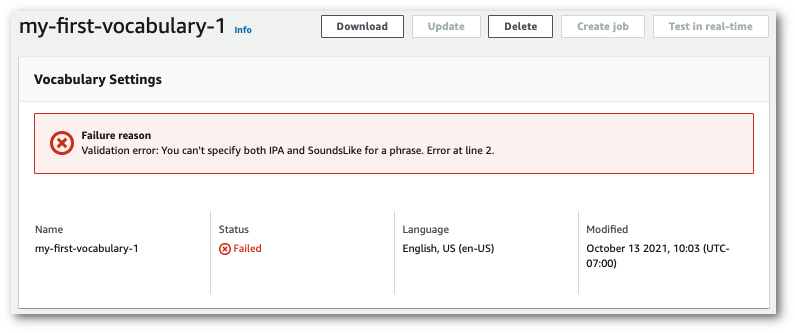
이 페이지 상단에는 사용자 지정 어휘가 실패한 이유에 대한 정보를 제공하는 실패 사유 배너가 있습니다. 텍스트 파일에서 오류를 수정하고 다시 시도하세요.
이 예시에서는 테이블 형식의 어휘 파일과 함께 create-vocabulary 명령을 사용합니다. 자세한 정보는 CreateVocabulary을 참조하세요.
트랜스크립션 작업에서 기존 사용자 지정 어휘를 사용하려면 작업을 호출할 때 Settings필드에 를 설정하거나 에서 드롭다운 목록에서 사용자 지정 어휘를 선택하십시오. VocabularyName StartTranscriptionJob AWS Management Console
aws transcribe create-vocabulary \ --vocabulary-namemy-first-vocabulary\ --vocabulary-file-uri s3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-file.txt \ --language-codeen-US
다음은 create-vocabulary 명령을 사용하는 또 다른 예 및 사용자 지정 어휘를 생성하는 요청 본문입니다.
aws transcribe create-vocabulary \ --cli-input-json file://filepath/my-first-vocab-table.json
my-first-vocab-table.json 파일에는 다음 요청 본문이 포함되어 있습니다.
{ "VocabularyName": "my-first-vocabulary", "VocabularyFileUri": "s3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-table.txt", "LanguageCode": "en-US" }
VocabularyState가 PENDING에서 READY로 변경되면 사용자 지정 어휘를 트랜스크립션과 함께 사용할 수 있습니다. 사용자 지정 어휘의 현재 상태를 보려면 다음을 실행합니다.
aws transcribe get-vocabulary \ --vocabulary-namemy-first-vocabulary
이 예제에서는 AWS SDK for Python (Boto3) 를 사용하여 create_vocabularyCreateVocabulary을 참조하세요.
트랜스크립션 작업에서 기존 사용자 정의 어휘를 사용하려면 작업을 호출할 때 Settings필드에 를 설정하거나 에서 드롭다운 목록에서 사용자 지정 어휘를 선택하십시오. VocabularyName StartTranscriptionJob AWS Management Console
기능별, 시나리오 및 크로스 서비스 예제를 포함하여 AWS SDK를 사용하는 추가 예제는 이 장을 참조하십시오. 를 사용한 Amazon Transcribe의 코드 예제 AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') vocab_name = "my-first-vocabulary" response = transcribe.create_vocabulary( LanguageCode = 'en-US', VocabularyName = vocab_name, VocabularyFileUri = 's3://DOC-EXAMPLE-BUCKET/my-vocabularies/my-vocabulary-table.txt' ) while True: status = transcribe.get_vocabulary(VocabularyName = vocab_name) if status['VocabularyState'] in ['READY', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
참고
사용자 지정 어휘 파일을 위한 새 Amazon S3 버킷을 만드는 경우 CreateVocabulary요청을 하는 IAM 역할에 이 버킷에 액세스할 수 있는 권한이 있는지 확인하세요. 역할에 올바른 권한이 없는 경우 요청이 실패합니다. DataAccessRoleArn파라미터를 포함하여 요청 내에서 IAM 역할을 지정할 수도 있습니다. 의 IAM 역할 및 정책에 대한 자세한 내용은 Amazon Transcribe을 참조하십시오Amazon Transcribe 자격 증명 기반 정책 예제.
