Clusters de banco de dados do Amazon Aurora
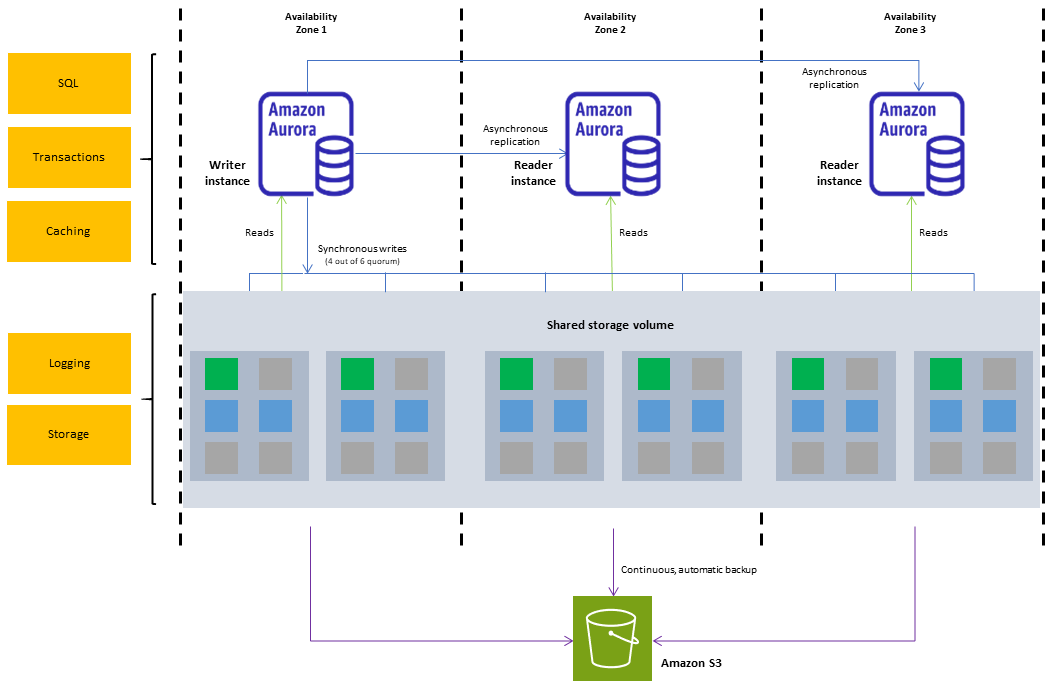
Um cluster de banco de dados do Amazon Aurora consiste em uma ou mais instâncias de banco de dados e em um volume de cluster que gerencia os dados para essas instâncias de banco de dados. Um volume de cluster do Aurora é um volume de armazenamento de banco de dados virtual que abrange várias zonas de disponibilidade, em que cada zona de disponibilidade conta com uma cópia dos dados do cluster de banco de dados. Um cluster de banco de dados do Aurora é composto por dois tipos de instâncias de banco de dados:
-
Instância de banco de dados primária (gravador): comporta operações de leitura e de gravação, além de realizar todas as modificações de dados no volume do cluster. Cada cluster de banco de dados do Aurora tem uma instância de banco de dados primária.
-
Réplica do Aurora (instância de banco de dados de leitor): conecta-se ao mesmo volume de armazenamento da instância de banco de dados primária, mas comporta apenas operações de leitura. Cada cluster de banco de dados do Aurora pode ter até 15 réplicas do Aurora, além da instância de banco de dados primária. Mantenha a alta disponibilidade localizando réplicas do Aurora em zonas de disponibilidade separadas. O Aurora faz o failover automaticamente para uma réplica do Aurora, caso a instância do banco de dados primário torne-se indisponível. Você pode especificar a prioridade de failover para réplicas do Aurora. As réplicas do Aurora também podem descarregar cargas de trabalho de leitura da instância de banco de dados primária.
O diagrama a seguir ilustra a relação entre o volume do cluster, a instância de banco de dados de gravador e as instâncias de banco de dados de leitor em um cluster de banco de dados do Aurora.
nota
As informações anteriores se aplicam a todos os clusters de banco de dados do Aurora: provisionados, de consulta paralela, do Aurora Global Database, do Aurora Serverless, compatíveis com o Aurora MySQL e com o Aurora PostgreSQL.
O cluster de banco de dados do Aurora ilustra a separação entre o armazenamento e a capacidade computacional. Por exemplo, uma configuração do Aurora com apenas uma única instância de banco de dados ainda é um cluster, pois o volume de armazenamento subjacente envolve vários nós de armazenamento distribuídos em diversas zonas de disponibilidade (AZs).
As operações de entrada e saída (E/S) nos clusters de banco de dados do Aurora são contadas da mesma forma, independentemente de estarem em uma instância de banco de dados de gravador ou leitor. Para obter mais informações, consulte Configurações de armazenamento para clusters de banco de dados do Amazon Aurora.
