기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
배치 트랜스크립션 작업을 통한 언어 식별
배치 언어 식별을 사용하여 미디어 파일의 언어를 자동으로 식별합니다.
미디어에 한 가지 언어만 포함된 경우 단일 언어 식별을 활성화하여 미디어 파일에서 사용되는 지배적 언어를 식별하고 이 언어만 사용하여 트랜스크립트를 생성할 수 있습니다.
미디어에 두 개 이상의 언어가 포함된 경우 다국어 식별을 활성화하여 미디어 파일에서 사용되는 모든 언어를 식별하고 식별된 각 언어를 사용하여 트랜스크립트를 생성할 수 있습니다. 다국어 트랜스크립트가 생성된다는 점에 유의하세요. 등의 Amazon Translate다른 서비스를 사용하여 성적표를 번역할 수 있습니다.
지원되는 언어 및 관련 언어 코드의 전체 목록은 지원되는 언어 테이블을 참조하세요.
최상의 결과를 얻으려면 미디어 파일에 30초 이상의 음성이 포함되어 있어야 합니다.
AWS Management Console, AWS CLI, AWS Python SDK를 사용한 사용 예제는 을 참조하십시오배치 트랜스크립션 작업을 통한 언어 식별 사용.
다국어 오디오의 언어 식별
다국어 식별은 다국어 미디어 파일을 위한 것으로 미디어에서 사용되는 지원되는 언어 모두를 반영하는 트랜스크립트를 제공합니다. 즉, 화자가 대화 도중에 언어를 바꾸거나 각 참가자가 서로 다른 언어를 사용하는 경우 트랜스크립션 출력은 각 언어를 올바르게 감지하고 트랜스크립션합니다. 예를 들어 미디어에 미국 영어(en-US)와 힌디어(hi-IN)를 번갈아 사용하는 이중 언어 화자가 포함되어 있는 경우 다국어 식별을 통해 미국 영어는 en-US로 힌디어는 hi-IN으로 식별하고 트랜스크립션할 수 있습니다.
이는 한 가지 지배적 언어만 사용하여 트랜스크립트를 작성하는 단일 언어 식별과는 다릅니다. 이 경우 지배적 언어가 아닌 음성 언어는 부정확하게 트랜스크립션됩니다.
참고
현재 다국어 식별에서는 교정 및 사용자 지정 언어 모델이 지원되지 않습니다.
참고
현재 다국어 식별이 지원되는 언어는 다음과 같습니다. en-Ab, en-AU, en-GB, en-IE, en-Ie, en-NZ, en-US, en-WL, en-ZA, es-ES, es-US, fr-CA, fr-Fr, zH-Cn, zH-TW, pt-Pt, de-ch, a-Ae, Da-DK, He-Il, 하이인, 아이디-아이디, 파에어, 잇-잇, Ja-jp, Ko-kr, MS-My, nl-nl, 루루, 타인, 테인, 테인, 티인, 티인, 티인, 티-티-R
다국어 트랜스크립트에는 감지된 언어 및 미디어에서 각 언어가 사용된 총 시간이 요약되어 있습니다. 다음은 그 예입니다.
"results": { "transcripts": [ { "transcript": "welcome to Amazon transcribe. ये तो उदाहरण हैं क्या कैसे कर सकते हैं ।一つのファイルに複数の言語を書き写す" } ],..."language_codes": [ { "language_code": "en-US", "duration_in_seconds": 2.45 }, { "language_code": "hi-IN", "duration_in_seconds": 5.325 }, { "language_code": "ja-JP", "duration_in_seconds": 4.15 } ] }
언어 식별 정확도 향상
언어 식별을 사용하면 미디어에 있을 것으로 생각되는 언어 목록을 포함할 수 있습니다. 언어 옵션 (LanguageOptions) 을 포함하면 오디오를 올바른 언어에 일치시킬 때 지정한 언어만 사용하도록 Amazon Transcribe 제한되므로 언어 식별 속도가 빨라지고 올바른 언어 언어 지정과 관련된 정확성이 향상될 수 있습니다.
언어 코드를 포함하려면 두 개 이상 포함해야 합니다. 포함할 수 있는 언어 코드 수에는 제한이 없지만 최적의 효율성과 정확도를 위해 2~5개 사이를 사용하는 것이 좋습니다.
참고
요청에 언어 코드를 포함했지만 제공한 언어 코드 중 오디오에서 식별된 언어 또는 언어와 일치하지 않는 경우 지정된 언어 코드에서 가장 일치하는 언어를 Amazon Transcribe 선택합니다. 그런 다음 해당 언어로 트랜스크립트를 생성합니다. 예를 들어, 미디어가 미국 영어 (en-US) Amazon Transcribe 로 되어 있고 해당 미디어가 독일어 (de-DE) 와 일치하는지 확인하는 언어 코드 zh-CN fr-FRde-DE, Amazon Transcribe 및 를 제공하여 독일어 자막을 작성할 수 있는 경우를 예로 들 수 있습니다. 언어 코드와 음성 언어가 일치하지 않으면 트랜스크립트가 정확하지 않을 수 있으므로 언어 코드를 포함할 때는 주의를 기울이는 것이 좋습니다.
언어 식별과 다른 Amazon Transcribe 기능 결합
배치 언어 식별을 다른 Amazon Transcribe 기능과 함께 사용할 수 있습니다. 언어 식별을 다른 기능과 결합하는 경우 해당 기능에서 지원되는 언어로 제한됩니다. 예를 들어 콘텐츠 수정과 함께 언어 식별을 사용하는 경우 수정이 가능한 언어만 미국 영어 (en-US) 또는 미국 스페인어 (es-US) 로 제한됩니다. 자세한 내용은 지원되는 언어 및 언어별 기능 섹션을 참조하세요.
중요
콘텐츠 교정이 활성화된 상태에서 자동 언어 식별을 사용하고 오디오에 미국 영어 (en-US) 또는 미국 스페인어 (es-US) 이외의 언어가 포함된 경우 미국 영어 또는 미국 스페인어 콘텐츠만 자막에서 수정됩니다. 다른 언어는 편집할 수 없으며 경고나 작업 실패도 없습니다.
사용자 지정 언어 모델, 사용자 지정 어휘 및 사용자 지정 어휘 필터
언어 식별 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 하나 이상 추가하려면 LanguageIdSettings 파라미터를 포함해야 합니다. 그런 다음 해당하는 사용자 지정 언어 모델, 사용자 지정 어휘 및 사용자 지정 어휘 필터를 사용하여 언어 코드를 지정할 수 있습니다. 다국어 식별은 사용자 지정 언어 모델을 지원하지 않는다는 점에 유의하세요.
올바른 언어 방언을 식별할 수 있도록 LanguageIdSettings을 사용할 때 LanguageOptions을 포함하는 것이 좋습니다. 예를 들어 en-US 사용자 지정 어휘를 지정했지만 미디어에서 사용되는 언어가 해당 언어라고 Amazon Transcribe 판단되면 사용자 지정 어휘는 en-AU 트랜스크립션에 적용되지 않습니다. LanguageOptions을 포함하고 유일한 영어 방언으로 en-US를 지정하는 경우 사용자 지정 어휘가 트랜스크립션에 적용됩니다.
요청의 LanguageIdSettings 예시는 배치 트랜스크립션 작업을 통한 언어 식별 사용 섹션의 AWS CLI 및 AWS SDK 드롭다운 패널에서 옵션 2를 참조하세요.
배치 트랜스크립션 작업을 통한 언어 식별 사용
AWS Management Console, AWS CLI 또는 AWS SDK를 사용하여 배치 트랜스크립션 작업에서 자동 언어 식별을 사용할 수 있습니다. 예를 보려면 다음을 참조하세요.
-
AWS Management Console
에 로그인합니다. -
탐색 창에서 트랜스크립션 작업을 선택한 다음 작업 생성(오른쪽 상단)을 선택합니다. 그러면 작업 세부 정보 지정 페이지가 열립니다.
-
작업 설정 패널에서 언어 설정 섹션을 찾아 자동 언어 식별 또는 자동 다국어 식별을 선택합니다.
오디오 파일에 어떤 언어가 있는지 알고 있으면 (언어 선택 드롭다운 상자에서) 다국어 옵션을 선택할 수 있습니다. 언어 옵션을 제공하면 정확도를 높일 수 있지만 필수는 아닙니다.
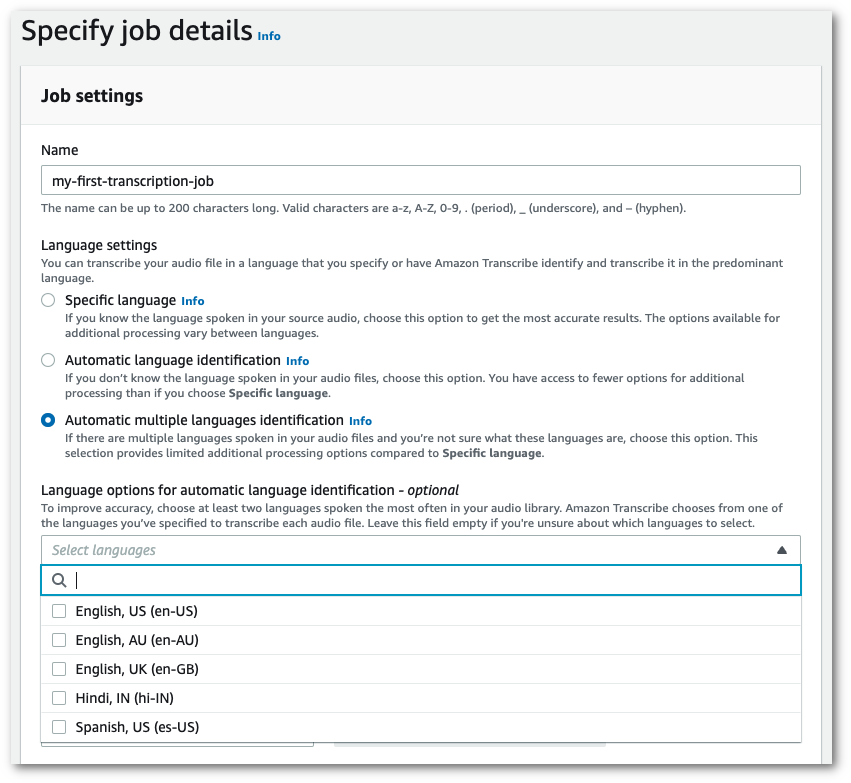
-
작업 세부 정보 지정 페이지에 포함하려는 다른 필드를 모두 채운 후 다음을 선택합니다. 그러면 작업 구성 - 선택 사항 페이지로 이동합니다.
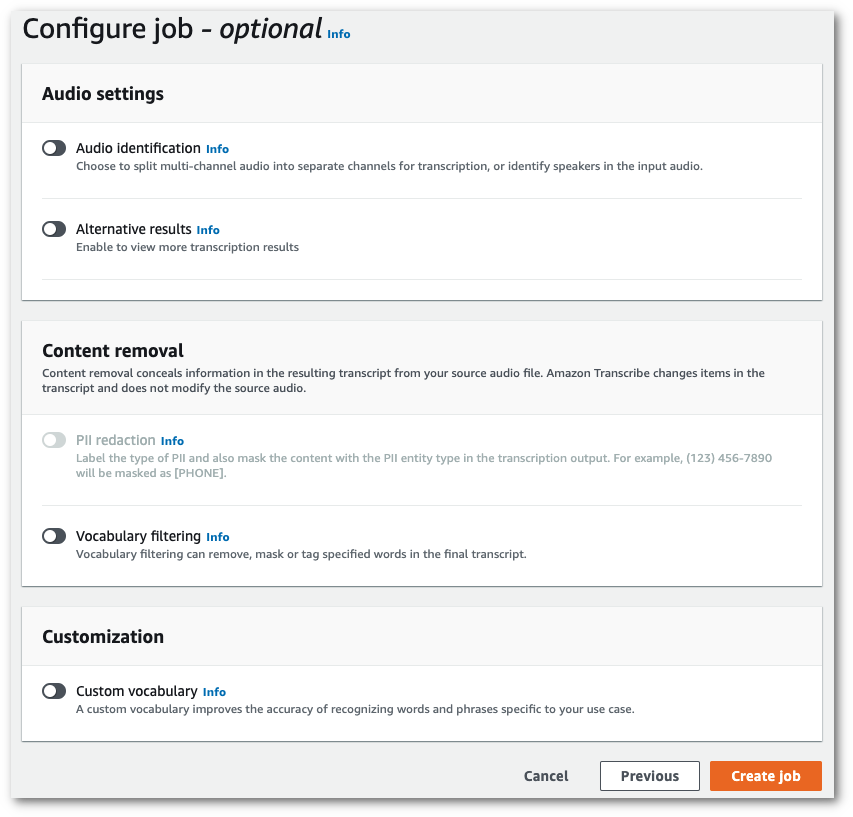
-
작업 생성을 선택하여 트랜스크립션 작업을 실행합니다.
이 예제에서는 start-transcription-jobIdentifyLanguage 자세한 내용은 StartTranscriptionJob 및 LanguageIdSettings 섹션을 참조하세요.
옵션 1: language-id-settings 파라미터 없음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하지 않는 경우 이 옵션을 사용합니다. language-options은 선택 사항이며, 권장 사항은 아닙니다.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) \ --language-options "en-US" "hi-IN"
옵션 2: language-id-settings 파라미터 있음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하는 경우 이 옵션을 사용합니다.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --identify-language \ (or --identify-multiple-languages) --language-options "en-US" "hi-IN" \ --language-id-settingsen-US=VocabularyName=my-en-US-vocabulary,en-US=VocabularyFilterName=my-en-US-vocabulary-filter,en-US=LanguageModelName=my-en-US-language-model,hi-IN=VocabularyName=my-hi-IN-vocabulary,hi-IN=VocabularyFilterName=my-hi-IN-vocabulary-filter
다음은 start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://filepath/my-first-language-id-job.json
my-first-language-id-job.json 파일에는 다음과 같은 요청 본문이 포함되어 있습니다.
옵션 1: LanguageIdSettings 파라미터 없음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하지 않는 경우 이 옵션을 사용합니다. LanguageOptions은 선택 사항이며, 권장 사항은 아닙니다.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true), "LanguageOptions": [ "en-US", "hi-IN" ] }
옵션 2: LanguageIdSettings 파라미터 있음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하는 경우 이 옵션을 사용합니다.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "IdentifyLanguage":true, (or "IdentifyMultipleLanguages":true) "LanguageOptions": [ "en-US", "hi-IN" ], "LanguageIdSettings": { "en-US" : { "LanguageModelName": "my-en-US-language-model", "VocabularyFilterName": "my-en-US-vocabulary-filter", "VocabularyName": "my-en-US-vocabulary" }, "hi-IN": { "VocabularyName": "my-hi-IN-vocabulary", "VocabularyFilterName": "my-hi-IN-vocabulary-filter" } } }
이 예제에서는 AWS SDK for Python (Boto3) 를 사용하여 start_transcription_job 메서드의 IdentifyLanguage 인수를 사용하여 파일의 언어를 식별합니다.StartTranscriptionJob 및 LanguageIdSettings 섹션을 참조하세요.
기능별, 시나리오 및 크로스 서비스 예제를 포함하여 AWS SDK를 사용하는 추가 예제는 이 장을 참조하십시오. 를 사용한 Amazon Transcribe의 코드 예제 AWS SDKs
옵션 1: LanguageIdSettings 파라미터 없음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하지 않는 경우 이 옵션을 사용합니다. LanguageOptions은 선택 사항이며, 권장 사항은 아닙니다.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat = 'flac', IdentifyLanguage =True, (or IdentifyMultipleLanguages =True), LanguageOptions = [ 'en-US', 'hi-IN' ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
옵션 2: LanguageIdSettings 파라미터 있음. 요청에 사용자 지정 언어 모델, 사용자 지정 어휘 또는 사용자 지정 어휘 필터를 포함하는 경우 이 옵션을 사용합니다.
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', MediaFormat='flac', IdentifyLanguage=True, (or IdentifyMultipleLanguages=True) LanguageOptions = [ 'en-US', 'hi-IN' ], LanguageIdSettings={ 'en-US': { 'VocabularyName': 'my-en-US-vocabulary', 'VocabularyFilterName': 'my-en-US-vocabulary-filter', 'LanguageModelName': 'my-en-US-language-model' }, 'hi-IN': { 'VocabularyName': 'my-hi-IN-vocabulary', 'VocabularyFilterName': 'my-hi-IN-vocabulary-filter' } } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
