AWS CLIExemplos da para o Performance Insights
Nas seções a seguir, saiba mais sobre a AWS Command Line Interface (AWS CLI) para o Insights de Performance e use exemplos da AWS CLI.
Tópicos
Recuperar a média de carga de banco de dados para eventos de espera superior
Recuperar a média de carga de banco de dados para SQL principal
Recuperação da média de carga de banco de dados filtrada por SQL
Criar um relatório de análise de performance para um período
Listar todos os relatórios de análise de performance da instância de banco de dados
Listar todas as tags para um relatório de análise de performance
Ajuda integrada da AWS CLI para o Insights de Performance
É possível visualizar dados do Performance Insights usando o AWS CLI. É possível visualizar a ajuda dos comandos da AWS CLI para o Performance Insights, inserindo o seguinte na linha de comando.
aws pi help
Se você não tiver a AWS CLI instalada, consulte informações sobre a instalação em Instalar a AWS CLI no Guia do usuário da AWS CLI.
Recuperar métricas de contador
A captura de tela a seguir mostra dois gráficos de métricas de contador no Console de gerenciamento da AWS.
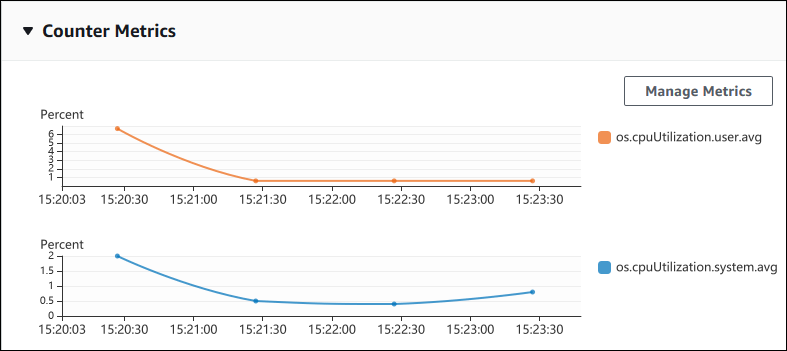
O exemplo a seguir mostra como reunir os mesmos dados que o Console de gerenciamento da AWS usa para gerar os dois gráficos de métricas de contador.
Para Linux, macOS ou Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Você também pode tornar um comando mais fácil de ler, especificando um arquivo para a opção --metrics-query. O exemplo a seguir usa um arquivo chamado query.json para a opção. O arquivo tem o seguinte conteúdo.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
Execute o seguinte comando para usar o arquivo.
Para Linux, macOS ou Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
O exemplo anterior especifica os seguintes valores para as opções:
-
--service-type:RDSpara Amazon RDS -
--identifier– O ID do recurso para a instância do banco de dados -
--start-timee--end-time– Os valores ISO 8601 deDateTimepara o período a consultar, com vários formatos compatíveis
Ele consulta um intervalo de tempo de uma hora:
-
--period-in-seconds–60para uma consulta por minuto -
--metric-queries– uma matriz de duas consultas, cada uma apenas para uma métrica.O nome da métrica usa pontos para classificar a métrica em uma categoria útil, com o elemento final sendo uma função. No exemplo, a função é
avgpara cada consulta. Como no Amazon CloudWatch, as funções com suporte sãomin,max,totaleavg.
A resposta é semelhante à seguinte.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { "Metric": "os.cpuUtilization.user.avg" //Metric1 }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 4.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 4.0 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 10.0 } //... 60 datapoints for the os.cpuUtilization.user.avg metric ] }, { "Key": { "Metric": "os.cpuUtilization.idle.avg" //Metric2 }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 12.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 13.5 }, //... 60 datapoints for the os.cpuUtilization.idle.avg metric ] } ] //end of MetricList } //end of response
A resposta tem Identifier, AlignedStartTime e AlignedEndTime. Se o valor de --period-in-seconds fosse 60, as horas de início e término seriam alinhadas ao minuto. Se --period-in-seconds fosse 3600, as horas de início e término teriam sido alinhadas à hora.
O MetricList na resposta tem um número de entradas, cada uma com uma entrada Key e DataPoints. Cada DataPoint tem um Timestamp e um Value. Cada lista Datapoints tem 60 pontos de dados, pois as consultas são para dados por minuto ao longo de uma hora, com Timestamp1/Minute1, Timestamp2/Minute2 e assim por diante, até Timestamp60/Minute60.
Como a consulta é para duas métricas de contador diferentes, há dois elementos na resposta MetricList.
Recuperar a média de carga de banco de dados para eventos de espera superior
O exemplo a seguir é a mesma consulta que o Console de gerenciamento da AWS usa para gerar um gráfico de linha de área empilhada. Este exemplo recupera o db.load.avg para a última hora com carga dividida de acordo com os sete principais eventos de espera. O comando é o mesmo que o comando em Recuperar métricas de contador. No entanto, o arquivo query.json tem o seguinte conteúdo.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 7 } } ]
Execute o comando a seguir.
Para Linux, macOS ou Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
O exemplo especifica a métrica de db.load.avg e um GroupBy dos sete principais eventos de espera. Para obter detalhes sobre valores válidos para esse exemplo, consulte DimensionGroup na Referência de API do Performance Insights.
A resposta é semelhante à seguinte.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 0.5166666666666667 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.38333333333333336 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 0.26666666666666666 } //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_event.name": "CPU", "db.wait_event.type": "CPU" } }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 0.35 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.15 }, //... 60 datapoints for the CPU key ] }, //... In total we have 8 key/datapoints entries, 1) total, 2-8) Top Wait Events ] //end of MetricList } //end of response
Nessa resposta, há oito entradas no MetricList. Há uma entrada para o total db.load.avg, e sete entradas cada para o db.load.avg, divididas de acordo com um dos sete principais eventos de espera. Ao contrário do primeiro exemplo, como havia uma dimensão de agrupamento, deve haver uma chave para cada agrupamento da métrica. Não pode haver apenas uma chave para cada métrica, como no caso de uso de métricas de contador.
Recuperar a média de carga de banco de dados para SQL principal
O exemplo a seguir agrupa db.wait_events pelas 10 principais instruções SQL. Existem dois grupos diferentes para instruções SQL:
-
db.sql– a instrução SQL completa, comoselect * from customers where customer_id = 123 -
db.sql_tokenized– a instrução SQL tokenizada, comoselect * from customers where customer_id = ?
Ao analisar a performance do banco de dados, pode ser útil considerar instruções SQL que diferem apenas por seus parâmetros como um item lógico. Então, você pode usar db.sql_tokenized ao consultar. No entanto, especialmente quando você está interessado em explicar planos, às vezes é mais útil examinar instruções SQL completas com parâmetros e agrupamentos de consulta por db.sql. Existe um relacionamento pai-filho entre o SQL tokenizado e o SQL completo, com vários SQL completos (filhos) agrupados sob o mesmo SQL (pai) tokenizado.
O comando neste exemplo é semelhante ao comando em Recuperar a média de carga de banco de dados para eventos de espera superior. No entanto, o arquivo query.json tem o seguinte conteúdo.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Limit": 10 } } ]
O exemplo a seguir usa db.sql_tokenized.
Para Linux, macOS ou Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-29T00:00:00Z\ --end-time2018-10-30T00:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-29T00:00:00Z^ --end-time2018-10-30T00:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
Este exemplo consulta mais de 24 horas, com um período de uma hora em segundos.
O exemplo especifica a métrica de db.load.avg e um GroupBy dos sete principais eventos de espera. Para obter detalhes sobre valores válidos para esse exemplo, consulte DimensionGroup na Referência de API do Performance Insights.
A resposta é semelhante à seguinte.
{ "AlignedStartTime": 1540771200.0, "AlignedEndTime": 1540857600.0, "Identifier": "db-XXX", "MetricList": [ //11 entries in the MetricList { "Key": { //First key is total "Metric": "db.load.avg" } "DataPoints": [ //Each DataPoints list has 24 per-hour Timestamps and a value { "Value": 1.6964980544747081, "Timestamp": 1540774800.0 }, //... 24 datapoints ] }, { "Key": { //Next key is the top tokenized SQL "Dimensions": { "db.sql_tokenized.statement": "INSERT INTO authors (id,name,email) VALUES\n( nextval(?) ,?,?)", "db.sql_tokenized.db_id": "pi-2372568224", "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }, "Metric": "db.load.avg" }, "DataPoints": [ //... 24 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized SQL, 1 total key ] //End of MetricList } //End of response
Essa resposta tem 11 entradas no MetricList (1 total, 10 principais SQLs tokenizados), com cada entrada com 24 DataPoints por hora.
Para o SQL tokenizado, existem três entradas em cada lista de dimensões:
-
db.sql_tokenized.statement– a instrução SQL tokenizada. -
db.sql_tokenized.db_id– o ID do banco de dados nativo usado para referência ao SQL ou um ID sintético que o Performance Insights gera para você quando o ID do banco de dados nativo não está disponível. Este exemplo retorna o ID sintéticopi-2372568224. -
db.sql_tokenized.id– o ID da consulta dentro do Performance Insights.No Console de gerenciamento da AWS, esse ID é chamado de ID de suporte. Ele é chamado assim porque o ID consiste em dados que o AWS Support pode examinar para ajudar você a solucionar um problema no banco de dados. A AWS leva a segurança e privacidade de seus dados extremamente a sério, e quase todos os dados são armazenados criptografados com a chave do AWS KMS. Portanto, ninguém dentro da AWS pode examinar esses dados. No exemplo precedente,
tokenized.statementetokenized.db_idsão armazenados em formato criptografado. Se você tiver um problema com o banco de dados, o Suporte da AWS poderá ajudar você consultando o ID de suporte.
Ao consultar, pode ser conveniente especificar Group em GroupBy. No entanto, para um controle mais refinado sobre os dados retornados, especifique a lista de dimensões. Por exemplo, se tudo o que for necessário for o db.sql_tokenized.statement, um atributo Dimensions poderá ser adicionado ao arquivo query.json.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Dimensions":["db.sql_tokenized.statement"], "Limit": 10 } } ]
Recuperação da média de carga de banco de dados filtrada por SQL
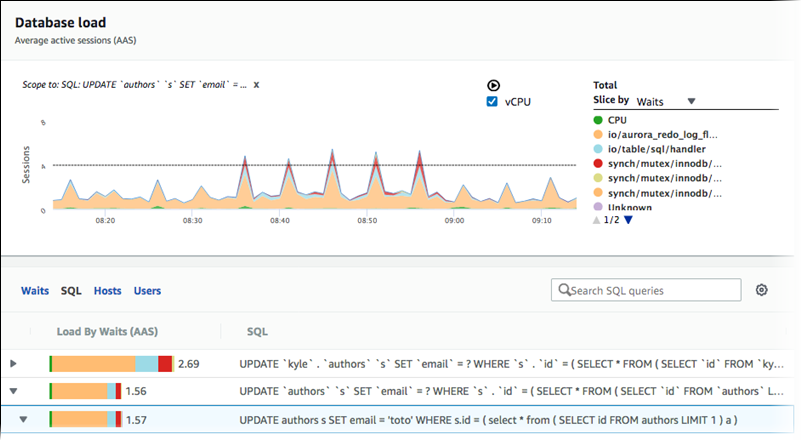
A imagem anterior mostra que uma consulta específica está selecionada e que o gráfico de linhas da área empilhada das sessões ativas da média superior tem o escopo para essa consulta. Embora a consulta ainda seja para os sete principais eventos de espera geral, o valor da resposta é filtrado. O filtro faz com que ele leve em consideração apenas as sessões correspondentes ao filtro específico.
A consulta da API correspondente neste exemplo é semelhante ao comando em Recuperar a média de carga de banco de dados para SQL principal. No entanto, o arquivo query.json tem o seguinte conteúdo.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 5 }, "Filter": { "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
Para Linux, macOS ou Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Para Windows:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
A resposta é semelhante à seguinte.
{ "Identifier": "db-XXX", "AlignedStartTime": 1556215200.0, "MetricList": [ { "Key": { "Metric": "db.load.avg" }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.4878117913832196 }, { "Timestamp": 1556222400.0, "Value": 1.192823803967328 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/aurora_redo_log_flush" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.1360544217687074 }, { "Timestamp": 1556222400.0, "Value": 1.058051341890315 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/table/sql/handler" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.16241496598639457 }, { "Timestamp": 1556222400.0, "Value": 0.05163360560093349 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/aurora_lock_thread_slot_futex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.11479591836734694 }, { "Timestamp": 1556222400.0, "Value": 0.013127187864644107 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "CPU", "db.wait_event.name": "CPU" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.05215419501133787 }, { "Timestamp": 1556222400.0, "Value": 0.05805134189031505 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/lock_wait_mutex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.017573696145124718 }, { "Timestamp": 1556222400.0, "Value": 0.002333722287047841 } ] } ], "AlignedEndTime": 1556222400.0 } //end of response
Nessa resposta, todos os valores são filtrados de acordo com a contribuição de SQL tokenizado AKIAIOSFODNN7EXAMPLE especificado no arquivo query.json. As chaves também podem seguir uma ordem diferente de uma consulta sem um filtro, porque são os cinco principais eventos de espera que afetaram o SQL filtrado.
Recuperar o texto completo de uma instrução SQL
O exemplo a seguir recupera o texto completo de uma instrução SQL para a instância de banco de dados db-10BCD2EFGHIJ3KL4M5NO6PQRS5. O --group é db.sql, e o --group-identifier é db.sql.id. Nesse exemplo, my-sql-id representa um ID SQL recuperado que invoca pi
get-resource-metrics ou pi describe-dimension-keys.
Execute o comando a seguir.
Para Linux, macOS ou Unix:
aws pi get-dimension-key-details \ --service-type RDS \ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 \ --group db.sql \ --group-identifiermy-sql-id\ --requested-dimensions statement
Para Windows:
aws pi get-dimension-key-details ^ --service-type RDS ^ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 ^ --group db.sql ^ --group-identifiermy-sql-id^ --requested-dimensions statement
Nesse exemplo, os detalhes das dimensões estão disponíveis. Assim, o Performance Insights recupera o texto completo da instrução SQL, sem truncá-lo.
{ "Dimensions":[ { "Value": "SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id", "Dimension": "db.sql.statement", "Status": "AVAILABLE" }, ... ] }
Criar um relatório de análise de performance para um período
O exemplo a seguir cria um relatório de análise de performance com o horário de início 1682969503 e o horário de término 1682979503 do banco de dados db-loadtest-0.
aws pi create-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --start-time 1682969503 \ --end-time 1682979503 \ --region us-west-2
A resposta é o identificador exclusivo report-0234d3ed98e28fb17 do relatório.
{ "AnalysisReportId": "report-0234d3ed98e28fb17" }
Recuperar um relatório de análise de performance
O exemplo a seguir recupera os detalhes do relatório de análise do relatório report-0d99cc91c4422ee61.
aws pi get-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
A resposta fornece o status, o ID, os detalhes do horário e os insights do relatório.
{ "AnalysisReport": { "Status": "Succeeded", "ServiceType": "RDS", "Identifier": "db-loadtest-0", "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61", "EndTime": 1680587086.584, "CreateTime": 1680587087.139, "Insights": [ ... (Condensed for space) ] } }
Listar todos os relatórios de análise de performance da instância de banco de dados
O exemplo a seguir lista todos os relatórios de análise de performance disponíveis para o banco de dados db-loadtest-0.
aws pi list-performance-analysis-reports \ --service-type RDS \ --identifier db-loadtest-0 \ --region us-west-2
A resposta lista todos os relatórios com o ID do relatório, o status e os detalhes do período.
{ "AnalysisReports": [ { "Status": "Succeeded", "EndTime": 1680587086.584, "CreationTime": 1680587087.139, "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61" }, { "Status": "Succeeded", "EndTime": 1681491137.914, "CreationTime": 1681491145.973, "StartTime": 1681487537.914, "AnalysisReportId": "report-002633115cc002233" }, { "Status": "Succeeded", "EndTime": 1681493499.849, "CreationTime": 1681493507.762, "StartTime": 1681489899.849, "AnalysisReportId": "report-043b1e006b47246f9" }, { "Status": "InProgress", "EndTime": 1682979503.0, "CreationTime": 1682979618.994, "StartTime": 1682969503.0, "AnalysisReportId": "report-01ad15f9b88bcbd56" } ] }
Excluir um relatório de análise de performance
O exemplo a seguir exclui o relatório de análise do banco de dados db-loadtest-0.
aws pi delete-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
Adicionar tags a um relatório de análise de performance
O exemplo a seguir adiciona uma tag com uma chave name e um valor test-tag ao relatório report-01ad15f9b88bcbd56.
aws pi tag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tags Key=name,Value=test-tag \ --region us-west-2
Listar todas as tags para um relatório de análise de performance
O exemplo a seguir lista todas as tags do relatório report-01ad15f9b88bcbd56.
aws pi list-tags-for-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --region us-west-2
A resposta lista o valor e a chave de todas as tags adicionadas ao relatório:
{ "Tags": [ { "Value": "test-tag", "Key": "name" } ] }
Excluir tags de um relatório de análise de performance
O exemplo a seguir exclui a tag name do relatório report-01ad15f9b88bcbd56.
aws pi untag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tag-keys name \ --region us-west-2
Depois que a tag for excluída, chamar a API list-tags-for-resource não listará essa tag.
