Executar uma prova de conceito com o Amazon Aurora
Veja a explicação a seguir sobre como configurar e executar uma prova de conceito para o Aurora. Uma prova de conceito é uma investigação que você executa para verificar se o Aurora é adequado para seu aplicativo. A prova de conceito pode ajudá-lo a compreender os recursos do Aurora no contexto de seus próprios aplicativos de banco de dados e como o Aurora se compara com seu ambiente de banco de dados atual. Ela também pode mostrar o nível de esforço necessário para mover dados, portar código SQL, ajustar a performance e adaptar seus procedimentos de gerenciamento atuais.
Neste tópico, você pode encontrar uma visão geral e uma descrição detalhada dos procedimentos de alto nível e das decisões envolvidas na execução de uma prova de conceito, que são listados a seguir. Para obter instruções detalhadas, você pode seguir os links para a documentação completa de assuntos específicos.
Visão geral de uma prova de conceito do Aurora
Ao conduzir uma prova de conceito do Amazon Aurora, você aprende o que é necessário para portar seus dados e os aplicativos SQL existentes para o Aurora. Você pratica os aspectos importantes do Aurora em escala, usando um volume de dados e atividades que são representativas para seu ambiente de produção. O objetivo é sentir-se confiante de que os pontos fortes do Aurora coincidem bem com os desafios que fazem com que você aumente excessivamente a infraestrutura de seu banco de dados anterior. No final de uma prova de conceito, você tem um plano sólido para fazer comparações de performance em escala maior e testar aplicativos. Neste ponto, você compreende os itens de trabalho maiores em seu caminho para uma implantação de produção.
O conselho a seguir sobre práticas recomendadas pode ajudar você a evitar erros comuns que provocam problemas durante a comparação. Porém, este tópico não abrange o processo detalhado de como executar comparações e executar o ajuste de performance. Esses procedimentos variam de acordo com a workload e os recursos do Aurora que você usa. Para obter informações detalhadas, consulte a documentação relacionada a performance, como Como gerenciar a performance e a escalabilidade de clusters de banco de dados do Aurora, Melhorias de performance do Amazon Aurora MySQL, Performance e escalabilidade do Amazon Aurora PostgreSQL e Monitorar a carga de banco de dados com o Performance Insights no Amazon Aurora.
As informações deste tópico se aplicam principalmente aos aplicativos em que sua organização grava o código e projeta o esquema e que oferecem suporte aos mecanismos de banco de dados de código aberto do MySQL e do PostgreSQL. Se estiver testando um aplicativo comercial ou código gerado por um framework de aplicação, talvez você não tenha a flexibilidade para aplicar todas as diretrizes. Nesses casos, verifique com o representante da AWS para saber se há práticas recomendadas ou estudos de caso do Aurora para seu tipo de aplicação.
1. Identifique seus objetivos
Ao avaliar o Aurora como parte de uma prova de conceito, você escolhe quais medidas tomar e como avaliar o sucesso do exercício.
Você deve garantir que toda a funcionalidade de seu aplicativo seja compatível com o Aurora. Como as versões primárias do Aurora são compatíveis com as versões principais correspondentes do MySQL e do PostgreSQL, a maioria das aplicações desenvolvidas para esses mecanismos também é compatível com o Aurora. No entanto, você ainda deve validar a compatibilidade com cada aplicativo.
Por exemplo, algumas das opções de configuração que você faz ao configurar um cluster do Aurora definem se você pode ou deve usar determinados recursos do banco de dados. Você pode começar com o tipo de uso mais geral de cluster do Aurora, conhecido como provisionado. Então você pode decidir se uma configuração especializada, como uma consulta sem servidor ou paralela, oferece benefícios para sua workload.
Use as seguintes questões para ajudar a identificar e a quantificar seus objetivos:
-
O Aurora oferece suporte a todos os casos de uso funcionais de sua workload?
-
Qual tamanho de conjunto de dados ou nível de carga você deseja? Você pode dimensionar para esse nível?
-
Quais são seus requisitos específicos de taxa de transferência ou latência de consultas? Você pode atingi-los?
-
Qual á e quantidade mínima aceitável de tempo limite planejado ou não planejado para sua workload? Você pode atingi-la?
-
Quais são as métricas necessárias para a eficiência operacional? Você pode monitorá-las com exatidão?
-
O Aurora oferece suporte a suas metas de negócios específicas, como redução de custos, aumento na implantação ou velocidade de provisionamento? Você tem uma maneira de quantificar essas metas?
-
Você pode atender a todos os requisitos de segurança e conformidade de sua workload?
Dedique algum tempo para conhecer os mecanismos de banco de dados Aurora e as capacidades da plataforma, e revise a documentação do serviço. Anote todos os recursos que podem ajudá-lo a obter os resultados desejados. Um desses recursos pode ser a consolidação de workloads, descrita na publicação do Blog de banco de dados da AWS Como planejar e otimizar o Amazon Aurora com compatibilidade com o MySQL para workloads consolidadas
2. Entenda as características de workloads
Avalie o Aurora no contexto do caso de uso pretendido. O Aurora é uma boa opção para workloads de processamento de transações online (OLTP). Também é possível executar relatórios no cluster que mantém os dado OLTP em tempo real sem provisionar um cluster de data warehouse separado. Você pode reconhecer se seu caso de uso se encaixa nessas categorias verificando as seguintes características:
-
Simultaneidade alta, com dezenas, centenas ou milhares de clientes simultâneos.
-
Grande volume de consultas de latência alta (milissegundos a segundos).
-
Transações curtas em tempo real.
-
Padrões de consulta altamente seletivos, com pesquisas baseadas em índice.
-
Para HTAP, consultas de análise que podem se beneficiar da consulta paralela do Aurora.
Um dos principais fatores que afetam suas opções de banco de dados é a velocidade dos dados. A velocidade alta envolve a inserção e a atualização de dados com muita frequência. Esse sistema pode ter milhares de conexões e centenas de milhares de consultas simultâneas lendo e gravando no banco de dados. As consultas em sistemas de velocidade alta afetam um número relativamente pequeno de linhas e, normalmente, acessam várias colunas na mesma linha.
O Aurora foi desenvolvido para lidar com dados em velocidade alta. Dependendo da workload, um cluster do Aurora com um uma única instância de banco de dados r4.16xlarge pode processar mais de 600.000 instruções SELECT por segundo. Novamente, dependendo da workload, esse cluster pode processar 200.000 instruções INSERT, UPDATE e DELETE por segundo. O Aurora é um banco de dados de armazenamento de linhas e é idealmente adequado para alto volume, alta taxa de transferência e workloads OLTP altamente paralelizadas.
O Aurora também pode executar consultas de relatórios no mesmo cluster que lida com a workload OLTP. O Aurora oferece suporte para até 15 réplicas, estando cada uma, em média, de 10 a 20 milissegundos da instância primária. Os analistas podem consultar dados OLTP em tempo real, sem copiar os dados em um cluster de data warehouse separado. Com os clusters do Aurora usando o recurso de consulta paralela, é possível deslocar muito do trabalho de processamento, filtragem e agregação para o subsistema de armazenamento massivamente distribuído do Aurora.
Use essa fase de planejamento para se familiarizar com os recursos do Aurora, outros produtos da AWS, o Console de gerenciamento da AWS e a AWS CLI. Verifique também como eles funcionam com as outras ferramentas que você planeja usar na prova de conceito.
3. Praticar com o Console de gerenciamento da AWS ou a AWS CLI
Como uma próxima etapa, pratique com o Console de gerenciamento da AWS ou a AWS CLI para familiarizar-se com essas ferramentas e com o Aurora.
Praticar com o Console de gerenciamento da AWS
As seguintes atividades iniciais com clusters de banco de dados do Aurora servem principalmente para você se familiarizar com o ambiente do Console de gerenciamento da AWS e praticar a configuração e a modificação de clusters do Aurora. Se você usa mecanismos de banco de dados compatíveis com o MySQL e com o PostgreSQL com o Amazon RDS, poderá se basear nesse conhecimento ao usar o Aurora.
Aproveitando o modelo e os recursos de armazenamento compartilhado do Aurora, como replicação e snapshots, é possível tratar clusters de banco de dados inteiros como outro tipo de objeto que você manipula livremente. Você pode configurar, descartar e alterar a capacidade dos clusters do Aurora frequentemente durante a prova de conceito. Você não é bloqueado por opções anteriores sobre capacidade, configurações de banco de dados e layout físico de dados.
Para começar a usar, configure um cluster vazio do Aurora. Escolha o tipo de capacidade provisionada e o local regional para seus experimentos iniciais.
Conecte-se a esse cluster usando um programa cliente, como um aplicativo de linha de comando SQL. Inicialmente, você se conecta usando o endpoint do cluster. Você se conecta a esse endpoint para executar qualquer operação de gravação, como instruções de linguagem de definição de dados (DDL - data definition language) e processos de extração, transformação e carregamento (ETL - extract, transform, load). Mais tarde, na prova de conceito, você se conecta a sessões de uso intensivo de consultas usando o endpoint do leitor, que distribui a workload de consulta entre várias instâncias de banco de dados no cluster.
Ampliar o cluster adicionando mais réplicas do Aurora Para esses procedimentos, consulte Replicação com o Amazon Aurora. Amplie ou reduza as instâncias de banco de dados alterando a classe de instância da AWS. Compreenda como o Aurora simplifica esses tipos de operação, de forma que, se suas estimativas iniciais para a capacidade do sistema forem precisas, você possa ajustar posteriormente sem começar de novo.
Crie um snapshot e restaure-o em outro cluster.
Examine as métricas do cluster para verificar as atividades ao longo do tempo, e como as métricas se aplicam às instâncias de banco de dados no cluster.
Familiarizar-se com como fazer essas coisas por meio do Console de gerenciamento da AWS é útil no início. Depois de compreender o que você pode fazer com o Aurora, você pode continuar para a automatização dessas operações usando a AWS CLI. Nas sessões a seguir, você pode encontrar mais detalhes sobre os procedimentos e as práticas recomendadas para essas atividades durante o período de prova de conceito.
Praticar com o AWS CLI
Recomendamos automatizar a implantação e os procedimentos de gerenciamento, mesmo em uma configuração de prova de conceito. Para isso, familiarize-se com a AWS CLI, se ainda não estiver familiarizado. Se você usa mecanismos de banco de dados compatíveis com o MySQL e com o PostgreSQL com o Amazon RDS, poderá se basear nesse conhecimento ao usar o Aurora.
O Aurora normalmente envolve grupos de instâncias de banco de dados organizadas em clusters. Portanto, muitas operações envolvem a determinação de quais instâncias de banco de dados estão associadas a um cluster e a execução de operações administrativas em um loop para todas as instâncias.
Por exemplo, você pode automatizar etapas, como a criação de clusters do Aurora, a ampliação deles com classes de instância maiores ou o aumento deles com instâncias de banco de dados adicionais. Isso ajuda você a repetir qualquer etapa em sua prova de conceito e a explorar cenários hipotéticos com diferentes tipos ou configurações de clusters do Aurora.
Conheça as capacidades e as limitações de ferramentas de implantação de infraestrutura, como o AWS CloudFormation. Você pode descobrir que as atividades que você realiza em uma prova de conceito não são adequadas para uso em produção. Por exemplo, o comportamento do CloudFormation para modificação é criar uma nova instância e excluir a atual, inclusive seus dados. Para obter mais detalhes sobre esse comportamento, consulte Update behaviors of stack resources (Comportamentos de atualização de recursos de pilhas) no Guida do usuário do AWS CloudFormation.
4. Crie seu cluster do Aurora
Com o Aurora, você pode explorar cenários hipotéticos adicionando instâncias de banco de dados ao cluster e ampliando as instâncias de banco de dados para classes de instâncias mais avançadas. Também é possível criar clusters com definições de configuração diferentes para executar a mesma workload lado a lado. Com o Aurora, você tem muita flexibilidade para configurar, descartar e reconfigurar clusters de bancos de dados. Com isso, é útil praticar essas técnicas nas etapas iniciais do processo da prova de conceito. Para obter os procedimentos gerais para criar clusters do Aurora, consulte Criar um cluster de bancos de dados do Amazon Aurora.
Quando prático, inicie com um cluster usando as seguintes configurações. Ignore esta etapa apenas se você tiver certos casos de uso específicos em mente. Por exemplo, você pode ignorar esta etapa se seu caso de uso exigir um tipo especializado de cluster do Aurora. Ou poderá ignorá-la se você precisar de uma combinação específica de mecanismo e versão de banco de dados.
-
Desative a opção Easy create (Criação fácil). Para a prova de conceito, recomendamos que você esteja ciente de todas as configurações escolhidas para que possa criar clusters idênticos ou levemente diferentes mais tarde.
-
Use uma versão de mecanismo de banco de dados recente. Essas combinações de mecanismo e versão de banco de dados têm ampla compatibilidade com outros recursos do Aurora e utilização substancial dos clientes em aplicações de produção.
-
Aurora MySQL versão 3.x (compatível com o MySQL 8.0)
-
Aurora PostgreSQL versão 15.x ou 16.x
-
-
Escolha o modelo de Dev/Test (Desenvolvimento/teste). Essa opção não é significativa para as atividades de sua prova de conceito.
-
Em Instance Size (Tamanho da instância), escolha Memory optimized classes (Classes otimizadas para memória) e uma das classes de instância xlarge. Você pode ajustar a classe da instância para cima ou para baixo posteriormente.
-
Em Multi-AZ Deployment (Implantação Multi-AZ), escolha Create an Aurora Replica or Reader node in a different AZ (Criar uma réplica do Aurora ou nó de leitor em uma AZ diferente). Muitos dos aspectos mais úteis do Aurora envolvem clusters de várias instâncias da banco de dados. Faz sentido começar sempre com pelo menos duas instâncias de banco de dados em qualquer cluster novo. O uso de outra zona de disponibilidade para a segunda instância de banco de dados ajuda a testar cenários de alta disponibilidade diferentes.
-
Ao escolher nomes para as instâncias de banco de dados, use uma convenção de nomenclatura genérica. Não faça referência a nenhuma instância de banco de dados de cluster como o "gravador", pois instâncias de banco de dados diferentes assumem esses perfis conforme necessários. Recomendamos usar algo como
clustername-az-serialnumber, por exemplomyprodappdb-a-01. Esses nomes identificam exclusivamente a instância de banco de dados e sua localização. -
Defina uma retenção de backup alta para o cluster do Aurora. Com um período de retenção longo, é possível executar uma recuperação point-in-time (PITR -point-in-time recovery) por um período de até 35 dias. Você pode redefinir seu banco de dados para um estado conhecido depois de executar testes que envolvem instruções DDL e linguagem de manipulação de dados (DML - data manipulation language). Também é possível recuperá-lo, se você excluir ou alterar dados por engano.
-
Ative recursos adicionais de recuperação, log e monitoramento na criação do cluster. Ative todas as opções em Backtrack, Performance Insights, Monitoramento e Exportações de log. Com esses recursos habilitados, você pode testar a adequação de recursos, como retrocesso, monitoramento avançado e Performance Insights, à sua workload. Você também pode investigar facilmente a performance e solucionar problemas durante a prova de conceito.
5. Configure seu esquema
No cluster do Aurora, configure bancos de dados, tabelas, índices, chaves estrangeiras e outros objetos de esquema para seu aplicativo. Se você estiver mudando de outro sistema de banco de dados compatível com MySQL ou PostgreSQL, espere que esse estágio seja simples e direto. Você usa a mesma sintaxe e linha de comando SQL ou outros aplicativos cliente, com os quais está familiarizado, em seu novo mecanismo de banco de dados.
Para emitir instruções SQL no cluster, localize o endpoint do cluster e forneça esse valor como o parâmetro de conexão a seu aplicativo cliente. Você encontra o endpoint do cluster na guia Connectivity (Conectividade) da página de detalhes do cluster. O endpoint do cluster é o rotulado como Writer (Gravador). O outro endpoint, rotulado como Reader (Leitor), representa uma conexão somente leitura que você pode fornecer aos usuários finais que executam relatórios ou outras consultas somente leitura. Para obter ajuda com qualquer problema relativo à conexão ao cluster, consulte Como conectar-se a um cluster de bancos de dados Amazon Aurora.
Se você estiver portando seu esquema e dados de outro sistema de banco de dados, espere fazer algumas alterações no esquema neste ponto. Essas alterações no esquema são para fazer a correspondência com a sintaxe e os recursos do SQL disponíveis no Aurora. Você pode excluir determinadas colunas, restrições, triggers ou outros objetos de esquema neste ponto. Isso pode ser útil principalmente se esses objetos exigirem retrabalho para compatibilidade com o Aurora e não forem significativos para os objetivos de sua prova de conceito.
Se você estiver migrando de um sistema de banco de dados com um mecanismo subjacente diferente do Aurora, considere o uso do AWS Schema Conversion Tool (AWS SCT) para simplificar o processo. Para obter detalhes, consulte o Guia do usuário do AWSSchema Conversion Tool. Para obter detalhes gerais sobre as atividades de migração e de portabilidade, consulte o whitepaper da AWS Migrar seus bancos de dados para o Amazon Aurora
Durante esta etapa, é possível avaliar se há ineficiências na configuração de seu esquema, por exemplo, em sua estratégia de indexação ou em outras estruturas de tabelas, como tabelas particionadas. Essas ineficiências podem ser ampliadas quando você implanta seu aplicativo em um cluster com várias instâncias de banco de dados e com uma workload pesada. Considere se você pode fazer um ajuste fino desses aspectos de performance agora ou durante atividades posteriores, como em um teste de comparação completo.
6. Importe seus dados
Durante a prova de conceito, você traz os dados, ou uma amostra representativa dos dados, de seu sistema de banco de dados antigo. Se for prático, configure pelo menos alguns dados em cada uma de suas tabelas. Isso ajuda a testar a compatibilidade de todos os tipos de dados e recursos de esquema. Depois de exercitar os recursos básicos do Aurora, aumente a quantidade de dados. No momento da conclusão da prova de conceito, você deve testar suas ferramentas de ETL, consultas e workload geral com um conjunto de dados que seja grande o suficiente para obter conclusões precisas.
Você pode usar várias técnicas para importar dados de backup físico ou lógico para o Aurora. Para obter detalhes, consulte Migrar dados para um cluster de banco de dados do Amazon Aurora MySQL ou Migrar dados para o Amazon Aurora com compatibilidade com o PostgreSQL, dependendo do mecanismo de banco de dados que você está usando na prova de conceito.
Experimente com as ferramentas de ETL e as tecnologias que estão sendo consideradas. Veja qual delas atende às suas necessidades. Considere tanto a taxa de transferência quanto a flexibilidade. Por exemplo, algumas ferramentas de ETL executam uma transferência uma vez, e outras envolvem a replicação contínua do sistema antigo para o Aurora.
Se estiver migrando de um sistema compatível com MySQL para o Aurora MySQL, você poderá usar as ferramentas de transferência de dados nativas. O mesmo se aplicará, ao migrar de um sistema compatível com o PostgreSQL para o Aurora PostgreSQL. Se estiver migrando de um sistema de banco de dados que usa um mecanismo subjacente diferente do usado pelo Aurora, você poderá experimentar com o AWS Database Migration Service (AWS DMS). Para obter detalhes sobre o AWS DMS, consulte o Guia do usuário do AWS Database Migration Service.
Para obter detalhes sobre as atividades de migração e de portabilidade, consulte o whitepaper da AWS Aurora migration handbook
7. Porte seu código SQL
O teste do SQL e dos aplicativos associados exige níveis diferentes de esforço, dependendo dos diferentes casos. Especificamente, o nível de esforço depende de se a mudança é de um sistema compatível com MySQL ou PostgreSQL ou de outro tipo.
-
Se você estiver mudando do RDS for MySQL ou do RDS for PostgreSQL, as alterações no SQL serão suficientemente pequenas, permitindo que você teste o código SQL original com o Aurora e incorpore as alterações necessárias manualmente.
-
De forma semelhante, se você mudar de um banco de dados local compatível com o MySQL ou o PostgreSQL, poderá testar o código SQL original e incorporar alterações manualmente.
-
Se estiver partindo de um banco de dados comercial diferente, alterações necessárias do SQL serão mais extensivas. Nesse caso, considere usar o AWS SCT.
Durante esta etapa, é possível avaliar se há ineficiências na configuração de seu esquema, por exemplo, em sua estratégia de indexação ou em outras estruturas de tabelas, como tabelas particionadas. Considere se você pode fazer um ajuste fino desses aspectos de performance agora ou durante atividades posteriores, como em um teste de comparação completo.
Você pode verificar a lógica de conexão do banco de dados em seu aplicativo. Para aproveitar o processamento distribuído do Aurora, pode ser necessário usar conexões separadas para operações de leitura e de gravação e usar sessões relativamente curtas para operações de consulta. Para obter informações sobre conexões, consulte 9. Conectar-se ao Aurora.
Considere os compromissos e trocas que você talvez tenha precisado fazer para resolver problemas em seu banco de dados de produção. Reserve tempo na programação da prova de conceito para fazer melhorias em seu design de esquema e consultas. Para determinar se é possível obter ganhos fáceis em performance, custo operacional e escalabilidade, tente as aplicações originais e modificadas lado a lado em diferentes clusters do Aurora.
Para obter detalhes sobre as atividades de migração e de portabilidade, consulte o whitepaper da AWS Aurora migration handbook
8. Especifique definições da configuração
Você também pode rever os parâmetros da configuração de seu banco de dados como parte do exercício de prova de conceito do Aurora. Talvez você já tenha as definições de configuração do MySQL ou do PostgreSQL ajustadas para performance e escalabilidade em seu ambiente atual. O subsistema de armazenamento do Aurora é adaptado e ajustado para um ambiente distribuído baseado na nuvem com um subsistema de armazenamento de velocidade alta. Como resultado, muitas configurações do mecanismo de banco de dados anterior não se aplicam. Recomendamos conduzir experimentos iniciais com as definições de configuração padrão do Aurora. Reaplique as configurações de seu ambiente atual apenas se você encontrar gargalos de performance e de escalabilidade. Se tiver interesse, você poderá analisar esse assunto mais profundamente em Apresentação do mecanismo de armazenamento do Aurora
O Aurora facilita a reutilização das definições da configuração ideais para um aplicativo específico ou caso de uso. Em vez de editar um arquivo de configuração separado para cada instância de banco de dados, você gerencia os conjuntos de parâmetros que atribui a clusters inteiros ou a instâncias de banco de dados específicas. Por exemplo, a configuração do fuso horário se aplica a todas as instâncias de banco de dados no cluster, e você pode ajustar o tamanho do cache de página para cada instância de banco de dados.
Você começa com um dos conjuntos de parâmetros padrão e aplica alterações apenas aos parâmetros que você precisa ajustar. Para obter detalhes sobre como trabalhar com grupos de parâmetros, consulte Parâmetros do cluster de banco de dados e da instância de bancos de dados Amazon Aurora. Para obter as definições da configuração que são ou não aplicáveis aos clusters do Aurora, consulte Parâmetros de configuração do Aurora MySQL ou Amazon Aurora PostgreSQL parameters dependendo de seu mecanismo de banco de dados.
9. Conectar-se ao Aurora
Como você descobre ao criar seu esquema e configuração de dados iniciais e executar consultas de exemplo, é possível conectar-se a endpoints diferentes em um cluster do Aurora. O endpoint a ser usado depende de se a operação é uma leitura, como uma instrução SELECT, ou uma gravação, como uma instrução CREATE ou INSERT. Conforme você aumenta a workload em um cluster do Aurora e experimenta com os recursos do Aurora, é importante que seu aplicativo atribua cada operação ao endpoint adequado.
Ao usar o endpoint do cluster para operações de gravação, você sempre se conecta a uma instância de banco de dados no cluster que tem capacidade de leitura/gravação. Por padrão, apenas uma instância de banco de dados em um cluster do Aurora tem capacidade de leitura/gravação. Essa instância de banco de dados é chamada de instância principal. Se a instância principal original se tornar indisponível, o Aurora ativa um mecanismo de failover e uma outra instância de banco de dados se torna a principal.
De forma semelhante, com o direcionamento de instruções SELECT para o endpoint de leitura, você distribui o trabalho de processamento de consultas entre as instâncias de banco de dados no cluster. Cada conexão de leitor é atribuída a uma instância de banco de dados diferente usando a resolução round-robin do DNS. A realização da maior parte do trabalho de consulta nas réplicas de banco de dados somente leitura do Aurora reduz a carga da instância principal, liberando-a para lidar com instruções DDL e DML.
O uso desses endpoints reduz a dependência de nomes de host embutidos em código, e ajuda seu aplicativo a se recuperar mais rapidamente de falhas na instância de banco de dados.
nota
O Aurora também tem endpoints personalizados criados por você. Esses endpoints não são necessários durante uma prova de conceito.
As réplicas do Aurora estão sujeitas a um atraso, embora esse atraso normalmente seja de 10 a 20 milissegundos. Você pode monitorar o atraso da replicação e decidir se ele está dentro do intervalo de seus requisitos de consistência de dados. Em alguns casos, suas consultas de leitura podem exigir consistência forte de leitura (consistência de leitura após gravação). Nesses casos, você pode continuar a usar o endpoint do cluster para elas e não o endpoint de leitor.
Pera beneficiar-se completamente das capacidades do Aurora para execução paralela distribuída, pode ser necessário alterar a lógica da conexão. O objetivo é evitar o envio de todas as solicitações de leitura para a instância principal. As réplicas somente leitura do Aurora ficam em espera, com todos os mesmos dados, pronta para tratar instruções SELECT. Codifique a lógica de seu aplicativo para usar o endpoint adequado para cada tipo de operação. Siga estas diretrizes gerais:
-
Evite usar uma única string de conexão embutida em código para todas as sessões do banco de dados.
-
Se for prático, coloque as operações de gravação, como instruções DDL e DML, em funções em seu código de aplicativo cliente. Dessa forma, você pode fazer com que diferentes tipos de operações usem conexões específicas.
-
Faça funções separadas para operações de consulta. O Aurora atribui cada nova conexão ao endpoint leitor a uma réplica diferente do Aurora para balancear a carga para aplicações com uso intensivo de leitura.
-
Para operações que envolvem conjuntos de consultas, feche e reabra a conexão ao endpoint do leitor quando cada conjunto de consultas relacionadas for concluído. Use pooling de conexão se esse recurso estiver disponível em sua pilha de software. O direcionamento de consultas para diferentes conexões ajuda o Aurora a distribuir a workload de leitura entre as instâncias de banco de dados no cluster.
Para obter informações gerais sobre o gerenciamento de conexões e endpoints do Aurora, consulte Como conectar-se a um cluster de bancos de dados Amazon Aurora. Para se aprofundar no assunto, consulte o Manual do administrador do banco de dados Aurora MySQL – gerenciamento de conexões
10. Execute sua workload
Depois que as definições do esquema, dos dados e da configuração estiverem estabelecidas, você pode exercitar o cluster executando sua workload. Use uma workload na prova de conceito que espelhe os aspectos principais de suas workload de produção. Recomendamos que a tomada de decisões sobre a performance sempre seja feita usando testes e workloads reais em vez de benchmarking sintético, como o sysbench e o TPC-C. Sempre que for prático, recolha medidas com base em seu próprio esquema, padrões de consulta e volume de uso.
No máximo possível, replique as condições atuais sob as qual o aplicativo será executado. Por exemplo, normalmente, você executa seu código de aplicação em instâncias do Amazon EC2 na mesma região da AWS e na mesma nuvem privada virtual (VPC) que o cluster do Aurora. Se seu aplicativo de produção executar em várias instâncias do EC2 abrangendo várias zonas de disponibilidade, configure o ambiente de sua prova de conceito da mesma forma. Para obter mais informações sobre regiões da AWS, consulte Regiões e zonas de disponibilidade no Guia do usuário da Amazon RDS. Para saber mais sobre o serviço de Amazon VPC, consulte O que é a Amazon VPC? no Guia do usuário da Amazon VPC.
Depois que você verificar se os recursos básicos de seu aplicativo funcionam e puder acessar os dados por meio do Aurora, você poderá exercitar os aspectos do cluster do Aurora. Alguns recursos que você pode tentar são conexões simultâneas com balanceamento de carga, transações simultâneas e replicação automática.
Neste ponto, os mecanismos de transferência de dados já devem ser familiares e, portanto, você pode executar testes com uma proporção maior de dados de amostra.
Este estágio é quando você pode ver os efeitos da alteração da definição da configuração, como os limites de memória e os limites de conexão. Reexamine os procedimentos que você explorou em 8. Especifique definições da configuração.
Você também pode experimentar com mecanismos, como a criação e a restauração de snapshots. Por exemplo, é possível criar clusters com diferentes classes de instância da AWS, números de réplicas da AWS e assim por diante. Depois, em cada cluster, você pode restaurar o mesmo snapshot que contém o esquema e todos os dados. Para obter detalhes desse ciclo, consulte Criar um snapshot de cluster de banco de dados e Restauração de um snapshot de um cluster de banco de dados.
11. Avalie a performance
As melhores práticas desta área são desenvolvidas para garantir que todas as ferramentas e processos corretos estejam configurados para isolar rapidamente comportamentos anormais durante operações de workload. Elas também são configuradas para ver que você pode identificar com confiança todas as causas aplicáveis.
Sempre é possível ver o estado atual do cluster ou examinar tendências ao longo do tempo examinando a guia Monitoring (Monitoramento). Essa guia está disponível na página de detalhes do console para cada cluster ou instância de banco de dados Aurora. Ela exibe as métricas do serviço de monitoramento do Amazon CloudWatch na forma de gráficos. As métricas podem ser filtradas por nome, por instância de banco de dados e por período.
Para ter mais opções na guia Monitoring (Monitoramento), habilite o Monitoramento avançado e o Performance Insights nas configurações do cluster. Essas opções também podem ser habilitadas posteriormente, se você não as escolheu ao configurar o cluster.
Para medir a performance, você depende na maior parte dos gráficos que mostram as atividades de todo o cluster do Aurora. É possível verificar se as réplicas do Aurora têm carga e tempos de resposta semelhantes. Você também pode ver como o trabalho é dividido entre a instância principal de leitura/gravação e as réplicas de somente leitura do Aurora. Se houver desequilíbrio entre as instâncias de banco de dados ou um problema que afeta apenas uma instância de banco de dados, você poderá examinar a guia Monitoring (Monitoramento) da instância específica.
Depois de configurar o ambiente e a workload real para emular seu aplicativo de produção, você poderá medir se a performance do Aurora está boa. As questões mais importantes a serem respondidas são:
-
Quantas consultas por segundo o Aurora está processando? Você pode examinar as métricas de Throughput (Taxa de transferência) para ver os valores de vários tipos de operações.
-
Quanto tempo é necessário, em média, para o Aurora processar uma determinada consulta? Você pode examinar as métricas de Latency (Latência) para ver os valores de vários tipos de operações.
Para visualizar as métricas de throughput e de latência, confira a guia Monitoramento de determinado cluster do Aurora no console do Amazon RDS
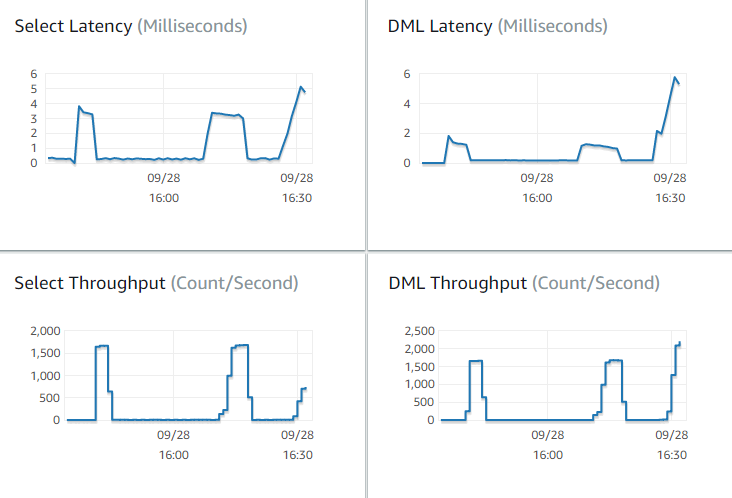
Se possível, estabeleça valores de linha de base para essas métricas em seu ambiente atual. Se isso não for possível, crie uma linha de base no cluster do Aurora executando uma workload equivalente para seu aplicativo de produção. Por exemplo, execute sua workload do Aurora com um número semelhante de usuários e consultas semelhantes. Observe como os valores são alterados conforme você experimenta com diferentes classes de instância, tamanho de cluster, definições da configuração e assim por diante.
Se os números da taxa de transferência forem menores que o esperado, investigue mais os fatores que afetam a performance do banco de dados para sua workload. De forma semelhante, se os números de latência forem mais altos do que o esperado, investigue mais. Para isso, monitore as métricas secundárias do servidor de banco de dados (CPU, memória etc.) Você pode ver se as instâncias de banco de dados estão próximas de seus limites. Você também pode ver a quantidade de capacidade extra que suas instâncias de banco de dados têm para lidar com mais consultas simultâneas, consultas em tabelas grandes e assim por diante.
dica
Para detectar os valores das métricas que estão além dos intervalos esperados, configure alarmes do CloudWatch.
Ao avaliar o tamanho ideal do cluster do Aurora e da capacidade, você pode localizar a configuração que atinge picos de performance do aplicativo sem provisionar os recursos em excesso. Um fator importante é encontrar o tamanho adequado para as instâncias de banco de dados no cluster do Aurora. Comece selecionando um tamanho de instância que tenha capacidade semelhante de CPU e memória para seu ambiente de produção atual. Colete os números de taxa de transferência e latência para a workload desse tamanho de instância. Aumente a instância para o próximo tamanho maior. Verifique se os números de taxa de transferência e latência melhoram. Também reduza o tamanho da instância e verifique se os números de latência e taxa de transferência permanecem os mesmos. Sua meta é obter a taxa de transferência mais alta, com a latência mais baixa, na menor instância possível.
dica
Dimensione seus clusters do Aurora e as instâncias de banco de dados associadas com capacidade existente suficiente para lidar com picos de tráfego repentino e imprevisíveis. Para bancos de dados de missão crítica, deixe pelo menos 20 por cento de capacidade adicional para CPU e memória.
Execute testes de performance longos o suficiente para medir a performance do banco de dados em um estado quente e estável. Pode ser necessário executar a workload por muitos minutos ou por até algumas horas para atingir o estado estável. No início de uma execução, é normal ter alguma variação. Essa variação ocorre porque cada réplica do Aurora aquece seus caches com base nas consultas SELECT que trata.
O Aurora executa melhor com workloads transacionais que envolvem vários usuários e consultas simultâneos. Para garantir que você está direcionando carga suficiente para performance ideal, execute comparações que usam multithreading ou execute várias instâncias dos testes de performance simultaneamente. Meça a performance com centenas ou até milhares de threads de clientes simultâneos. Simule o número de threads simultâneos que você espera ter em seu ambiente de produção. Também é possível executar testes de stress adicionais com mais threads para medir a escalabilidade do Aurora.
12. Exercite a alta disponibilidade do Aurora
Muitos dos principais recursos do Aurora envolvem alta disponibilidade. Esses recursos incluem replicação automática, failover automático, backups automáticos com restauração point-in-time e habilidade de adicionar instâncias de banco de dados ao cluster. A segurança e a confiabilidade de recursos como esses são importantes para aplicativos de missão crítica.
Para avaliar esses recursos é necessário ter uma certa visão. Em atividades anteriores, como na medição de performance, você observa com o sistema desempenha quando tudo funciona corretamente. O teste de alta disponibilidade exige que você imagine o comportamento de pior caso. Você deve considerar vários tipos de falhas, mesmo que essas condições sejam raras. Você deve introduzir problemas intencionalmente para ter certeza de que o sistema se recupera correta e rapidamente.
dica
Para uma prova de conceito, configure todas as instâncias de banco de dados em um cluster do Aurora com a mesma classe de instância da AWS. Isso possibilita testar os recursos de disponibilidade do Aurora sem maiores alterações na performance e na escalabilidade quando você desativar instâncias de banco de dados para simular falhas.
Recomendamos usar pelo menos duas instâncias em cada cluster do Aurora. As instâncias de banco de dados em um cluster do Aurora podem abranger até três zonas de disponibilidade (AZs). Localize cada uma das duas ou três primeiras instâncias de banco de dados em uma AZ diferente. Quando começar a usar clusters maiores, espalhe as instâncias de banco de dados em todas as AZs em sua região da AWS. Isso aumenta a capacidade de tolerância a falhas. Mesmo que um problema afete uma AZ inteira, o Aurora poderá fazer failover para uma instância de banco de dados em outra AZ. Se você executar um cluster com mais de três instâncias, distribua as instâncias de banco de dados o mais uniformemente quanto possível sobre todas as três AZs.
dica
O armazenamento de um cluster do Aurora é independente das instâncias de banco de dados. O armazenamento de cada cluster do Aurora sempre abrange três AZs.
Ao testar recursos de alta disponibilidade, sempre use instâncias de banco de dados com capacidade idêntica em seu cluster de teste. Isso evita alterações imprevisíveis na performance, na latência e assim por diante sempre que uma instância de banco de dados toma o lugar de outra.
Para saber mais sobre como simular condições de falha para testar recursos de alta disponibilidade, consulte. Testar o Amazon Aurora MySQL usando consultas de injeção de falhas.
Como parte do exercício de prova de conceito, um objetivo é encontrar o número ideal de instâncias de banco de dados e a classe de instância ideal para essas instâncias de banco de dados. Fazer isso exige o balanceamento dos requisitos de alta disponibilidade e performance.
No Aurora, quando mais instâncias de banco de dados você tiver em um cluster, maiores serão os benefícios para a alta disponibilidade. Ter mais instâncias de banco de dados também melhora a escalabilidade de aplicações com uso intensivo de leitura. O Aurora pode distribuir várias conexões para consultas SELECT entre as réplicas apenas para leitura do Aurora.
Por outro lado, a limitação do número de instâncias de banco de dados reduz o tráfego da replicação no nó principal. O tráfego de replicação consome largura de banda de rede, que é outro aspecto da performance e da escalabilidade gerais. Portanto, para aplicativos OLTP com uso intensivo de gravação, prefira ter um número menor de instâncias de banco de dados grandes em vez de ter muitas instâncias de banco de dados pequenas.
Em um cluster típico do Aurora, uma instância de banco de dados (a instância principal) trata todas as instruções DDL e DML. As outras instâncias de banco de dados (as réplicas do Aurora) tratam apenas de instruções SELECT. Embora as instâncias de banco de dados não executem exatamente a mesma quantidade de trabalho, recomendamos usar a mesma classe de instância para todas as instâncias de banco de dados no cluster. Dessa forma, se ocorrer uma falha, e o Aurora promover uma das instâncias de banco de dados somente leitura para que seja a nova instância principal, a instância principal terá a mesma capacidade que a anterior.
Se você precisar usar instâncias de banco de dados de diferentes capacidades no mesmo cluster, configure camadas de failover para as instâncias de banco de dados. Essas camadas determinam a ordem em que as réplicas do Aurora são promovidas pelo mecanismo de failover. Coloque as instâncias de banco de dados que forem muito maiores ou menores que as outras em uma camada de failover inferior. Isso garante que elas sejam escolhidas por último para promoção.
Exercite os recursos de recuperação de dados do Aurora, como restauração automática em um ponto no tempo, snapshots e restaurações manuais e retrocesso de cluster. Se for adequado, copie snapshots em outras regiões da AWS e restaure em outras regiões da AWS para simular cenários de DR.
Investigue os requisitos de sua organização para o objetivo de tempo de restauração RTO (restore time objective), o objetivo de ponto de restauração (RPO - restore point objective) e a redundância geográfica. A maioria das organizações agrupam esses itens sob a ampla categoria de recuperação de desastres. Avalie os recursos de alta disponibilidade do Aurora nesta seção no contexto de seu processo de recuperação de desastres para garantir que seus requisitos de RTO e RPO sejam atendidos.
13. O que fazer em seguida
No final de um processo de prova de conceito bem-sucedido, você confirma que o Aurora é uma solução adequada para você com base na workload antecipada. Em todos os processos anteriores, você verificou como o Aurora funciona em um ambiente operacional realístico e o avaliou em relação a seus critérios de sucesso.
Depois que tiver seu ambiente de banco de dados ativo e em execução com o Aurora, você poderá avançar para etapas de avaliação mais detalhadas, resultando em sua migração final e implantação em produção. Dependendo de sua situação, essas outras etapas podem ou não serem incluídas no processo de prova de conceito. Para obter detalhes sobre as atividades de migração e de portabilidade, consulte o whitepaper da AWS Aurora migration handbook
Em outra próxima etapa, considere as configurações de segurança relevantes para sua workload e projetadas para atender a seus requisitos de segurança em um ambiente de produção. Planeje os controles a serem estabelecidos para proteger o acesso às credenciais do usuário mestre do cluster do Aurora. Defina as funções e responsabilidades dos usuários do banco de dados para controlar o acesso aos dados armazenados no cluster do Aurora. Considere os requisitos de acesso ao banco de dados para aplicativos, scripts e ferramentas ou serviços de terceiros. Explore os serviços e os recursos da AWS, como a autenticação do AWS Secrets Manager e do AWS Identity and Access Management (IAM).
Neste ponto, você deve entender os procedimentos e as melhores práticas para executar testes de comparação com o Aurora. Você pode descobrir que é necessário fazer ajuste de performance adicional. Para obter detalhes, consulte Como gerenciar a performance e a escalabilidade de clusters de banco de dados do Aurora, Melhorias de performance do Amazon Aurora MySQL, Performance e escalabilidade do Amazon Aurora PostgreSQL e Monitorar a carga de banco de dados com o Performance Insights no Amazon Aurora. Ao fazer ajuste adicional, esteja familiarizado com as métricas que coletou durante a prova de conceito. Em uma próxima etapa, você pode criar novos clusters com diferentes opções de definições de configuração, mecanismo de banco de dados e versão de banco de dados. Ou você pode criar tipos especializados de clusters do Aurora para que correspondam às necessidades de casos de uso específicos.
Por exemplo, você pode explorar os clusters de consulta paralela do Aurora para aplicativos de processamento transacional/analítico híbrido (HTAP - hybrid transaction/analytical processing). Se uma distribuição geográfica ampla for essencial para a recuperação de desastres ou para minimizar a latência, você poderá explorar os bancos de dados globais do Aurora. Se sua workload for intermitente ou se você estiver usando o Aurora em um cenário de desenvolvimento/teste, você poderá explorar os clusters do Aurora Serverless.
Seus clusters de produção também podem precisar lidar com volumes altos de conexões de entrada. Para saber mais sobre essas técnicas, consulte o whitepaper da AWSAurora MySQL database administrator's handbook – Connection management
Se, depois da prova de conceito, você decidir que seu caso de uso não é adequado para o Aurora, considere estes outros serviços da AWS:
-
Para casos de uso puramente analíticos, as workloads se beneficiam de um formato de armazenamento colunar e de outros recursos mais adequados às workloads OLAP. Os serviços do AWS que abordam esses casos de uso incluem o seguinte:
-
Muitas workloads se beneficiam de uma combinação do Aurora com um ou mais desses serviços. Você pode mover dados entre esses serviços usando:
-
Importar do Amazon S3, conforme descrito no Guia do usuário do Amazon Aurora
-
Exportar para o Amazon S3, conforme descrito no Guia do usuário do Amazon Aurora
-
Muitas outras ferramentas de ETL populares
