As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Minimizando o tempo de inatividade ElastiCache usando o Valkey e o Multi-AZ Redis OSS
Há vários casos em que, ElastiCache para Valkey e Redis, o OSS pode precisar substituir um nó primário; isso inclui certos tipos de manutenção planejada e o evento improvável de uma falha no nó primário ou na zona de disponibilidade.
Essa substituição resulta em algum tempo de inatividade para o cluster, mas se Multi-AZ estiver ativada, o tempo de inatividade será minimizado. A função do nó primário fará failover automaticamente para uma das réplicas de leitura. Não há necessidade de criar e provisionar um novo nó primário, pois ElastiCache trataremos disso de forma transparente. O failover e a promoção de réplica garantem que você possa continuar a gravar no novo primário assim que a promoção estiver concluída.
ElastiCache também propaga o nome do Serviço de Nomes de Domínio (DNS) da réplica promovida. Isso ocorre porque, em seguida, se o seu aplicativo estiver gravando no endpoint primário, nenhuma alteração nesse endpoint será necessária no seu aplicativo. Se estiver lendo de endpoints individuais, altere o endpoint de leitura da réplica promovida a primária para o endpoint da nova réplica.
No caso de substituições de nó planejadas, iniciadas devido a atualizações de manutenção ou atualizações de autoatendimento, esteja ciente do seguinte:
Para clusters do Valkey e Redis OSS, as substituições de nó planejadas são concluídas enquanto o cluster atende às solicitações de gravação recebidas.
Para clusters desativados no modo de cluster Valkey e Redis OSS com Multi-AZ habilitado que são executados no mecanismo 5.0.6 ou posterior, as substituições planejadas dos nós são concluídas enquanto o cluster atende às solicitações de gravação recebidas.
Para clusters desativados no modo de cluster Valkey e Redis OSS com o modo de cluster Multi-AZ habilitado que são executados no mecanismo 4.0.10 ou anterior, você pode notar uma breve interrupção de gravação associada às atualizações de DNS. Essa interrupção pode levar até alguns segundos. Esse processo é muito mais rápido do que recriar e provisionar um novo primário, que é o que ocorre se você não habilitar. Multi-AZ
Você pode habilitar Multi-AZ usando o ElastiCache Management Console AWS CLI, o ou a ElastiCache API.
nota
Durability-enabled clusters: para clusters Valkey 9.0+ com durabilidade ativada, o comportamento de failover é diferente dos cenários descritos abaixo. Com durabilidade, todos os dados comprometidos são mantidos em um registro Multi-AZ transacional. Durante os failovers, as gravações síncronas garantem zero perda de dados, enquanto as gravações assíncronas podem perder até 10 segundos de dados não confirmados. Os nós com falha restauram todos os dados confirmados do registro transacional sem exigir uma sincronização completa do primário. Para obter mais informações, consulte Durabilidade em ElastiCache.
A ativação ElastiCache Multi-AZ em seu cluster Valkey ou Redis OSS (na API e na CLI, grupo de replicação) melhora sua tolerância a falhas. Isso é verdade principalmente nos casos em que o cluster read/write primário do seu cluster fica inacessível ou falha por qualquer motivo. Multi-AZ só é compatível com clusters Valkey e Redis OSS com mais de um nó em cada fragmento.
Tópicos
Habilitando Multi-AZ
Você pode ativar Multi-AZ ao criar ou modificar um cluster (API ou CLI, grupo de replicação) usando o ElastiCache console ou a AWS CLI API. ElastiCache
Você pode habilitar Multi-AZ somente em clusters Valkey ou Redis OSS (modo de cluster desativado) que tenham pelo menos uma réplica de leitura disponível. Clusters sem réplicas de leitura não fornece alta disponibilidade ou tolerância a falhas. Para obter informações sobre como criar um cluster com replicação, consulte Criação de um grupo de replicação do Valkey ou Redis OSS. Para obter informações sobre como adicionar uma réplica de leitura a um cluster com replicação, consulte Adição de uma réplica de leitura do Valkey ou do Redis OSS (modo cluster desabilitado).
Tópicos
Habilitando Multi-AZ (Console)
Você pode ativar o Multi-AZ uso do ElastiCache console ao criar um novo cluster Valkey ou Redis OSS ou ao modificar um cluster existente com replicação.
Multi-AZ é habilitado por padrão nos clusters Valkey ou Redis OSS (modo de cluster ativado).
Importante
ElastiCache será ativado automaticamente Multi-AZ somente se o cluster contiver pelo menos uma réplica em uma zona de disponibilidade diferente da primária em todos os fragmentos.
Ativando Multi-AZ ao criar um cluster usando o ElastiCache console
Para obter mais informações sobre esse processo, consulte Criação de um cluster do Valkey (modo cluster desabilitado) (console). Certifique-se de ter uma ou mais réplicas e habilite Multi-AZ.
Habilitando Multi-AZ em um cluster existente (console)
Para obter mais informações sobre esse processo, consulte Modificação de um cluster Usando o ElastiCache Console de gerenciamento da AWS.
Habilitando Multi-AZ (AWS CLI)
O exemplo de código a seguir usa o AWS CLI Multi-AZ para habilitar o grupo redis12 de replicação.
Importante
O grupo de replicação redis12 já deve existir e ter pelo menos uma réplica de leitura disponível.
Para Linux, macOS ou Unix:
aws elasticache modify-replication-group \ --replication-group-idredis12\ --automatic-failover-enabled \ --multi-az-enabled \ --apply-immediately
Para Windows:
aws elasticache modify-replication-group ^ --replication-group-idredis12^ --automatic-failover-enabled ^ --multi-az-enabled ^ --apply-immediately
A saída JSON desse comando deve ser semelhante ao seguinte.
{
"ReplicationGroup": {
"Status": "modifying",
"Description": "One shard, two nodes",
"NodeGroups": [
{
"Status": "modifying",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-001.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis12-002.v5r9dc.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis12-002"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis12.v5r9dc.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ReplicationGroupId": "redis12",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabling",
"MultiAZ": "enabled",
"SnapshotWindow": "07:00-08:00",
"SnapshottingClusterId": "redis12-002",
"MemberClusters": [
"redis12-001",
"redis12-002"
],
"PendingModifiedValues": {}
}
}Para obter mais informações, consulte estes tópicos na AWS CLI Referência de comandos:
-
modify-replication-group na AWS CLI Referência de comandos.
Habilitando Multi-AZ (ElastiCache API)
O exemplo de código a seguir usa a ElastiCache API Multi-AZ para habilitar o grupo redis12 de replicação.
nota
Para usar esse exemplo, o grupo de replicação redis12 já deve existir e ter pelo menos uma réplica de leitura disponível.
https://elasticache.us-west-2.amazonaws.com/ ?Action=ModifyReplicationGroup &ApplyImmediately=true &AutoFailover=true &MultiAZEnabled=true &ReplicationGroupId=redis12 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Para obter mais informações, veja estes tópicos na ElastiCache Referência da API:
Cenários de falha com Multi-AZ respostas
Antes da introdução Multi-AZ, ElastiCache detectei e substituiu os nós com falha de um cluster, recriando e reprovisionando o nó com falha. Se você habilitar Multi-AZ, um nó primário com falha fará o failover para a réplica com o menor atraso de replicação. A réplica selecionada é promovida automaticamente para primário, o que é muito mais rápido do que criar e reprovisionar um novo nó primário. Esse processo normalmente demora apenas alguns segundos até que você possa gravar novamente no cluster.
Quando Multi-AZ ativado, monitora ElastiCache continuamente o estado do nó primário. Se o nó primário falhar, uma das seguintes ações será realizada, dependendo do tipo da falha.
Tópicos
Cenários de falha quando somente o nó primário falha
Se somente o nó primário falhar, a réplica de leitura com o menor atraso de replicação será promovida a primária. Depois disso, uma réplica de leitura de substituição é criada e provisionada na mesma zona de disponibilidade que o primário com falha.
Quando somente o nó primário falha, ElastiCache Multi-AZ faça o seguinte:
O nó primário com falha é colocado offline.
A réplica de leitura com o menor atraso de replicação é promovida a primário.
As gravações poderão ser retomadas assim que o processo de promoção estiver concluído, normalmente depois de apenas alguns segundos. Se seu aplicativo estiver gravando no endpoint primário, não será necessário alterar o endpoint para gravações ou leituras. O ElastiCache propagará o nome DNS da réplica promovida.
Uma réplica de leitura de substituição é executada e provisionada.
A réplica de leitura de substituição é executada na Zona de disponibilidade em que o nó primário com falha se encontrava, para que a distribuição de nós seja mantida.
As réplicas são sincronizadas com o novo nó primário.
Depois que a nova réplica estiver disponível, lembre-se dos seguintes efeitos:
-
Endpoint primário: não faça alterações na sua aplicação, pois o nome do DNS do novo nó primário é propagado para o endpoint primário.
-
Endpoint leitor: o endpoint leitor é atualizado automaticamente para apontar para os novos nós de réplica.
Para obter informações sobre como encontrar os endpoints de um cluster, consulte os seguintes tópicos:
Cenários de falha quando o nó primário e algumas réplicas de leitura falham
Se o primário e pelo menos uma réplica de leitura falhar, a réplica disponível com o menor atraso de replicação será promovida a cluster primário. Novas réplicas de leitura também são criadas e provisionadas nas mesmas Zonas de disponibilidade que os nós com falha e a réplica que foi promovida a primário.
Quando o nó primário e algumas réplicas de leitura falham, ElastiCache Multi-AZ faça o seguinte:
O nó primário com falha e as réplicas de leitura com falha são colocadas offline.
A réplica disponível com o menor atraso de replicação é promovida a nó primário.
As gravações poderão ser retomadas assim que o processo de promoção estiver concluído, normalmente depois de apenas alguns segundos. Se seu aplicativo estiver gravando no endpoint primário, não há necessidade de alterar o endpoint para gravações. ElastiCache propaga o nome DNS da réplica promovida.
Réplicas de substituição são criadas e provisionadas.
As réplicas de substituição são criadas nas Zonas de disponibilidade dos nós com falha, de modo que a distribuição de nós seja mantida.
Todos os clusters são sincronizados com o novo nó primário.
Faça as seguintes alterações no seu aplicativo depois que os novos nós estiverem disponíveis:
-
Endpoint primário: não faça alterações em sua aplicação. O nome de DNS do novo nó primário é propagado para o endpoint primário.
-
Endpoint leitor: o endpoint leitor é atualizado automaticamente para apontar para os novos nós de réplica.
Para obter informações sobre como encontrar os endpoints de um grupo de replicação, consulte os seguintes tópicos:
Cenários de falha quando cluster inteiro falha
Se tudo falhar, todos os nós serão recriados e provisionados nas mesmas Zonas de disponibilidade que os nós originais.
Nesse cenário, todos os dados do cluster são perdidos devido à falha de cada nó no cluster. Essa ocorrência é rara.
Quando todo o cluster falhar, ElastiCache Multi-AZ faça o seguinte:
O nó primário e as réplicas de leitura com falha são colocados offline.
Um nó primário de substituição é criado e provisionado.
Réplicas de substituição são criadas e provisionadas.
As substituição são criadas nas Zonas de disponibilidade dos nós com falha, de modo que a distribuição de nós seja mantida.
Como o cluster inteiro falhou, os dados são perdidos, e todos os novos nós são iniciados a frio.
Como cada um dos nós de substituição tem o mesmo endpoint que o nó que ele está substituindo, não é necessário fazer alterações de endpoint no seu aplicativo.
Para obter informações sobre como encontrar os endpoints de um grupo de replicação, consulte os seguintes tópicos:
Recomendamos que você crie o nó primário e as réplicas de leitura em diferentes Zonas de disponibilidade para aumentar o nível de tolerância a falhas.
Teste do failover automático
Depois de ativar o failover automático, você pode testá-lo usando o ElastiCache console AWS CLI, o e a ElastiCache API.
Ao testar, observe o seguinte:
-
Você pode usar essa operação para testar o failover automático em até 15 fragmentos (chamados de grupos de nós na ElastiCache API e AWS CLI) em qualquer período contínuo de 24 horas.
-
Se você chamar essa operação em estilhaços em clusters diferentes (chamados grupos de replicação na API e CLI), poderá fazer as chamadas simultaneamente.
-
Em alguns casos, é possível chamar essa operação várias vezes em diferentes fragmentos no mesmo grupo de replicação do Valkey ou Redis OSS (modo cluster habilitado). Nesses casos, a substituição do primeiro nó deve ser concluída antes que uma chamada subsequente possa ser feita.
-
Para determinar se a substituição do nó foi concluída, verifique os eventos usando o ElastiCache console da Amazon AWS CLI, o ou a ElastiCache API. Procure pelos seguintes eventos relacionados ao failover automático, listados aqui em ordem de ocorrência:
-
Mensagem do grupo de replicação:
Test Failover API called for node group <node-group-id> -
Mensagem do cluster de cache:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Mensagem do grupo de replicação:
Failover from primary node <primary-node-id> to replica node <node-id> completed -
Mensagem do cluster de cache:
Recovering cache nodes <node-id> -
Mensagem do cluster de cache:
Finished recovery for cache nodes <node-id>
Para saber mais, consulte:
-
Visualizando ElastiCache eventos no ElastiCache Guia do usuário
-
DescribeEvents na Referência de API do ElastiCache
-
describe-events na AWS CLI Referência de comandos.
-
Essa API foi projetada para testar o comportamento do seu aplicativo em caso de ElastiCache failover. Ela não foi projetada para ser uma ferramenta operacional para iniciar um failover a fim de resolver um problema com o cluster. Além disso, em determinadas condições, como eventos operacionais de grande escala, AWS pode bloquear essa API.
Tópicos
Testando o failover automático usando o Console de gerenciamento da AWS
Use o procedimento a seguir para testar o failover automático com o console.
Para testar o failover automático
-
Faça login no Console de gerenciamento da AWS e abra o ElastiCache console em https://console.aws.amazon.com/elasticache/
. -
No painel de navegação, escolha Valkey ou Redis OSS.
-
Na lista de clusters, escolha a caixa à esquerda do cluster que deseja testar. Esse cluster deve ter pelo menos um nó de réplica de leitura.
-
Na área Detalhes, confirme se esse cluster está Multi-AZ ativado. Se o cluster não Multi-AZ estiver ativado, escolha um cluster diferente ou modifique esse cluster para habilitá-lo Multi-AZ. Para obter mais informações, consulte Usando o ElastiCache Console de gerenciamento da AWS.
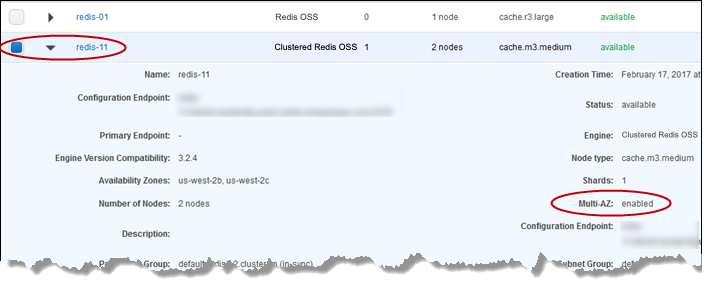
Para o Valkey ou Redis OSS (modo cluster desabilitado), escolha o nome do cluster.
Para o Valkey ou Redis OSS (modo cluster habilitado), faça o seguinte:
-
Escolha o nome do cluster.
-
Na página Shards, para o estilhaço (chamado de grupo de nó na API e na CLI) no qual você deseja testar o failover, escolha o nome do estilhaço.
-
-
Na página Nodes, escolha Failover Primary.
-
Escolha Continue para fazer failover do primário ou Cancel para cancelar a operação e não fazer failover do nó primário.
Durante o processo de failover, o console continua a mostrar o status do nó como disponível. Para acompanhar o progresso do seu teste de failover, escolha Events no painel de navegação do console. Na guia Eventos, observe os eventos que indicam que o failover foi iniciado (
Test Failover API called) e concluído (Recovery completed).
Testando o failover automático usando o AWS CLI
Você pode testar o failover automático em qualquer cluster Multi-AZ ativado usando a AWS CLI operaçãotest-failover.
Parâmetros
-
--replication-group-id: obrigatório. O grupo de replicação (no console, cluster) que deve ser testado. -
--node-group-id: obrigatório. O nome do grupo de nós nos quais você deseja testar o failover automático. Você pode testar um máximo de 15 grupos de nós em um período contínuo de 24 horas.
O exemplo a seguir usa o AWS CLI para testar o failover automático no grupo de nós redis00-0003 no cluster Valkey ou Redis OSS (modo de cluster ativado). redis00
exemplo Teste de failover automático
Para Linux, macOS ou Unix:
aws elasticache test-failover \ --replication-group-idredis00\ --node-group-idredis00-0003
Para Windows:
aws elasticache test-failover ^ --replication-group-idredis00^ --node-group-idredis00-0003
A saída do comando precedente é semelhante ao seguinte.
{
"ReplicationGroup": {
"Status": "available",
"Description": "1 shard, 3 nodes (1 + 2 replicas)",
"NodeGroups": [
{
"Status": "available",
"NodeGroupMembers": [
{
"CurrentRole": "primary",
"PreferredAvailabilityZone": "us-west-2c",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-001.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-001"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2a",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-002.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-002"
},
{
"CurrentRole": "replica",
"PreferredAvailabilityZone": "us-west-2b",
"CacheNodeId": "0001",
"ReadEndpoint": {
"Port": 6379,
"Address": "redis1x3-003.7ekv3t.0001.usw2.cache.amazonaws.com"
},
"CacheClusterId": "redis1x3-003"
}
],
"NodeGroupId": "0001",
"PrimaryEndpoint": {
"Port": 6379,
"Address": "redis1x3.7ekv3t.ng.0001.usw2.cache.amazonaws.com"
}
}
],
"ClusterEnabled": false,
"ReplicationGroupId": "redis1x3",
"SnapshotRetentionLimit": 1,
"AutomaticFailover": "enabled",
"MultiAZ": "enabled",
"SnapshotWindow": "11:30-12:30",
"SnapshottingClusterId": "redis1x3-002",
"MemberClusters": [
"redis1x3-001",
"redis1x3-002",
"redis1x3-003"
],
"CacheNodeType": "cache.m3.medium",
"DataTiering": "disabled",
"PendingModifiedValues": {}
}
}Para acompanhar o progresso do seu failover, use a AWS CLI describe-events operação.
Para saber mais, consulte:
-
test-failover na AWS CLI Referência de comandos.
-
describe-events na AWS CLI Referência de comandos.
Testando o failover automático usando a API ElastiCache
Você pode testar o failover automático em qualquer cluster habilitado com o Multi-AZ uso da operação TestFailover de ElastiCache API.
Parâmetros
-
ReplicationGroupId: obrigatório. O grupo de replicação (no console ou cluster) a ser testado. -
NodeGroupId: obrigatório. O nome do grupo de nós nos quais você deseja testar o failover automático. Você pode testar um máximo de 15 grupos de nós em um período contínuo de 24 horas.
O exemplo a seguir testa o failover automático no grupo de nós redis00-0003 no grupo de replicação (no console, cluster) redis00.
exemplo Teste do failover automático
https://elasticache.us-west-2.amazonaws.com/ ?Action=TestFailover &NodeGroupId=redis00-0003 &ReplicationGroupId=redis00 &Version=2015-02-02 &SignatureVersion=4 &SignatureMethod=HmacSHA256 &Timestamp=20140401T192317Z &X-Amz-Credential=<credential>
Para acompanhar o progresso do seu failover, use a operação da ElastiCache DescribeEvents API.
Para saber mais, consulte:
-
TestFailoverna Referência da ElastiCache API
-
DescribeEventsna Referência da ElastiCache API
Limitações em Multi-AZ
Esteja ciente das seguintes limitações para Multi-AZ:
-
Multi-AZ é suportado no Valkey e no Redis OSS versão 2.8.6 e posterior.
-
Multi-AZ não é compatível com os tipos de nós T1.
-
A replicação do Valkey e Redis OSS é assíncrona. Portanto, quando um nó primário faz failover em uma réplica, uma pequena quantidade de dados pode ser perdida devido ao atraso da replicação. Para clusters com durabilidade ativada, essa limitação não se aplica — todos os dados confirmados são restaurados do Multi-AZ registro transacional.
Ao escolher a réplica a ser promovida a primária, ElastiCache escolhe a réplica com o menor atraso de replicação. Em outras palavras, ele escolha a réplica que é mais atual. Isso ajuda a minimizar a quantidade de dados perdidos. A réplica com o atraso de replicação mínimo pode estar na mesma zona de disponibilidade ou em outra em relação ao nó primário com falha.
-
Quando você promove manualmente réplicas de leitura para primárias em clusters Valkey ou Redis OSS com o modo de cluster desativado, você só pode fazer isso quando Multi-AZ o failover automático está desativado. Para promover uma réplica de leitura para primário, execute as seguintes etapas:
-
Desative Multi-AZ no cluster.
-
Desabilite o failover automático no cluster. Isso pode ser feito por meio do console desmarcando a caixa de seleção Failover automático para o grupo de replicação. Você também pode fazer isso usando o AWS CLI definindo a
AutomaticFailoverEnabledpropriedade comofalseao chamar aModifyReplicationGroupoperação. -
Promova a réplica de leitura para primário.
-
Re-enable Multi-AZ.
-
-
ElastiCache para Redis, o OSS Multi-AZ e o arquivo somente para anexar (AOF) são mutuamente exclusivos. Se você habilitar um, não é possível habilitar o outro.
-
Uma falha de um nó pode ser causada pelo evento raro de falha total de uma zona de disponibilidade. Neste caso, a réplica que substitui o primário com falha é criada somente quando a zona de disponibilidade volta a ficar ativa. Por exemplo, considere um grupo de replicação com a entrada primária AZ-a e as réplicas em e. AZ-b AZ-c Se o primário falhar, a réplica com o menor atraso de replicação será promovida a cluster primário. Em seguida, ElastiCache cria uma nova réplica AZ-a (onde o primário com falha estava localizado) somente quando AZ-a está de volta e disponível.
-
Uma reinicialização iniciada pelo cliente de um primário não aciona o failover automático. Outras reinicializações e falhas desencadeiam o failover automático.
-
Quando o primário é reiniciado, seus dados são limpos quando ele volta a ficar online. Quando as réplicas de leitura veem o cluster primário limpo, elas limpam suas cópias dos dados, o que causa perda de dados.
-
Depois que uma réplica de leitura foi promovida, as outras réplicas se sincronizam com o novo primário. Após a sincronização inicial, o conteúdo das réplicas é excluído, e eles sincronizam os dados do novo primário. Esse processo de sincronização causa uma breve interrupção, durante a qual as réplicas não são acessíveis. O processo de sincronização também causa um aumento de carga temporário no primário durante a sincronização com as réplicas. Esse comportamento é nativo do Valkey e do Redis OSS e não é exclusivo do. ElastiCache Multi-AZ Para obter detalhes sobre esse comportamento, consulte Replicação
no site do Valkey. Para clusters com durabilidade habilitada, as réplicas são restauradas do registro transacional de forma independente, sem impor carga ao primário.
Importante
Para Valkey 7.2.6 e posterior ou Redis OSS versão 2.8.22 e posterior, não é possível criar réplicas externas.
Para versões do Redis OSS anteriores à 2.8.22, recomendamos que você não conecte uma réplica externa a um ElastiCache cluster habilitado. Multi-AZ Essa configuração não suportada pode criar problemas que impedem a execução adequada ElastiCache do failover e da recuperação. Para conectar uma réplica externa a um ElastiCache cluster, verifique se ela Multi-AZ não está ativada antes de fazer a conexão.
