As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migração de cargas de trabalho do Hadoop para o Amazon EMR com AWS Schema Conversion Tool
Para migrar clusters do Apache Hadoop, certifique-se de usar a AWS SCT versão 1.0.670 ou superior. Além disso, familiarize-se com a interface de linha de comandos (CLI) da AWS SCT. Para obter mais informações, consulte Referência CLI para AWS Schema Conversion Tool.
Tópicos
Visão geral da migração
A imagem a seguir mostra o diagrama de arquitetura da migração do Apache Hadoop para o Amazon EMR.
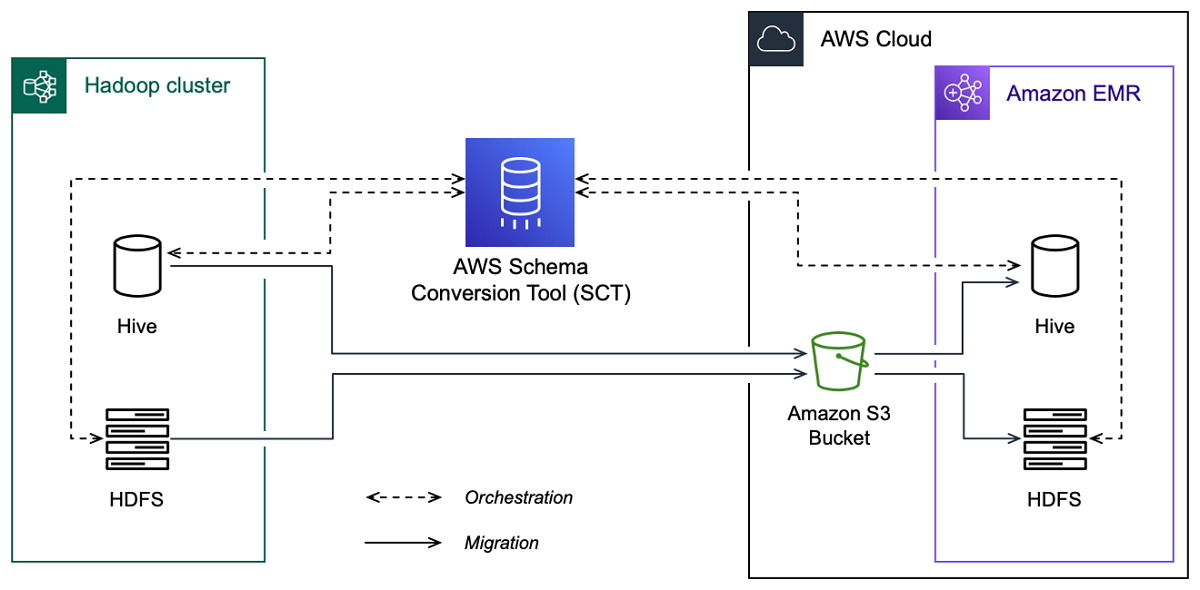
AWS SCT migra dados e metadados do seu cluster Hadoop de origem para um bucket do Amazon S3. Em seguida, a AWS SCT usa seus metadados de origem do Hive para criar objetos de banco de dados no serviço Hive do Amazon EMR de destino. Opcionalmente, você pode configurar o Hive para usar o AWS Glue Data Catalog como seu metastore. Nesse caso, AWS SCT migra seus metadados de origem do Hive para o. AWS Glue Data Catalog
Em seguida, você pode usar AWS SCT para migrar os dados de um bucket do Amazon S3 para seu serviço de destino do Amazon EMR HDFS. Como alternativa, você pode deixar os dados em seu bucket do Amazon S3 e usá-los como um repositório de dados para suas workloads do Hadoop.
Para iniciar a migração do Hapood, você cria e executa seu script CLI AWS SCT . Esse script inclui o conjunto completo de comandos para executar a migração. Você pode baixar e editar um modelo do script de migração do Hadoop. Para obter mais informações, consulte Obter cenários de CLI.
Certifique-se de que seu script inclua as etapas a seguir para que você possa executar sua migração do Apache Hadoop para o Amazon S3 e o Amazon EMR.
Etapa 1: conectar-se aos clusters do Hadoop
Para iniciar a migração do seu cluster Apache Hadoop, crie um novo projeto. AWS SCT Em seguida, conecte-se aos clusters de origem e de destino. Certifique-se de criar e provisionar seus AWS recursos de destino antes de iniciar a migração.
Nesta etapa, você usa os seguintes comandos da AWS SCT CLI.
CreateProject— para criar um novo AWS SCT projeto.AddSourceCluster: para conectar-se ao cluster Hadoop de origem em seu projeto da AWS SCT .AddSourceClusterHive: para conectar-se ao serviço Hive de origem em seu projeto.AddSourceClusterHDFS: para conectar-se ao serviço HDFS de origem em seu projeto.AddTargetCluster: para conectar-se cluster do Amazon EMR de destino em seu projeto.AddTargetClusterS3: para adicionar o bucket do Amazon S3 ao seu projeto.AddTargetClusterHive: para conectar-se ao serviço Hive de destino em seu projetoAddTargetClusterHDFS: para conectar-se ao serviço HDFS de destino em seu projeto
Para obter exemplos de uso desses comandos da AWS SCT CLI, consulte. Como se conectar ao Apache Hadoop
Quando você executa o comando que se conecta a um cluster de origem ou de destino, AWS SCT tenta estabelecer a conexão com esse cluster. Se a tentativa de conexão falhar, AWS SCT interrompe a execução dos comandos do script da CLI e exibirá uma mensagem de erro.
Etapa 2: configurar as regras de mapeamento
Depois de se conectar aos clusters de origem e de destino, configure as regras de mapeamento. Uma regra de mapeamento define a meta de migração para um cluster de origem. Certifique-se de configurar regras de mapeamento para todos os clusters de origem que você adicionou ao seu AWS SCT projeto. Para obter mais informações sobre regras de mapeamento, consulte Mapear tipo de dados no AWS Schema Conversion Tool.
Para esta etapa, use o comando AddServerMapping. Esse comando usa dois parâmetros, que definem os clusters de origem e de destino. Você pode usar o comando AddServerMapping com o caminho explícito para seus objetos de banco de dados ou com nomes de objetos. Para a primeira opção, você inclui o tipo do objeto e seu nome. Para a segunda opção, você inclui somente os nomes dos objetos.
-
sourceTreePath: o caminho explícito para os objetos do banco de dados de origem.targetTreePath: o caminho explícito para os objetos do banco de dados de destino. -
sourceNamePath: o caminho que inclui somente os nomes dos seus objetos de origem.targetNamePath: o caminho que inclui somente os nomes dos seus objetos de destino.
O exemplo de código a seguir cria uma regra de mapeamento usando caminhos explícitos para o banco de dados Hive testdb de origem e o cluster EMR de destino.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Você pode usar esse exemplo e os exemplos a seguir no Windows. Para executar os comandos da CLI no Linux, verifique se você atualizou os caminhos de arquivo adequadamente para o seu sistema operacional.
O exemplo de código a seguir cria uma regra de mapeamento usando os caminhos que incluem somente os nomes dos objetos.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Você pode escolher o Amazon EMR ou o Amazon S3 como destino para seu objeto de origem. Para cada objeto de origem, você pode escolher somente um destino em um único AWS SCT projeto. Para alterar o destino de migração de um objeto de origem, exclua a regra de mapeamento existente e crie uma nova regra de mapeamento. Para excluir uma regra de mapeamento, use o comando DeleteServerMapping. Esse comando usa um dos dois parâmetros a seguir.
sourceTreePath: o caminho explícito para os objetos do banco de dados de origem.sourceNamePath: o caminho que inclui somente os nomes dos seus objetos de origem.
Para obter mais informações sobre os comandos AddServerMapping e DeleteServerMapping, consulte a Referência da CLI da AWS Schema Conversion Tool
Etapa 3: criar um relatório de avaliação
Antes de iniciar a migração, recomendamos criar um relatório de avaliação. Esse relatório resume todas as tarefas de migração e detalha os itens de ação que surgirão durante a migração. Para garantir que sua migração não falhe, visualize esse relatório e aborde os itens de ação antes da migração. Para obter mais informações, consulte Relatório de avaliação da .
Para esta etapa, use o comando CreateMigrationReport. Esse comando usa dois parâmetros. O parâmetrotreePath é obrigatório e o parâmetro forceMigrate é opcional.
treePath: o caminho explícito para os objetos do banco de dados de origem para os quais você salva uma cópia do relatório de avaliação.forceMigrate— quando definido comotrue, AWS SCT continua a migração mesmo que seu projeto inclua uma pasta HDFS e uma tabela do Hive que façam referência ao mesmo objeto. O valor padrão éfalse.
Você pode então salvar uma cópia do relatório de avaliação como um arquivo PDF ou arquivos de valores separados por vírgula (CSV). Para isso, use o comando SaveReportPDF ou SaveReportCSV.
O comando SaveReportPDF salva uma cópia do seu relatório de avaliação como um arquivo PDF. Esse comando usa quatro parâmetros. O parâmetro file é obrigatório, outros parâmetros são opcionais.
file: o caminho para o arquivo PDF e seu nome.filter: o nome do filtro que você criou antes para definir o escopo dos objetos de origem a serem migrados.treePath: o caminho explícito para os objetos do banco de dados de origem para os quais você salva uma cópia do relatório de avaliação.namePath: o caminho que inclui somente os nomes dos objetos de destino para os quais você salva uma cópia do relatório de avaliação.
O comando SaveReportCSV salva seu relatório de avaliação em três arquivos CSV. Esse comando usa quatro parâmetros. O parâmetro directory é obrigatório, outros parâmetros são opcionais.
directory— o caminho para a pasta em que os arquivos CSV são AWS SCT salvos.filter: o nome do filtro que você criou antes para definir o escopo dos objetos de origem a serem migrados.treePath: o caminho explícito para os objetos do banco de dados de origem para os quais você salva uma cópia do relatório de avaliação.namePath: o caminho que inclui somente os nomes dos objetos de destino para os quais você salva uma cópia do relatório de avaliação.
O exemplo de código a seguir salva uma cópia do seu relatório de avaliação no arquivo c:\sct\ar.pdf.
SaveReportPDF -file:'c:\sct\ar.pdf' /
O exemplo de código a seguir salva uma cópia do seu relatório de avaliação como arquivos CSV na pasta c:\sct.
SaveReportCSV -file:'c:\sct' /
Para obter mais informações sobre os comandos SaveReportPDF e SaveReportCSV, consulte a Referência da CLI da AWS Schema Conversion Tool
Etapa 4: Migre seu cluster Apache Hadoop para o Amazon EMR com AWS SCT
Depois de configurar seu AWS SCT projeto, inicie a migração do seu cluster Apache Hadoop local para o. Nuvem AWS
Para esta etapa, use os comandos Migrate, MigrationStatus e ResumeMigration.
O comando Migrate migra seus objetos de origem para o cluster de destino. Esse comando usa quatro parâmetros. Certifique-se de especificar o parâmetro filter ou treePath. Outros parâmetros são opcionais.
filter: o nome do filtro que você criou antes para definir o escopo dos objetos de origem a serem migrados.treePath: o caminho explícito para os objetos do banco de dados de origem para os quais você salva uma cópia do relatório de avaliação.forceLoad— quando definido comotrue, carrega AWS SCT automaticamente as árvores de metadados do banco de dados durante a migração. O valor padrão éfalse.forceMigrate— quando definido comotrue, AWS SCT continua a migração mesmo que seu projeto inclua uma pasta HDFS e uma tabela do Hive que façam referência ao mesmo objeto. O valor padrão éfalse.
O comando MigrationStatus retorna informações sobre o progresso da migração. Para executar esse comando, insira o nome do seu projeto de migração para o parâmetro name. Você especificou esse nome no comando CreateProject.
O comando ResumeMigration retoma a migração interrompida que você iniciou usando o comando Migrate. O comando ResumeMigration não usa parâmetros. Para continuar a migração, você deve se conectar aos clusters de origem e de destino. Para obter mais informações, consulte Como gerenciar projeto de migração.
O exemplo de código a seguir migra dados do seu serviço HDFS de origem para o Amazon EMR.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
Como executar seu script de CLI
Depois de terminar de editar seu script de AWS SCT CLI, salve-o como um arquivo com a .scts extensão. Agora, você pode executar seu script a partir da app pasta do caminho de AWS SCT instalação. Para fazer isso, use o comando a seguir.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
No exemplo anterior, script_path substitua pelo caminho do seu arquivo pelo script CLI. Para obter mais informações sobre a execução de scripts de CLI em AWS SCT, consulte. Modo de script
Como gerenciar projeto de migração de big data
Depois de concluir a migração, você pode salvar e editar seu AWS SCT projeto para uso futuro.
Para salvar seu AWS SCT projeto, use o SaveProject comando. Este comando não usa parâmetros.
O exemplo de código a seguir salva seu AWS SCT projeto.
SaveProject /
Para abrir seu AWS SCT projeto, use o OpenProject comando. Este comando usa um parâmetro obrigatório. Para o file parâmetro, insira o caminho para o arquivo do AWS SCT projeto e seu nome. Você especificou o nome do projeto no comando CreateProject. Certifique-se de adicionar a extensão .scts ao nome do arquivo do projeto para executar o comando OpenProject.
O exemplo de código a seguir cria o projeto do hadoop_emr a partir da pasta c:\sct.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
Depois de abrir seu AWS SCT projeto, você não precisa adicionar os clusters de origem e de destino porque você já os adicionou ao seu projeto. Para começar a trabalhar com seus clusters de origem e destino, você deve se conectar a eles. Para fazer isso, use os comandos ConnectSourceCluster e ConnectTargetCluster. Esses comandos usam os mesmos parâmetros dos comandos AddSourceCluster e AddTargetCluster. Você pode editar seu script de CLI e substituir o nome desses comandos, deixando a lista de parâmetros sem alterações.
O exemplo de código a seguir conecta o cluster do Hadoop de origem.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
O exemplo de código a seguir conecta o cluster do Amazon EMR de destino.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
No exemplo anterior, hadoop_address substitua pelo endereço IP do seu cluster Hadoop. Se necessário, configure o valor da variável de porta. Em seguida, substitua hadoop_user e hadoop_password pelo nome do seu usuário do Hadoop e a senha desse usuário. Parapath\name, insira o nome e o caminho para o arquivo PEM do seu cluster Hadoop de origem. Para obter mais informações sobre a inclusão dos clusters de origem e destino, consulte Conectando-se aos bancos de dados do Apache Hadoop com o AWS Schema Conversion Tool.
Depois de se conectar aos clusters do Hadoop de origem e de destino, você deve se conectar aos serviços Hive e HDFS, bem como ao bucket do Amazon S3. Para fazer isso, use os comandos ConnectSourceClusterHive, ConnectSourceClusterHdfs, ConnectTargetClusterHive, ConnectTargetClusterHdfs e ConnectTargetClusterS3. Esses comandos usam os mesmos parâmetros que você usou para adicionar serviços Hive e HDFS e o bucket Amazon S3 ao seu projeto. Edite o script de CLI para substituir o prefixo Add pelos nomes dos comandos Connect.
