Criar um cluster de banco de dados do Babelfish para Aurora PostgreSQL
O Babelfish para Aurora PostgreSQL é compatível com todas as versões do Aurora PostgreSQL, 13 e posteriores.
Você pode usar o AWS Management Console ou a AWS CLI para criar um cluster do Aurora PostgreSQL com o Babelfish.
nota
Em um cluster do Aurora PostgreSQL, o nome do banco de dados babelfish_db é reservado para Babelfish. Criar seu próprio banco de dados “babelfish_db” em um Babelfish for Aurora PostgreSQL impede o Aurora de provisionar com êxito o Babelfish.
Para criar um cluster com o Babelfish em execução com o AWS Management Console
-
Abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
e escolha Create database (Criar banco de dados). 
-
Em Choose a database creation method (Escolha um método de criação de banco de dados), siga um destes procedimentos:
-
Para especificar opções detalhadas do mecanismo, escolha Standard create (Criação padrão).
-
Para utilizar opções pré-configuradas que oferecem suporte a práticas recomendadas para um cluster do Aurora, escolha Easy create (Criação fácil).
-
-
Em Tipo de mecanismo, escolha Aurora (compatível com PostgreSQL).
-
Para Available versions (Versões disponíveis), escolha uma versão do Aurora PostgreSQL. Para obter os recursos mais recentes do Babelfish, escolha a versão principal mais recente do Aurora PostgreSQL. O Babelfish é compatível com todas as versões do Aurora PostgreSQL, 13 e posteriores.
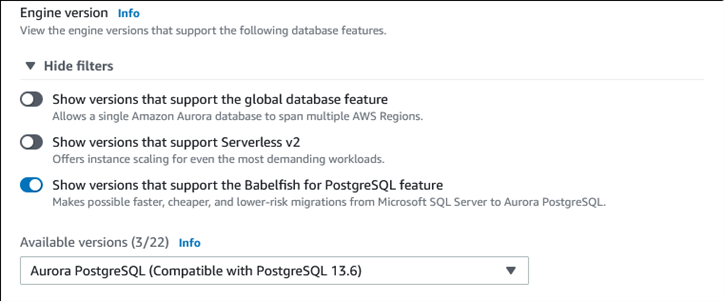
-
Para Templates (Modelos), escolha o modelo que corresponde ao seu caso de uso.
-
Para DB cluster identifier (Identificador do cluster de banco de dados), insira um nome que seja possível encontrar facilmente mais tarde na lista de clusters de banco de dados.
-
Para Master username (Nome de usuário primário), insira um nome de usuário de administrador. O valor padrão do Aurora PostgreSQL é
postgres. Você pode aceitar o padrão ou escolher um nome diferente. Por exemplo, para seguir a convenção de nomenclatura usada em seus bancos de dados do SQL Server, você pode inserirsa(administrador do sistema) para o nome de usuário principal.Se você não criar um usuário chamado
sanessa ocasião, poderá criá-lo mais tarde com sua opção de cliente. Depois de criar o usuário, use o comandoALTER SERVER ROLEpara adicioná-lo ao gruposysadmin(perfil) para o cluster.Atenção
O nome do usuário principal deve sempre usar caracteres minúsculos, caso contrário, o cluster de banco de dados não conseguirá se conectar ao Babelfish por meio da porta TDS.
-
Em Master password (Senha principal), crie uma senha forte e confirme-a.
-
Para as opções seguintes, até a seção Babelfish settings (Configurações do Babelfish), especifique as configurações do seu cluster de banco de dados. Para obter informações sobre cada configuração, consulte Configurações de clusters de bancos de dados do Aurora.
-
Para disponibilizar a funcionalidade do Babelfish, marque a caixa Turn on Babelfish (Ativar o Babelfish).
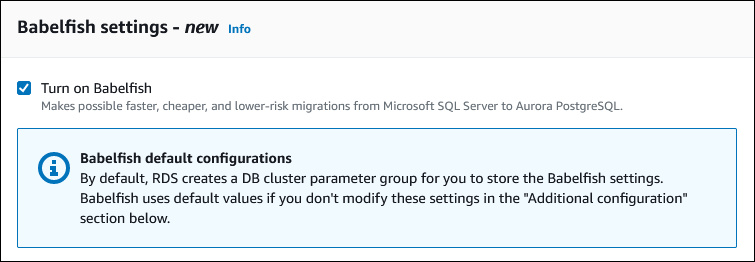
-
Para DB cluster parameter group (Grupo de parâmetros de cluster de banco de dados), siga um destes procedimentos:
-
Escolha Create new (Criar novo) para criar um novo grupo de parâmetros com o Babelfish ativado.
-
Selecione Choose existing (Escolher existente) para utilizar um grupo de parâmetros existente. Se você utilizar um grupo existente, modifique esse grupo antes de criar o cluster e adicionar valores para os parâmetros do Babelfish. Para obter informações sobre os parâmetros do Babelfish, consulte Configurações de grupo de parâmetros de cluster de banco de dados para o Babelfish.
Se você utilizar um grupo existente, forneça o nome desse grupo na caixa seguinte.
-
-
Para Database migration mode (Modo de migração de banco de dados), escolha uma das seguintes opções:
-
Single database (Banco de dados único) para migrar um único banco de dados SQL Server.
Em alguns casos, é possível migrar vários bancos de dados de usuários juntos quando seu objetivo final é uma migração completa para o Aurora PostgreSQL nativo sem o Babelfish. Se as aplicações finais exigirem esquemas consolidados (um único esquema
dbo), certifique-se de primeiro consolidar seus bancos de dados do SQL Server em um único banco de dados do SQL Server. Em seguida, migre para o Babelfish utilizando o modo Single database (Banco de dados único). -
Multiple databases (Vários bancos de dados) para migrar vários bancos de dados do SQL Server (originados de uma única instalação do SQL Server). O modo de banco de dados múltiplo não consolida vários bancos de dados que não são provenientes de uma única instalação do SQL Server. Para obter informações sobre como migrar vários bancos de dados, consulte Utilizar o Babelfish com um único banco de dados ou vários bancos de dados.
nota
A partir do Aurora PostgreSQL versão 16, vários bancos de dados são escolhidos por padrão como o modo de migração de banco de dados.

-
-
Para Default collation locale (Localidade do agrupamento padrão), insira a localidade do servidor. O padrão é
en-US. Para obter informações detalhadas sobre agrupamentos, consulte Noções básicas sobre agrupamentos no Babelfish para Aurora PostgreSQL. -
Para o campo Collation name (Nome do agrupamento), insira o agrupamento padrão. O padrão é
sql_latin1_general_cp1_ci_as. Para obter informações detalhadas, consulte Noções básicas sobre agrupamentos no Babelfish para Aurora PostgreSQL. -
Para DB parameter group (Grupo de parâmetros de banco de dados), escolha um grupo de parâmetros ou faça com que o Aurora crie um novo grupo para você com configurações padrão.
-
Para Failover priority (Prioridade de failover), escolha uma prioridade de failover para a instância. Se você não escolher um valor, o padrão será
tier-1. Essa prioridade determina a ordem em que as réplicas do são promovidas durante a recuperação de uma falha de instância primária. Para obter mais informações, consulte Tolerância a falhas para um cluster de banco de dados do Aurora. -
Para Backup retention period (Período de retenção de backup), escolha por quanto tempo (de 1 a 35 dias) o Aurora retém as cópias de backup do banco de dados. Você pode usar cópias de backup para restaurações point-in-time (PITR) do banco de dados, contabilizando até os segundos. O período de retenção padrão é de sete dias.
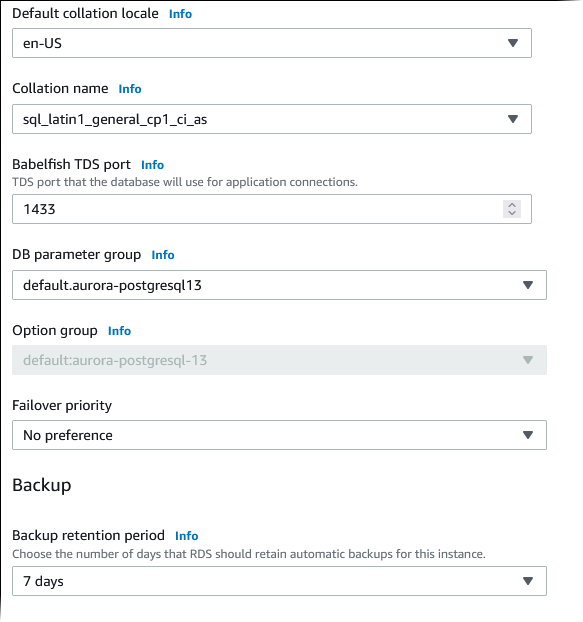
-
Escolha Copy tags to snapshots (Copiar etiquetas para snapshots) para copiar qualquer etiqueta da instância de banco de dados para um snapshot de banco de dados quando você cria um snapshot.
nota
Ao restaurar um cluster de banco de dados a partir de um snapshot, ele não é restaurado como um cluster de banco de dados do Babelfish para Aurora PostgreSQL. É necessário ativar os parâmetros que controlam as preferências do Babelfish no grupo de parâmetros do cluster de banco de dados para ativar o Babelfish novamente. Para ter mais informações sobre os parâmetros do Babelfish, consulte Configurações de grupo de parâmetros de cluster de banco de dados para o Babelfish.
-
Escolha Enable encryption (Habilitar criptografia) para ativar a criptografia em repouso (criptografia de armazenamento do Aurora) neste cluster de banco de dados.
-
Escolha Enable Performance Insights (Habilitar Performance Insights) para ativar o Amazon RDS Performance Insights.
-
Escolhe Enable enhanced monitoring (Habilitar monitoramento avançado) para iniciar a coleta de métricas em tempo real do sistema operacional em que o cluster de banco de dados é executado.
-
Escolha PostgreSQL log (Log do PostgreSQL) para publicar os arquivos de log no Amazon CloudWatch Logs.
-
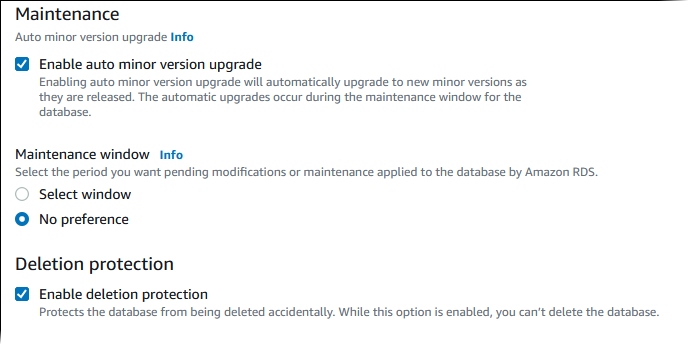
Escolha Enable auto minor version upgrade (Habilitar upgrade automático da versão secundária) para atualizar automaticamente o cluster de bancos de dados Aurora quando um upgrade de versão secundária estiver disponível.
-
Para Maintenance window (Janela de manutenção), faça o seguinte:
-
Para escolher um horário para o Amazon RDS fazer modificações ou manutenções, escolha Select window (Selecionar janela).
-
Para fazer a manutenção do Amazon RDS em um horário não programado, escolha No preference (Sem preferência).
-
-
Marque a caixa Enable deletion protection (Habilitar proteção contra exclusão) para evitar que o seu banco de dados seja excluído por acidente.
Se você ativar esse recurso, não poderá excluir o banco de dados diretamente. Em vez disso, você precisará modificar o cluster de banco de dados e desativar esse recurso antes de excluir o banco de dados.
-
Selecione Criar banco de dados.
Você pode encontrar seu novo banco de dados configurado para o Babelfish na lista Databases (Bancos de dados). A coluna Status mostrará Available (Disponível) quando a implantação estiver concluída.
Quando você cria um Babelfish para Aurora PostgreSQL usando aAWS CLI, precisa passar ao comando o nome do grupo de parâmetros de cluster de banco de dados a ser usado para o cluster. Para obter mais informações, consulte Pré-requisitos do cluster de banco de dados.
Para poder utilizar a AWS CLI para criar um cluster do Aurora PostgreSQL com o Babelfish, faça o seguinte:
-
Escolha o URL do endpoint na lista de serviços em Endpoints e cotas do Amazon Aurora.
-
Crie um grupo de parâmetros para o cluster. Para obter mais informações sobre grupos de parâmetros, consulte Grupos de parâmetros para Amazon Aurora.
-
Modifique o grupo de parâmetros adicionando o parâmetro que ativa o Babelfish.
Para criar um cluster de bancos de dados Aurora PostgreSQL com o Babelfish utilizando a AWS CLI
Os exemplos a seguir usam o nome de usuário principal padrão, postgres. Se necessário, substitua-o pelo nome de usuário criado para o cluster de banco de dados, como sa ou qualquer nome de usuário escolhido se não aceitou o padrão.
-
Criar um grupo de parâmetros.
Para Linux, macOS ou Unix:
aws rds create-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --db-parameter-group-familyaurora-postgresql14\ --description"description"Para Windows:
aws rds create-db-cluster-parameter-group ^ --endpoint-urlendpoint-URL^ --db-cluster-parameter-group-nameparameter-group^ --db-parameter-group-familyaurora-postgresql14^ --description"description" -
Modifique seu grupo de parâmetros para ativar o Babelfish.
Para Linux, macOS ou Unix:
aws rds modify-db-cluster-parameter-group \ --endpoint-urlendpoint-url\ --db-cluster-parameter-group-nameparameter-group\ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot"Para Windows:
aws rds modify-db-cluster-parameter-group ^ --endpoint-urlendpoint-url^ --db-cluster-parameter-group-nameparamater-group^ --parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" -
Identifique o grupo de sub-redes de banco de dados e o ID do grupo de segurança da nuvem privada virtual (VPC) do seu novo cluster de banco de dados. Em seguida, chame o comando create-db-cluster.
Para Linux, macOS ou Unix:
aws rds create-db-cluster \ --db-cluster-identifiercluster-name\ --master-usernamepostgres\ --manage-master-user-password \ --engine aurora-postgresql \ --engine-version14.3\ --vpc-security-group-idssecurity-group\ --db-subnet-group-namesubnet-group-name\ --db-cluster-parameter-group-nameparameter-groupPara Windows:
aws rds create-db-cluster ^ --db-cluster-identifiercluster-name^ --master-usernamepostgres^ --manage-master-user-password ^ --engine aurora-postgresql ^ --engine-version14.3^ --vpc-security-group-idssecurity-group^ --db-subnet-group-namesubnet-group^ --db-cluster-parameter-group-nameparameter-groupEste exemplo especifica a opção
--manage-master-user-passwordpara gerar a senha mestra do usuário e gerenciá-la no Secrets Manager. Para obter mais informações, consulte Gerenciamento de senhas com Amazon Aurora e AWS Secrets Manager. Como alternativa, você pode usar a opção--master-passwordpara especificar e gerenciar a senha por conta própria. -
Crie explicitamente a instância primária do cluster de banco de dados. Use o nome do cluster criado na etapa 3 para o argumento
--db-cluster-identifierao chamar o comando create-db-instance, conforme mostrado a seguir.Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-instance-identifierinstance-name\ --db-instance-classdb.r6g\ --db-subnet-group-namesubnet-group\ --db-cluster-identifiercluster-name\ --engine aurora-postgresqlPara Windows:
aws rds create-db-instance ^ --db-instance-identifierinstance-name^ --db-instance-classdb.r6g^ --db-subnet-group-namesubnet-group^ --db-cluster-identifiercluster-name^ --engine aurora-postgresql
