io/aurora_redo_log_flush
O evento io/aurora_redo_log_flush ocorre quando uma sessão está gravando dados persistentes no armazenamento do Amazon Aurora.
Versões compatíveis do mecanismo
Essas informações de eventos de espera têm suporte nas seguintes versões do mecanismo:
-
Aurora MySQL versão 2
Contexto
O evento io/aurora_redo_log_flush refere-se a uma operação de entrada/saída (E/S) no Aurora MySQL.
nota
No Aurora MySQL versão 3, esse evento de espera é denominado io/redo_log_flush.
Possíveis causas do maior número de esperas
Para persistência de dados, as confirmações exigem uma gravação durável no armazenamento estável. Se o banco de dados estiver fazendo muitas confirmações, significa que há um evento de espera na operação de E/S de gravação, o evento de espera io/aurora_redo_log_flush.
Nos exemplos a seguir, 50.000 registros são inseridos em um cluster de banco de dados Aurora MySQL com a classe de instância de banco de dados db.r5.xlarge:
-
No primeiro exemplo, cada sessão insere 10.000 registros, linha por linha. Por padrão, se um comando de linguagem de manipulação de dados (DML) não estiver em uma transação, o Aurora MySQL utilizará confirmações implícitas. A confirmação automática está habilitada. Isso significa que há uma confirmação para cada inserção de linha. O Performance Insights mostra que as conexões passam a maior parte do tempo esperando pelo evento de espera
io/aurora_redo_log_flush.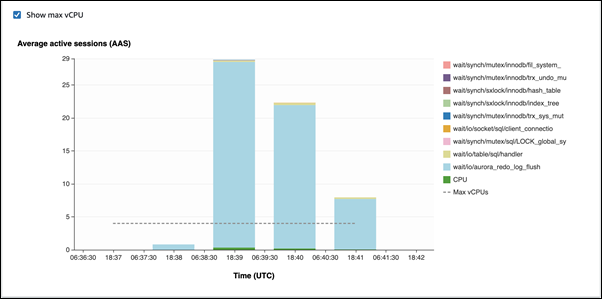
Isso é causado pelas instruções de inserção simples utilizadas.
Os 50.000 registros demoram 3,5 minutos para serem inseridos.
-
No segundo exemplo, as inserções são feitas em 1.000 lotes, ou seja, cada conexão realiza 10 confirmações em vez de 10.000. O Performance Insights mostra que as conexões não passam a maior parte do tempo no evento de espera
io/aurora_redo_log_flush.
Os 50.000 registros demoram 4 segundos para serem inseridos.
Ações
Recomenda-se ações distintas, dependendo dos motivos do evento de espera.
Identificar as sessões e consultas problemáticas
Se a sua instância de banco de dados estiver enfrentando um gargalo, a primeira tarefa é encontrar as sessões e consultas responsáveis. Leia esta útil postagem no blog de banco dados da AWS sobre como Analisar workloads do Amazon Aurora MySQL com o Performance Insights
Para identificar sessões e consultas que estão causam um gargalo
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. -
No painel de navegação, escolha Performance Insights.
-
Escolha a instância de banco de dados.
-
Em Database load (Carga de banco de dados), escolha Slice by wait (Segmentar por espera).
-
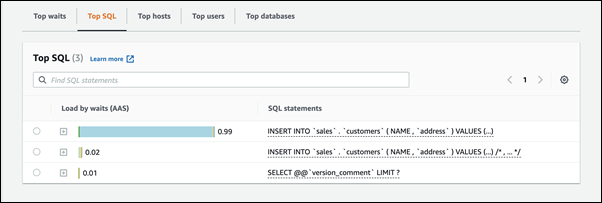
Na parte inferior da página, escolha Top SQL (SQL principal).
As consultas na parte superior da lista estão causando a maior carga no banco de dados.
Agrupar suas operações de gravação
Os exemplos a seguir acionam o evento de espera io/aurora_redo_log_flush. (A confirmação automática está habilitada.)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
Para reduzir o tempo gasto esperando no evento de espera io/aurora_redo_log_flush, agrupe suas operações de gravação logicamente em uma única confirmação para reduzir chamadas persistentes ao armazenamento.
Desativar a confirmação automática
Desative a confirmação automática antes de fazer grandes alterações que não estejam em uma transação, conforme mostrado no exemplo a seguir.
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
Utilizar transações
É possível utilizar transações, conforme mostrado no exemplo a seguir.
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
Utilizar lotes
Você pode fazer alterações em lotes, conforme mostrado no exemplo a seguir. No entanto, o uso de lotes muito grandes pode causar problemas de performance, especialmente em réplicas de leitura ou ao fazer uma recuperação em um ponto anterior no tempo (PITR).
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
