As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Alta disponibilidade com o uso de grupos de replicação
Os OSS clusters Amazon ElastiCache Valkey e Redis de nó único são entidades na memória com serviços limitados de proteção de dados (). AOF Se o seu cluster falhar por qualquer motivo, você perderá todos os dados do cluster. No entanto, se você estiver executando um OSS mecanismo Valkey ou Rediss, poderá agrupar de 2 a 6 nós em um cluster com réplicas em que 1 a 5 nós somente para leitura contêm dados replicados do único nó do grupo que falhou. read/write primary node. In this scenario, if one node fails for any reason, you do not lose all your data since it is replicated in one or more other nodes. Due to replication latency, some data may be lost if it is the primary read/write
Conforme visto no gráfico a seguir, a estrutura de replicação está contida em um fragmento (chamado grupo de nós noAPI/CLI) que está contido em um cluster Valkey ou Redis. OSS Os clusters Valkey ou Redis OSS (modo de cluster desativado) sempre têm um fragmento. Os clusters Valkey ou Redis OSS (modo de cluster ativado) podem ter até 500 fragmentos com os dados do cluster particionados entre os fragmentos. É possível criar um cluster com alto número de fragmentos e baixo número de réplicas totalizando até 90 nós por cluster. Essa configuração do cluster pode variar de 90 fragmentos e 0 réplicas para 15 fragmentos e 5 réplicas, que é o número máximo de réplicas permitidas.
O limite de nós ou fragmentos pode ser aumentado para um máximo de 500 por cluster com o Valkey e com a ElastiCache versão 5.0.6 ou superior ElastiCache para o Redis. OSS Por exemplo, você pode optar por configurar um cluster de 500 nós que varia entre 83 fragmentos (uma primária e 5 réplicas por fragmento) e 500 fragmentos (primário único e sem réplicas). Verifique se existem endereços IP disponíveis suficientes para acomodar o aumento. As armadilhas comuns incluem que as sub-redes no grupo de sub-redes têm um CIDR intervalo muito pequeno ou as sub-redes são compartilhadas e muito usadas por outros clusters. Para obter mais informações, consulte Criação de um grupo de sub-redes.
Para versões abaixo de 5.0.6, o limite é 250 por cluster.
Para solicitar um aumento de limite, consulte Limites de serviço da AWS e selecione o tipo de limite Nodes per cluster per instance type (Nós por cluster por tipo de instância).
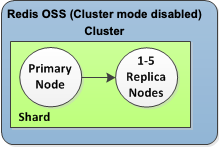
O cluster Valkey ou Redis OSS (modo de cluster desativado) tem um fragmento e 0 a 5 nós de réplica
Se o cluster com réplicas tiver o Multi-AZ habilitado e o nó primário falhar, esse nó primário executará failover em uma réplica de leitura. Como os dados são atualizados nos nós de réplica de forma assíncrona, pode haver alguma perda de dados devido à latência na atualização dos nós de réplica. Para obter mais informações, consulte Mitigar falhas ao executar o Valkey ou Redis OSS.
Tópicos
