Migrar dados de uma instância de banco de dados do RDS for PostgreSQL para um cluster de bancos de dados Aurora PostgreSQL usando uma réplica de leitura do Aurora
Você pode usar uma instância de banco de dados do RDS for PostgreSQL como base para um novo cluster de banco de dados Aurora PostgreSQL usando uma réplica de leitura do Aurora. A opção de réplica de leitura do Aurora está disponível apenas para migração dentro da mesma Região da AWS e conta, e estará disponível somente se a região oferecer uma versão compatível do Aurora PostgreSQL para sua instância de banco de dados do RDS for PostgreSQL. Compatível significa que a versão do Aurora PostgreSQL é a mesma versão do RDS for PostgreSQL, ou que é uma versão secundária posterior na mesma família de versões principais.
Por exemplo, para usar essa técnica ao migrar uma instância de banco de dados do RDS for PostgreSQL 11.14, a região deve oferecer o Aurora PostgreSQL versão 11.14 ou uma versão secundária posterior na família PostgreSQL versão 11.
Tópicos
Visão geral da migração de dados usando uma réplica de leitura do Aurora
Migrar de uma instância de banco de dados do RDS for PostgreSQL para um cluster de banco de dados Aurora PostgreSQL é um procedimento com várias etapas. Primeiro, você cria uma réplica de leitura do Aurora da instância de banco de dados do RDS for PostgreSQL de origem. Isso inicia um processo de replicação da instância de banco de dados do RDS for PostgreSQL para um cluster de banco de dados de finalidade especial conhecido como cluster de réplica. O cluster de réplica consiste exclusivamente em uma réplica de leitura do Aurora (uma instância do leitor).
nota
Pode levar algumas horas por tebibyte de dados para que a migração seja concluída.
Promoção de uma réplica do Aurora PostgreSQL
Depois de criar um cluster de banco de dados do Aurora PostgreSQL, siga estas etapas para promover a réplica do Aurora:
-
Pare todo a workload de gravação de banco de dados na instância de banco de dados do RDS for PostgreSQL de origem.
-
Obtenha o
WAL LSNatual da instância de banco de dados do RDS para PostgreSQL de origem:SELECT pg_current_wal_lsn();pg_current_wal_lsn -------------------- 0/F0000318 (1 row) -
No cluster de réplica do Aurora PostgreSQL, verifique se o LSN reproduzido é maior que o LSN da etapa 2:
SELECT pg_last_wal_replay_lsn();pg_last_wal_replay_lsn ------------------------ 0/F0000400 (1 row)Como alternativa, você pode usar a seguinte consulta na instância de banco de dados do RDS para PostgreSQL de origem:
SELECT restart_lsn FROM pg_replication_slots; -
Promova o cluster de réplica do Aurora PostgreSQL.
Quando a replicação é interrompida, o cluster de réplica é promovido a um cluster de banco de dados do Aurora PostgreSQL autônomo e o leitor é promovido a instância do gravador do cluster. Nesse ponto, você pode adicionar instâncias ao cluster de banco de dados do Aurora PostgreSQL para dimensioná-lo de acordo com seu caso de uso. Se você não precisar mais da instância de banco de dados do RDS para PostgreSQL original, poderá excluí-la.
Não será possível criar uma réplica de leitura do Aurora se a instância de banco de dados do RDS for PostgreSQL já tiver uma réplica de leitura do Aurora ou uma réplica de leitura entre regiões.
Preparação para migrar dados usando uma réplica de leitura do Aurora
nota
Ao se preparar para migrar dados para o Aurora PostgreSQL, é importante identificar e lidar adequadamente com as tabelas não registradas. Para obter mais informações, consulte Manipular tabelas não registradas em log durante a migração.
Durante o processo de migração usando a réplica de leitura do Aurora, as atualizações feitas na instância de banco de dados do RDS for PostgreSQL de origem são replicadas de forma assíncrona na réplica de leitura do Aurora do cluster de réplica. O processo usa a funcionalidade de replicação de transmissão nativa do PostgreSQL, que armazena segmentos Write-Ahead Logs (WAL – Logs de gravação antecipada) na instância de origem. Antes de iniciar esse processo de migração, certifique-se de que sua instância tenha capacidade de armazenamento suficiente verificando os valores das métricas listadas na tabela.
| Métrica | Descrição |
|---|---|
|
|
O espaço de armazenamento disponível. Unidade: bytes |
|
|
O tamanho do atraso dos dados de WAL na réplica que está demorando mais. Unidades: megabytes |
|
|
A quantidade de tempo em segundos que um cluster de bancos de dados Aurora PostgreSQL atrasa em comparação com a instância de banco de dados do RDS de origem. |
|
|
O espaço em disco usado pelos logs de transação. Unidades: megabytes |
Para ter mais informações sobre o monitoramento da instância do RDS, consulte Monitoramento no Manual do usuário da Amazon RDS.
Criar uma réplica de leitura do Aurora
Você pode criar uma réplica de leitura do Aurora para uma instância de banco de dados do RDS for PostgreSQL usando o Console de gerenciamento da AWS ou a AWS CLI. A opção de criar uma réplica de leitura do Aurora usando o Console de gerenciamento da AWS estará disponível somente se a Região da AWS oferecer uma versão compatível do Aurora PostgreSQL. Ou seja, estará disponível apenas se houver uma versão do Aurora PostgreSQL idêntica à versão do RDS for PostgreSQL ou uma versão secundária posterior na mesma família de versões principais.
Como criar uma réplica de leitura do Aurora a partir de uma instância de banco de dados PostgreSQL de origem
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Bancos de dados.
-
Escolha a instância de banco de dados do RDS for PostgreSQL que você deseja usar como a fonte da réplica de leitura do Aurora. Em Actions (Ações), selecione Create Aurora read replica (Criar réplica de leitura do Aurora). Se essa opção não for exibida, significa que uma versão compatível do Aurora PostgreSQL não está disponível na região.
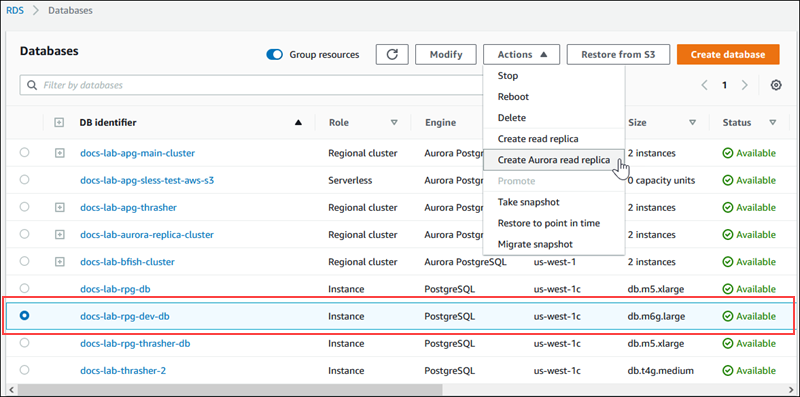
-
Na página “Create Aurora read replica settings” (Criar configurações de réplica de leitura do Aurora), você configura as propriedades do cluster de banco de dados Aurora PostgreSQL conforme mostrado na tabela a seguir. O cluster de banco de dados da réplica é criado de um snapshot da instância do banco de dados de origem usando o mesmo nome de usuário e senha “primários” como a origem, portanto, não é possível alterá-los no momento.
Opção Descrição Classe da instância de banco de dados
Escolha uma classe de instância de banco de dados que atenda aos requisitos de processamento e memória da instância principal no cluster de banco de dados. Para ter mais informações, consulte Classes de instâncias de banco de dados do Amazon Aurora.
implantação Multi-AZ
Não disponível durante a migração
Identificador de instância de banco de dados
Insira o nome que você deseja dar à instância de banco de dados. Esse identificador é usado no endereço do endpoint da instância principal do novo cluster de banco de dados.
O DB instance identifier tem as seguintes restrições:
-
Deve conter de 1 a 63 caracteres alfanuméricos ou hifens.
-
O primeiro caractere deve ser uma letra.
-
Não pode terminar com um hífen ou conter dois hífens consecutivos.
-
Deve ser exclusivo para todas as instâncias de banco de dados para cada conta da AWS por Região da AWS.
Virtual Private Cloud (VPC)
Escolha a VPC que hospeda o cluster de banco de dados. Escolha Create new VPC (Criar nova VPC) para fazer o Amazon RDS criar uma VPC para você. Para ter mais informações, consulte Pré-requisitos do cluster de banco de dados.
DB subnet group (Grupo de subredes do banco de dados
Selecione o grupo de sub-redes de banco de dados a ser usado para o cluster de banco de dados. Escolha Create new DB Subnet Group (Criar novo grupo de sub-redes de banco de dados) para fazer o Amazon RDS criar um grupo de sub-redes de banco de dados para você. Para ter mais informações, consulte Pré-requisitos do cluster de banco de dados.
Public accessibility
Selecione Yes (Sim) para dar um endereço IP público ao cluster de banco de dados; senão, selecione No (Não). As instâncias em seu cluster de banco de dados podem ser uma combinação de instâncias de banco de dados públicas e privadas. Para ter mais informações sobre como ocultar instâncias do acesso público, consulte Ocultar um cluster de banco de dados em uma VPC da Internet.
Availability zone
Determine se você deseja especificar uma Zona de disponibilidade específica. Para ter mais informações sobre zonas de disponibilidade, consulte Regiões e zonas de disponibilidade.
Grupos de segurança da VPC
Selecione um ou mais grupos de segurança da VPC para proteger o acesso à rede para o cluster de banco de dados. Escolha Create new VPC security group (Criar novo grupo de segurança da VPC) para fazer o Amazon RDS criar um grupo de segurança da VPC para você. Para ter mais informações, consulte Pré-requisitos do cluster de banco de dados.
Database port
Especifique a porta que os aplicativos e os utilitários usam para acessar o banco de dados. Os clusters de banco de dados PostgreSQL do Aurora assumem como padrão a porta PostgreSQL 5432. Em algumas empresas, os firewalls bloqueiam conexões a esta porta. Se o firewall da sua empresa bloquear a porta padrão, escolha outra porta para o novo cluster de banco de dados.
Grupo de parâmetros de banco de dados
Escolha um grupo de parâmetros de banco de dados para o cluster de bancos de dados Aurora PostgreSQL. O Aurora conta com um grupo de parâmetros de banco de dados padrão que você pode usar, ou é possível criar seu próprio grupo de parâmetros de banco de dados. Para ter mais informações sobre os parameter groups de banco de dados, consulte Grupos de parâmetros para Amazon Aurora.
Grupo de parâmetros do cluster de banco de dados
Escolha um grupo de parâmetros de cluster de banco de dados para o cluster de bancos de dados Aurora PostgreSQL. O Aurora conta com um grupo de parâmetros de cluster de banco de dados que você pode usar, ou é possível criar seu próprio grupo de parâmetros. Para ter mais informações sobre os parameter groups do cluster de banco de dados, consulte Grupos de parâmetros para Amazon Aurora.
Criptografia
Escolha Enable encryption para que o novo cluster de banco de dados Aurora seja criptografado em repouso. Se você selecionar Enable encryption (Habilitar criptografia), escolha também uma chave do KMS como o valor de AWS KMS key.
Priority
Escolha uma prioridade de failover para o cluster de banco de dados. Se você não selecionar um valor, o padrão será tier-1. Essa prioridade determina a ordem em que as réplicas do Aurora são promovidas durante a recuperação de uma falha de instância primária. Para ter mais informações, consulte Tolerância a falhas para um cluster de banco de dados do Aurora.
Backup retention period (Período de retenção de backup
Selecione o tempo, de 1 a 35 dias, para o Aurora reter cópias de backup do banco de dados. As cópias de backup podem ser usadas para restaurações point-in-time (PITR) do banco de dados, contabilizando até os segundos.
Enhanced monitoring
Escolha Enable enhanced monitoring (Habilitar monitoramento avançado) para habilitar a coleta de métricas em tempo real do sistema operacional em que o cluster de banco de dados é executado. Para ter mais informações, consulte Monitorar métricas do SO com o monitoramento avançado.
Monitoring Role (Monitoramento de perfis
Disponível apenas se você tiver escolhido Enable enhanced monitoring (Habilitar monitoramento avançado). A função do AWS Identity and Access Management (IAM) a ser usada para monitoramento avançado. Para ter mais informações, consulte Configurar e habilitar o monitoramento avançado.
Granularity
Disponível apenas se você tiver escolhido Enable enhanced monitoring (Habilitar monitoramento avançado). Defina o intervalo, em segundos, em que as métricas são coletadas para o seu cluster de banco de dados.
Atualização da versão secundária automática
Selecione Yes (Sim) para permitir que o cluster de bancos de dados Aurora PostgreSQL receba atualizações de versões secundárias do mecanismo de banco de dados PostgreSQL automaticamente quando forem disponibilizadas.
A opção Auto minor version upgrade (Atualização da versão secundária automática) aplica-se apenas a atualizações de versões secundárias de mecanismos PostgreSQL do seu cluster de bancos de dados Aurora PostgreSQL. Ela não se aplica a patches regulares aplicados para manter a estabilidade do sistema.
Janela de manutenção
Escolha o intervalo de tempo semanal durante o qual pode ocorrer a manutenção do sistema.
-
-
Escolha Create read replica (Criar réplica de leitura).
Para criar uma réplica de leitura do Aurora a partir de uma instância de banco de dados do RDS for PostgreSQL de origem usando a AWS CLI, use primeiro o comando da CLI create-db-cluster para criar um cluster de banco de dados do Aurora PostgreSQL. Assim que houver um cluster de banco de dados, você usará o comando create-db-instance para criar a instância principal para seu cluster de banco de dados. A instância principal é a primeira instância criada em um cluster de banco de dados do Aurora. Nesse caso, ele é criado inicialmente como uma réplica de leitura do Aurora da instância de banco de dados do RDS for PostgreSQL. Quando o processo for concluído, sua instância de banco de dados do RDS for PostgreSQL terá sido efetivamente migrada para um cluster de banco de dados do Aurora PostgreSQL.
Não é necessário especificar a conta de usuário principal (normalmente, postgres), sua senha nem o nome do banco de dados. A réplica de leitura do Aurora obtém essas informações automaticamente da instância de banco de dados do RDS for PostgreSQL de origem identificada quando você chama os comandos da AWS CLI.
Você precisa especificar a versão do mecanismo a ser usada para o cluster de banco de dados do Aurora PostgreSQL e para a instância de banco de dados. A versão especificada deve corresponder à instância de banco de dados do RDS for PostgreSQL de origem. Se a instância de banco de dados do RDS for PostgreSQL de origem estiver criptografada, você também precisará especificar a criptografia da instância principal do cluster de banco de dados do Aurora PostgreSQL. A migração de uma instância criptografada para um cluster de banco de dados não criptografado do Aurora não é compatível.
Os exemplos a seguir criam um cluster de banco de dados do Aurora PostgreSQL chamado my-new-aurora-cluster que usará uma instância de origem de banco de dados do RDS não criptografada. Primeiro, você cria o cluster de banco de dados do Aurora PostgreSQL chamando o comando create-db-cluster da CLI. O exemplo mostra como usar o parâmetro --storage-encrypted opcional para especificar se o cluster de banco de dados deve ser criptografado. Como o banco de dados de origem não está criptografado, o --kms-key-id é usado para especificar a chave a ser usada. Para ter mais informações sobre parâmetros obrigatórios e opcionais, consulte a lista após o exemplo.
Para Linux, macOS ou Unix:
aws rds create-db-cluster \ --db-cluster-identifiermy-new-aurora-cluster\ --db-subnet-group-namemy-db-subnet--vpc-security-group-idssg-11111111--engine aurora-postgresql \ --engine-versionsame-as-your-rds-instance-version\ --replication-source-identifier arn:aws:rds:aws-region:111122223333:db/rpg-source-db\ --storage-encrypted \ --kms-key-id arn:aws:kms:aws-region:111122223333:key/11111111-2222-3333-444444444444
Para Windows:
aws rds create-db-cluster ^ --db-cluster-identifiermy-new-aurora-cluster^ --db-subnet-group-namemy-db-subnet^ --vpc-security-group-idssg-11111111^ --engine aurora-postgresql ^ --engine-versionsame-as-your-rds-instance-version^ --replication-source-identifier arn:aws:rds:aws-region:111122223333:db/rpg-source-db^ --storage-encrypted ^ --kms-key-id arn:aws:kms:aws-region:111122223333:key/11111111-2222-3333-444444444444
Na lista a seguir, você pode encontrar mais informações sobre algumas das opções mostradas no exemplo. A menos que especificado de outra forma, esses parâmetros são obrigatórios.
-
--db-cluster-identifier: você precisa fornecer um nome ao novo cluster de banco de dados do Aurora PostgreSQL. -
--db-subnet-group-name: crie seu cluster de banco de dados do Aurora PostgreSQL na mesma sub-rede de banco de dados que a instância de banco de dados de origem. -
--vpc-security-group-ids: especifique o grupo de segurança do cluster de banco de dados do Aurora PostgreSQL. -
--engine-version: especifique a versão a ser usada para o cluster de banco de dados do Aurora PostgreSQL. Deve ser o mesmo da versão usada ou uma versão inferior maior que a versão usada pela instância de banco de dados do RDS for PostgreSQL de origem. -
--replication-source-identifier: identifique sua instância de banco de dados do RDS for PostgreSQL usando seu nome de recurso da Amazon (ARN). Para ter mais informações sobre ARNs do Amazon RDS, consulte Amazon Relational Database Service (Amazon RDS) na Referência geral da AWS de seu cluster de banco de dados. -
--storage-encrypted: opcional. Use somente quando necessário para especificar a criptografia da seguinte forma:Use esse parâmetro quando a instância de banco de dados de origem tiver armazenamento criptografado. A chamada para
create-db-clusterfalhará se você não usar esse parâmetro com uma instância de banco de dados de origem que tenha armazenamento criptografado. Se você quiser usar uma chave para o cluster de banco de dados do Aurora PostgreSQL diferente da chave usada pela instância de banco de dados de origem, especifique também o--kms-key-id.Use se o armazenamento da instância de banco de dados de origem não estiver criptografado, mas você quiser que o cluster de banco de dados do Aurora PostgreSQL use criptografia. Em caso afirmativo, você também precisará identificar a chave de criptografia a ser usada com o parâmetro
--kms-key-id.
-
--kms-key-id: opcional. Quando usado, você pode especificar a chave a ser usada para criptografia de armazenamento (--storage-encrypted) usando o ARN da chave, o ID, o ARN do alias ou seu nome de alias. Esse parâmetro é necessário somente nas seguintes situações:-
Para escolher uma chave para o cluster de banco de dados do Aurora PostgreSQL diferente da usada pela instância de banco de dados de origem.
Para criar um cluster criptografado em uma fonte não criptografada. Nesse caso, você precisa especificar a chave que o Aurora PostgreSQL deve usar para criptografia.
-
Depois de criar o cluster de banco de dados do Aurora PostgreSQL, crie a instância principal usando o comando create-db-instance da CLI, conforme mostrado a seguir:
Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-cluster-identifiermy-new-aurora-cluster\ --db-instance-classdb.x2g.16xlarge\ --db-instance-identifierrpg-for-migration\ --engine aurora-postgresql
Para Windows:
aws rds create-db-instance ^ --db-cluster-identifiermy-new-aurora-cluster^ --db-instance-classdb.x2g.16xlarge^ --db-instance-identifierrpg-for-migration^ --engine aurora-postgresql
Na lista a seguir, você pode encontrar mais informações sobre algumas das opções mostradas no exemplo.
-
--db-cluster-identifier: especifique o nome do cluster de banco de dados do Aurora PostgreSQL que você criou com o comandocreate-db-instancena etapa anterior. -
--db-instance-class: o nome da classe da instância de banco de dados a ser usada para sua instância principal, comodb.r4.xlarge,db.t4g.medium,db.x2g.16xlargeetc. Para obter uma lista das classes de instância de banco de dados, consulte Tipos de classe de instância de banco de dados. -
--db-instance-identifier: especifique o nome para fornecer à instância principal. -
--engine aurora-postgresql: especifiqueaurora-postgresqlpara o mecanismo.
Para criar uma réplica de leitura do Aurora a partir de uma instância de banco de dados do RDS for PostgreSQL de origem, primeiro use a operação da API do RDS CreateDBCluster para criar um cluster de banco de dados do Aurora para a réplica de leitura do Aurora criada a partir da instância de banco de dados do RDS for PostgreSQL de origem. Quando o cluster de banco de dados do Aurora PostgreSQL estiver disponível, você use CreateDBInstance para criar a instância principal para o cluster de banco de dados do Aurora.
Não é necessário especificar a conta de usuário principal (normalmente, postgres), sua senha nem o nome do banco de dados. A réplica de leitura do Aurora obtém essas informações automaticamente da instância de banco de dados do RDS for PostgreSQL especificada com o ReplicationSourceIdentifier.
Você precisa especificar a versão do mecanismo a ser usada para o cluster de banco de dados do Aurora PostgreSQL e para a instância de banco de dados. A versão especificada deve corresponder à instância de banco de dados do RDS for PostgreSQL de origem. Se a instância de banco de dados do RDS for PostgreSQL de origem estiver criptografada, você também precisará especificar a criptografia da instância principal do cluster de banco de dados do Aurora PostgreSQL. A migração de uma instância criptografada para um cluster de banco de dados não criptografado do Aurora não é compatível.
Para criar o cluster de banco de dados do Aurora para a réplica de leitura do Aurora, use a operação da API do RDS CreateDBCluster com os seguintes parâmetros:
-
DBClusterIdentifier: o nome do cluster de banco de dados a ser criado. -
DBSubnetGroupName: o nome do grupo de sub-redes de banco de dados a ser associado a esse cluster de banco de dados. -
Engine=aurora-postgresql: o nome do mecanismo a ser usado. -
ReplicationSourceIdentifier: o nome de recurso da Amazon (ARN) para a instância de banco de dados do PostgreSQL de origem. Para ter mais informações sobre ARNs do Amazon RDS, consulte Amazon Relational Database Service (Amazon RDS) no Referência geral da Amazon Web Services. Se oReplicationSourceIdentifieridentificar uma fonte criptografada, o Amazon RDS usará sua chave do KMS padrão, a menos que você especifique uma chave diferente com o uso da opçãoKmsKeyId. -
VpcSecurityGroupIds: a lista de grupos de segurança da VPC do Amazon EC2 a ser associada a esse cluster de banco de dados. -
StorageEncrypted: indica se o cluster de banco de dados é criptografado. Quando você usa esse parâmetro sem especificar também oReplicationSourceIdentifier, o Amazon RDS usa sua chave padrão do KMS. -
KmsKeyId: a chave para um cluster criptografado. Quando usado, você pode especificar a chave a ser usada para criptografia de armazenamento usando o ARN da chave, o ID, o ARN do alias ou seu nome de alias.
Para ter mais informações, consulte CreateDBCluster na Referência de API do Amazon RDS.
Depois que o cluster de banco de dados do Aurora estiver disponível, você poderá criar uma instância principal para ele usando a operação CreateDBInstance da API do RDS com os seguintes parâmetros:
-
DBClusterIdentifier: o nome de seu cluster de banco de dados. -
DBInstanceClass: o nome da classe de instância de banco de dados a ser usada para sua instância principal. -
DBInstanceIdentifier: o nome da sua instância principal. -
Engine=aurora-postgresql: o nome do mecanismo a ser usado.
Para ter mais informações, consulte CreateDBInstance na Referência de API do Amazon RDS.
Promover uma réplica de leitura do Aurora
A migração para o Aurora PostgreSQL não estará concluída até que você promova o cluster de réplica, portanto, não exclua a instância de banco de dados de origem do RDS for PostgreSQL ainda.
Antes de promover o cluster de réplica, certifique-se de que a instância de banco de dados do RDS for PostgreSQL não tenha nenhuma transação em processamento ou outra atividade de gravação no banco de dados. Quando o atraso da réplica na réplica de leitura do Aurora alcança 0 (zero), você pode promover o cluster de réplica. Para ter mais informações sobre o monitoramento do atraso da réplica, consulte Monitorar a replicação do Aurora PostgreSQL e Métricas no nível da instância do Amazon Aurora.
Como promover uma réplica de leitura do Aurora a um cluster de bancos de dados Aurora
-
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Bancos de dados.
-
Escolha o cluster de réplica.
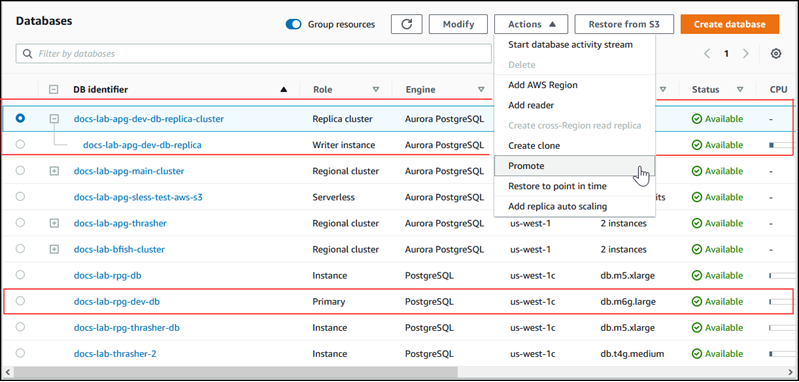
-
Em Actions (Ações), selecione Promote (Promover). Isso pode levar alguns minutos e pode levar a um tempo de inatividade.
Quando o processo é concluído, o cluster de réplica do Aurora é um cluster de banco de dados Aurora PostgreSQL regional, com uma instância do gravador contendo os dados da instância de banco de dados do RDS for PostgreSQL.
Para promover uma réplica de leitura do Aurora a um cluster de banco de dados autônomo, use o comando promote-read-replica-db-cluster da AWS CLI.
exemplo
Para Linux, macOS ou Unix:
aws rds promote-read-replica-db-cluster \ --db-cluster-identifiermyreadreplicacluster
Para Windows:
aws rds promote-read-replica-db-cluster ^ --db-cluster-identifiermyreadreplicacluster
Para promover uma réplica de leitura Aurora para um cluster de banco de dados autônomo, use a operação de API do RDS PromoteReadReplicaDBCluster.
Depois de promover o cluster de réplica, você pode confirmar se a promoção foi concluída verificando o log de eventos da seguinte forma.
Para confirmar que o cluster de réplica do Aurora foi promovido
Faça login no Console de gerenciamento da AWS e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Events.
-
Na página Events (Eventos), encontre o nome do seu cluster na lista Source (Fonte). Cada evento tem uma fonte, um tipo, um horário e uma mensagem. Você pode ver todos os eventos que ocorreram em sua Região da AWS relacionados à sua conta. Uma promoção bem-sucedida gera a mensagem a seguir.
Promoted Read Replica cluster to a stand-alone database cluster.
Depois que promoção estiver concluída, a instância de banco de dados do RDS for PostgreSQL de origem e o cluster de banco de dados Aurora PostgreSQL serão desvinculadas. Você pode direcionar suas aplicações cliente para o endpoint da réplica de leitura do Aurora. Para ter mais informações sobre os endpoints do Aurora, consulte Conexões de endpoints do Amazon Aurora. Neste ponto, você poderá excluir com segurança a instância de banco de dados.
