As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Convertendo processos ETL em in AWS Glue AWS Schema Conversion Tool
A seguir, você pode encontrar um resumo do processo para converter scripts ETL em with. AWS Glue AWS SCT Neste exemplo, convertemos um banco de dados Oracle para Amazon Redshift com os processos de ETL usados nos data warehouses e bancos de dados de origem.
Tópicos
O diagrama de arquitetura a seguir mostra um exemplo de projeto de migração de banco de dados que inclui a conversão de scripts ETL em AWS Glue.
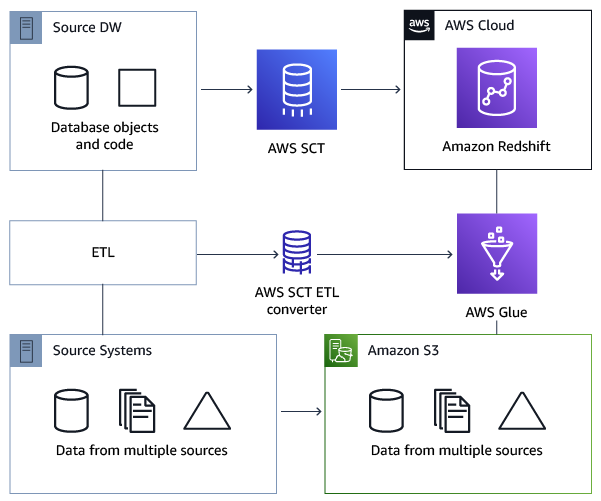
Pré-requisitos
Antes de começar, faça o seguinte:
-
Migre todos os bancos de dados de origem que pretende migrar para a AWS.
-
Migre os data warehouses de destino para o. AWS
-
Colete uma lista de todos os códigos envolvidos em seu processo de ETL.
-
Colete uma lista de todas as informações de conexão necessárias para cada banco de dados.
Além disso, AWS Glue precisa de permissões para acessar outros AWS recursos em seu nome. Você fornece essas permissões usando AWS Identity and Access Management (IAM). Certifique-se de ter criado uma política do IAM para AWS Glue. Para obter mais informações, consulte Criar uma política do IAM para o AWS Glueservice no Guia do AWS Glue desenvolvedor.
Entendendo o catálogo AWS Glue de dados
Como parte do processo de conversão, AWS Glue carrega informações sobre os bancos de dados de origem e destino. Ele organiza essas informações em categorias, em uma estrutura chamada de árvore. A estrutura inclui o seguinte:
-
Conexões: parâmetros de conexão
-
Crawlers: uma lista de crawlers, um crawler para cada esquema
-
Bancos de dados: contêineres que contêm tabelas
-
Tabelas: definições de metadados que representam os dados nas tabelas
-
Tarefas de ETL: lógica de negócios que executa a tarefa de ETL
-
Acionadores — Lógica que controla quando uma tarefa de ETL é executada AWS Glue (seja sob demanda, por agendamento ou acionada por eventos de trabalho)
O Catálogo de dados do AWS Glue é um índice para as métricas de localização, esquema e tempo de execução de seus dados. Quando você trabalha com AWS Glue e AWS SCT, o Catálogo de AWS Glue Dados contém referências a dados que são usados como fontes e destinos de suas tarefas de ETL em AWS Glue. Para criar seu data warehouse, catalogue esses dados.
Use as informações no catálogo de dados para criar e monitorar suas tarefas de ETL. Normalmente, você executa um crawler para fazer o inventário dos dados nos armazenamentos de dados, mas há outras maneiras de adicionar tabelas de metadados ao seu Catálogo de dados.
Ao definir uma tabela no catálogo de dados, você a adiciona a um banco de dados. Um banco de dados é usado para organizar tabelas em AWS Glue.
Limitações para conversão usando com AWS SCT AWS Glue
As limitações a seguir se aplicam ao converter usando AWS SCT com AWS Glue.
| Recurso | Limite padrão |
| Número de bancos de dados para cada conta | 10.000 |
| Número de tabelas para cada banco de dados | 100.000 |
| Número de partições para cada tabela | 1.000.000 |
| Número de versões de tabela para cada tabela | 100.000 |
| Número de tabelas para cada conta | 1.000.000 |
| Número de partições para cada conta | 10,000,000 |
| Número de versões de tabela para cada conta | 1.000.000 |
| Número de conexões para cada conta | 1.000 |
| Número de crawlers para cada conta | 25 |
| Número de tarefas para cada conta | 25 |
| Número de gatilhos para cada conta | 25 |
| Número de execuções de tarefas simultâneas para cada conta | 30 |
| Número de execuções de tarefas simultâneas para cada tarefa | 3 |
| Número de tarefas para cada gatilho | 10 |
| Número de endpoints de desenvolvimento para cada conta | 5 |
| Máximo de unidades de processamento de dados (DPUs) usadas por um endpoint de desenvolvimento ao mesmo tempo | 5 |
| Máximo DPUs usado por uma função ao mesmo tempo | 100 |
| Tamanho do nome do banco de dados |
Ilimitado Para compatibilidade com outros armazenamentos de metadados, como o Apache Hive, o nome é alterado para usar caracteres minúsculos. Se você planeja acessar o banco de dados a partir do Amazon Athena, forneça um nome somente com caracteres alfanuméricos e sublinhados. |
| Tamanho do nome da conexão | Ilimitado |
| Tamanho do nome do crawler | Ilimitado |
Etapa 1: criar um novo projeto
Para criar um novo projeto, siga estas etapas de alto nível:
-
Crie um novo projeto em AWS SCT. Para obter mais informações, consulte Iniciando e gerenciando projetos em AWS SCT.
-
Adicione seus bancos de dados de origem e destino ao projeto. Para obter mais informações, consulte Adicionando servidores ao projeto em AWS SCT.
Certifique-se de ter escolhido Usar AWS Glue nas configurações de conexão do banco de dados de destino. Para fazer isso, escolha a guia AWS Glue. Em Copiar do AWS perfil, escolha o perfil que você deseja usar. O perfil deve preencher automaticamente a chave de AWS acesso, a chave secreta e a pasta de bucket do Amazon S3. Se isso não ocorrer, insira essas informações por conta própria. Depois de escolher OK, AWS Glue analisa os objetos e carrega os metadados no Catálogo de AWS Glue Dados.
Dependendo de suas configurações de segurança, você poderá receber uma mensagem de aviso informando que sua conta não tem privilégios suficientes para alguns dos esquemas no servidor. Se você tiver acesso aos esquemas que está usando, poderá ignorar essa mensagem com segurança.
-
Para concluir a preparação para importar o ETL, conecte-se com os bancos de dados de origem e destino. Para fazer isso, escolha seu banco de dados na árvore de metadados de origem ou de destino e, em seguida, selecione Conectar ao servidor.
AWS Glue cria um banco de dados no servidor de banco de dados de origem e outro no servidor de banco de dados de destino para ajudar na conversão de ETL. O banco de dados no servidor de destino contém o Catálogo AWS Glue de Dados. Para localizar objetos específicos, use a pesquisa nos painéis de origem ou destino.
Para ver como um objeto específico é convertido, localize um item que você deseja converter e selecione Converter esquema no menu de contexto (clique com o botão direito do mouse). O AWS SCT transforma o objeto selecionado em um script.
Você pode revisar o script convertido na pasta Scripts, no painel direito. Atualmente, o script é um objeto virtual, disponível somente como parte do seu AWS SCT projeto.
Para criar um AWS Glue trabalho com seu script convertido, faça o upload do seu script para o Amazon S3. Para isso, escolha o script e selecione Salvar no S3 no menu de contexto (clique com o botão direito do mouse).
Etapa 2: criar um AWS Glue trabalho
Depois de salvar o script no Amazon S3, você pode escolhê-lo e, em seguida, escolher Configure AWS Glue Job para abrir o assistente para configurar o AWS Glue trabalho. O assistente facilita essa configuração:
-
A primeira guia, Fluxo de dados de design, permite escolher uma estratégia de execução e a lista de scripts que você deseja incluir na tarefa. Você pode escolher parâmetros para cada script. Também é possível reorganizar os scripts para que eles sejam executados na ordem correta.
-
Na segunda guia, dê um nome à tarefa e configure diretamente as definições para o AWS Glue. Nessa tela, configure as seguintes definições:
-
AWS Identity and Access Management Função (IAM)
-
Nomes e caminhos de arquivo do script
-
Criptografe o script usando criptografia do lado do servidor com chaves gerenciadas pelo Amazon S3 (SSE-S3)
-
Diretório temporário
-
Caminho da biblioteca Python gerada
-
Caminho da biblioteca Python do usuário
-
Caminho para os arquivos .jar dependentes
-
Caminho de arquivos referenciados
-
Concorrente DPUs para cada execução de trabalho
-
Simultaneidade máxima
-
Tempo limite da tarefa (em minutos)
-
Limite de notificação de atraso (em minutos)
-
Número de novas tentativas
-
Configuração de segurança.
-
Criptografia do lado do servidor
-
-
Na terceira etapa, ou guia, escolha a conexão configurada com o endpoint de destino.
Depois de concluir a configuração da tarefa, ela é exibida sob as tarefas ETL no Catálogo de AWS Glue Dados. Se você escolher a tarefa, as configurações serão exibidas para que possa rever e editá-las. Para criar um novo trabalho em AWS Glue, escolha Create AWS Glue Job no menu de contexto (clique com o botão direito do mouse) do job. Isso aplica a definição de esquema. Para atualizar a exibição, selecione Atualizar a partir do banco de dados no menu de contexto (clique com o botão direito do mouse).
Nesse ponto, você pode ver seu trabalho no AWS Glue console. Para fazer isso, faça login no AWS Management Console e abra o AWS Glue console em https://console.aws.amazon.com/glue/
Você pode testar a nova tarefa para garantir que ela está funcionando corretamente. Para fazer isso, verifique os dados na tabela de origem e se a tabela de destino está vazia. Execute a tarefa e verifique novamente. Você pode ver os registros de erros no AWS Glue console.
