AWS ParallelCluster processes
This section applies only to HPC clusters that are deployed with one of the supported traditional job schedulers (SGE, Slurm, or Torque). When used with these schedulers, AWS ParallelCluster manages compute node provisioning and removal by interacting with both the Auto Scaling group and the underlying job scheduler.
For HPC clusters that are based on AWS Batch, AWS ParallelCluster relies on the capabilities provided by the AWS Batch for the compute node management.
Note
Starting with version 2.11.5, AWS ParallelCluster doesn't support the use of SGE or Torque schedulers. You can continue using them in versions up to and including 2.11.4, but they aren't eligible for future updates or troubleshooting support from the AWS service and AWS Support teams.
SGE and Torque integration processes
Note
This section only applies to AWS ParallelCluster versions up to and including version 2.11.4. Starting with version 2.11.5, AWS ParallelCluster doesn't support the use of SGE and Torque schedulers, Amazon SNS, and Amazon SQS.
General overview
A cluster's lifecycle begins after it is created by a user. Typically, a cluster is created from the Command Line Interface (CLI). After it's created, a cluster exists until it's deleted. AWS ParallelCluster daemons run on the cluster nodes, mainly to manage the HPC cluster elasticity. The following diagram shows a user workflow and the cluster lifecycle. The sections that follow describe the AWS ParallelCluster daemons that are used to manage the cluster.

With SGE and Torque schedulers, AWS ParallelCluster uses nodewatcher, jobwatcher, and sqswatcher
processes.
jobwatcher
When a cluster is running, a process owned by the root user monitors the configured scheduler (SGE or Torque). Each minute it evaluates the queue in order to decide when to scale up.
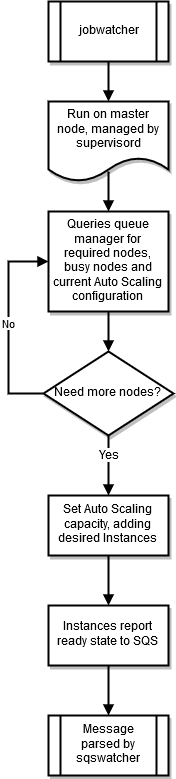
sqswatcher
The sqswatcher process monitors for Amazon SQS messages that are sent by Auto Scaling to notify you of state changes within the
cluster. When an instance comes online, it submits an "instance ready" message to Amazon SQS. This message is picked up by sqs_watcher,
running on the head node. These messages are used to notify the queue manager when new instances come online or are terminated, so they can be
added or removed from the queue.

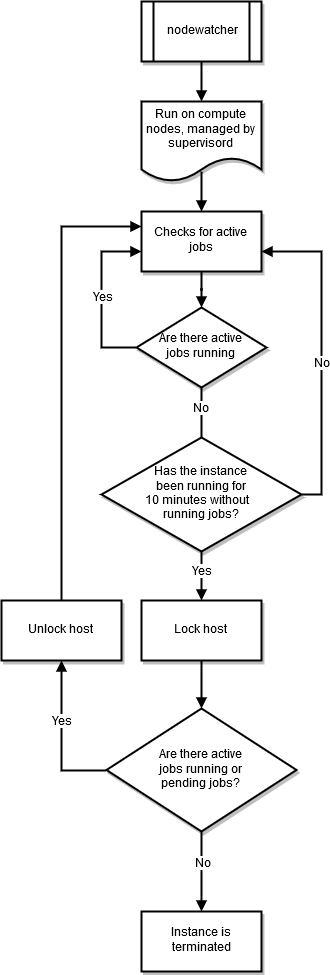
nodewatcher
The nodewatcher process runs on each node in the compute fleet. After the scaledown_idletime period, as defined by
the user, the instance is terminated.
Slurm integration processes
With Slurm schedulers, AWS ParallelCluster uses clustermgtd and computemgt
processes.
clustermgtd
Clusters that run in heterogeneous mode (indicated by specifying a queue_settings value) have a cluster management daemon (clustermgtd) process that runs on
the head node. These tasks are performed by the cluster management daemon.
-
Inactive partition clean-up
-
Static capacity management: make sure static capacity is always up and healthy
-
Sync scheduler with Amazon EC2.
-
Orphaned instance clean-up
-
Restore scheduler node status on Amazon EC2 termination that happens outside of the suspend workflow
-
Unhealthy Amazon EC2 instances management (failing Amazon EC2 health checks)
-
Scheduled maintenance events management
-
Unhealthy Scheduler nodes management (failing Scheduler health checks)
computemgtd
Clusters that run in heterogeneous mode (indicated by specifying a queue_settings value) have compute management daemon (computemgtd) processes that run on
each of the compute node. Every five (5) minutes, the compute management daemon confirms that the head node can be
reached and is healthy. If five (5) minutes pass during which the head node cannot be reached or is not healthy, the
compute node is shut down.
