Componentes principais do Amazon DynamoDB
No DynamoDB, tabelas, itens e atributos são os componentes principais com que você trabalha. Uma tabela é uma coleção de itens, e cada item é uma coleção de atributos. O DynamoDB utiliza chaves primárias para identificar de modo exclusivo cada item em uma tabela. Você pode usar o DynamoDB Streams para capturar eventos de modificação de dados em tabelas do DynamoDB.
No entanto, há limites no DynamoDB. Para obter mais informações, consulte Cotas no Amazon DynamoDB.
O vídeo a seguir apresenta uma introdução sobre tabelas globais, itens e atributos.
Tabelas, itens e atributos
Estes são os componentes básicos do DynamoDB:
-
Tabelas: semelhante a outros sistemas de banco de dados, o DynamoDB armazena dados em tabelas. Uma tabela é uma coleção de dados. Por exemplo, consulte a tabela de exemplo People que você pode usar para armazenar informações pessoais de contato de amigos, familiares ou qualquer outra pessoa de interesse. Você também poder ter uma tabela Cars para armazenar informações sobre os veículos que as pessoas dirigem.
-
Items: cada tabela contém zero ou mais itens. Um item é um grupo de atributos identificável exclusivamente entre todos os outros itens. Na tabela People de exemplo, cada item representa uma pessoa. Na tabela Cars, cada item representa um veículo. Os itens no DynamoDB são semelhantes de muitas formas a linhas, registros ou tuplas em outros sistemas de banco de dados. No DynamoDB, não há limite para o número de itens que você pode armazenar em uma tabela.
-
Atributos: cada item é composto por um ou mais atributos. Um atributo é um elemento de dados fundamental, algo que não precisa ser dividido ainda mais. Por exemplo, um item na tabela People contém os atributos PersonID, LastName, FirstName etc. Em uma tabela Department, um item pode ter atributos, como DepartmentID, Name, Manager etc. Os atributos no DynamoDB se parecem de várias maneiras com campos ou colunas em outros sistemas de banco de dados.
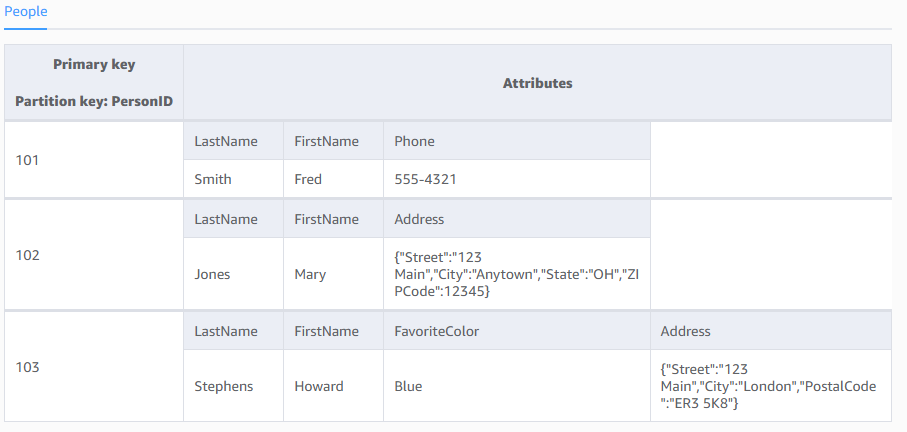
O diagrama a seguir mostra uma tabela People com alguns itens e atributos de exemplo.
People
{
"PersonID": 101,
"LastName": "Smith",
"FirstName": "Fred",
"Phone": "555-4321"
}
{
"PersonID": 102,
"LastName": "Jones",
"FirstName": "Mary",
"Address": {
"Street": "123 Main",
"City": "Anytown",
"State": "OH",
"ZIPCode": 12345
}
}
{
"PersonID": 103,
"LastName": "Stephens",
"FirstName": "Howard",
"Address": {
"Street": "123 Main",
"City": "London",
"PostalCode": "ER3 5K8"
},
"FavoriteColor": "Blue"
}Observe o seguinte sobre a tabela People:
-
Cada item da tabela tem um identificador exclusivo, ou chave primária, que o distingue de todos os outros na tabela. Na tabela People, a chave primária consiste em um único atributo (PersonID).
-
Além da chave primária, a tabela People não tem esquema, o que significa que não é necessário definir seus atributos e tipos de dados previamente. Cada item pode ter seus próprios atributos distintos.
-
A maioria dos atributos é escalar, o que significa que podem ter apenas um valor. Strings e números são exemplos comuns de escalares.
-
Alguns itens têm um atributo aninhado (Address). O DynamoDB oferece suporte a atributos aninhados com até 32 níveis de profundidade.
Veja a seguir outra tabela de exemplo chamada Music, que você pode usar para controlar sua coleção de músicas.
Music
{
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle": "Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
{
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle": "Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
{
"Artist": "The Acme Band",
"SongTitle": "Still in Love",
"AlbumTitle": "The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying": [
"KHCR",
"KQBX",
"WTNR",
"WJJH"
],
"TourDates": {
"Seattle": "20150622",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
{
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle": "The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
} Observe o seguinte sobre a tabela Music:
-
A chave primária da tabela Music é composta por dois atributos (Artist e SongTitle). Cada item da tabela deve ter esses dois atributos. A combinação de Artist e SongTitle distingue cada item da tabela de todos os outros.
-
Além da chave primária, a tabela Music não tem esquema, o que significa que nem os atributos nem seus tipos de dados precisam ser definidos previamente. Cada item pode ter seus próprios atributos distintos.
-
Um dos itens tem um atributo aninhado (PromotionInfo) que contém outros atributos aninhados. O DynamoDB oferece suporte a atributos aninhados com até 32 níveis de profundidade.
Para obter mais informações, consulte Trabalhar com tabelas e dados no DynamoDB.
Chave primária
Ao criar uma tabela, além do nome dela, você deve especificar a chave primária da tabela. A chave primária identifica exclusivamente cada item na tabela, de modo que não possa haver dois itens com a mesma chave.
O DynamoDB é compatível com dois tipos diferentes de chaves primárias:
-
Chave de partição: uma chave primária simples, formada por um atributo conhecido como a chave de partição.
O DynamoDB usa o valor da chave de partição como entrada para uma função de hash interna. A saída da função de hash determina a partição (armazenamento físico interno do DynamoDB) em que o item será armazenado.
Em uma tabela que possui somente uma chave de partição, dois itens não podem ter o mesmo valor de chave de partição.
A tabela People descrita em Tabelas, itens e atributos é um exemplo de uma tabela com uma chave primária simples (PersonID). Você pode acessar diretamente qualquer item na tabela People fornecendo o valor PersonId desse item.
-
Chave de partição e chave de classificação: conhecidas como chave primária composta, esse tipo de chave é formado por dois atributos. O primeiro atributo é a chave de partição, e o segundo atributo é a chave de classificação.
O DynamoDB usa o valor da chave de partição como entrada para uma função de hash interna. A saída da função de hash determina a partição (armazenamento físico interno do DynamoDB) em que o item será armazenado. Todos os itens com o mesmo valor de chave de partição são armazenados juntos, na ordem classificada por valor de chave de classificação.
Em uma tabela que tenha uma chave de partição e uma chave de classificação, vários itens podem ter o mesmo valor de chave de partição. No entanto, esses itens devem ter valores de chave de classificação diferentes.
A tabela Music descrita em Tabelas, itens e atributos é um exemplo de uma tabela com chave primária composta (Artist e SongTitle). Você poderá acessar diretamente qualquer item da tabela Music, se fornecer os valores Artist e SongTitle desse item.
Uma chave primária composta oferece flexibilidade adicional ao consultar dados. Por exemplo, se você fornecer somente o valor de Artist, o DynamoDB recuperará todas as músicas desse artista. Para recuperar apenas um subconjunto de músicas de um determinado artista, você pode fornecer um valor para Artist com um intervalo de valores de SongTitle.
nota
A chave de partição de um item também é conhecida como seu atributo de hash. O termo atributo de hash é derivado do uso de uma função de hash interna no DynamoDB que distribui uniformemente os itens de dados entre partições com base em seus valores de chave de partição.
A chave de classificação de um item também é conhecida como seu atributo de intervalo. O termo atributo de intervalo deriva da forma como o DynamoDB armazena itens fisicamente próximos com a mesma chave de partição, classificados em ordem de valor da chave de classificação.
Cada atributo de chave primária deve ser um escalar (o que significa que ele só pode conter um valor). Os únicos tipos de dados permitidos para atributos de chave primária são string, número ou binário. Essas restrições não existem para outros atributos não relacionados a chaves.
Índices secundários
É possível criar um ou mais índices secundários em uma tabela. Um índice secundário permite consultar os dados na tabela usando uma chave alternativa, além de consultas com base na chave primária. O DynamoDB não exige que você use índices, mas eles conferem às aplicações mais flexibilidade durante a consulta dos dados. Depois de criar um índice secundário em uma tabela, você pode ler os dados do índice da mesma maneira que faz na tabela.
O DynamoDB aceita dois tipos de índices:
-
Índice secundário global: um índice com uma chave de partição e uma chave de classificação que podem ser diferentes daquelas contidas na tabela. Os valores da chave primária em um índice secundário global não precisam ser exclusivos.
-
Índice secundário local: um índice que tem a mesma chave de partição que a tabela, mas uma chave de classificação diferente.
No DynamoDB, os índices secundários globais (GSIs) são índices que abrangem toda a tabela, permitindo que você faça consultas em todas as chaves de partição. Índices secundários locais (LSIs) são índices com a mesma chave de partição que a tabela base, mas uma chave de classificação diferente.
Cada tabela no DynamoDB tem uma cota de 20 índices secundários globais (cota padrão) e 5 índices secundários locais.
Na tabela Music de exemplo mostrada anteriormente, é possível consultar itens de dados por Artist (chave de partição) ou por Artist e SongTitle (chave de partição e chave de classificação). E se você também quiser consultar os dados por Genre e AlbumTitle? Para fazer isso, você pode criar um índice em Genre e AlbumTitle e, em seguida, consultar esse índice da mesma forma como consulta a tabela Music.
O diagrama a seguir mostra a tabela Music de exemplo, com um novo índice chamado GenreAlbumTitle. No índice, Genre é a chave de partição e AlbumTitle é a chave de classificação.
| Tabela de música | GenreAlbumTitle |
|---|---|
|
|
|
|
|
|
|
|
Observe o seguinte sobre o índice GenreAlbumTitle:
-
Cada índice pertence a uma tabela, que é chamada de tabela-base para o índice. No exemplo anterior, Music é a tabela-base do índice GenreAlbumTitle.
-
O DynamoDB mantém os índices automaticamente. Quando você adiciona, atualiza ou exclui um item na tabela-base, o DynamoDB adiciona, atualiza ou exclui o item correspondente em quaisquer índices que pertençam a essa tabela.
-
Ao criar um índice, você especifica quais atributos serão copiados, ou projetados, da tabela-base para o índice. No mínimo, o DynamoDB projeta os atributos de chave da tabela-base no índice. Este é o caso com
GenreAlbumTitle, em que somente os atributos de chave da tabelaMusicsão projetados no índice.
Você pode consultar o índice GenreAlbumTitle para localizar todos os álbuns de um gênero específico (por exemplo, todos os álbuns de Rock). Você também pode consultar o índice para localizar todos os álbuns de um gênero específico que tenham determinados títulos de álbum (por exemplo, todos os álbuns Country com títulos que começam com a letra H).
Para obter mais informações, consulte Melhorar o acesso aos dados com índices secundários no DynamoDB.
DynamoDB Streams
O DynamoDB Streams é um recurso opcional que captura eventos de modificação de dados em tabelas do DynamoDB. Os dados sobre esses eventos são exibidos no fluxo quase em tempo real e na ordem em que os eventos ocorreram.
Cada evento é representado por um registro de fluxo. Se você habilitar um fluxo em uma tabela, o DynamoDB Streams gravará um registro de fluxo sempre que um dos seguintes eventos ocorrer:
-
Um novo item é adicionado à tabela: o fluxo captura uma imagem de todo o item, inclusive todos os atributos.
-
Um item é atualizado: o fluxo captura as imagens “antes” e “depois” de todos os atributos que tenham sido modificados no item.
-
Um item é excluído da tabela: o fluxo captura uma imagem de todo o item antes de ter sido excluído.
Cada registro de fluxo também contém o nome da tabela, o carimbo de data/hora do evento e outros metadados. Registros de fluxo tem um tempo de vida de 24 horas; depois disso, eles são automaticamente removidos do fluxo.
Você pode usar o DynamoDB Streams junto com o AWS Lambda para criar um acionador, um código que é executado automaticamente sempre que um evento de interesse aparece em um fluxo. Por exemplo, considere uma tabela Customers que contém informações sobre os clientes de uma empresa. Suponhamos que você queira enviar um e-mail de “boas-vindas” a cada novo cliente. Você pode habilitar um fluxo nessa tabela e depois associá-lo a uma função do Lambda. A função do Lambda seria executada sempre que um novo registro de fluxo aparecesse, mas processaria somente os novos itens adicionados à tabela Customers. Para qualquer item que tenha um atributo EmailAddress, a função do Lambda invocaria o Amazon Simple Email Service (Amazon SES) para enviar um e-mail a esse endereço.
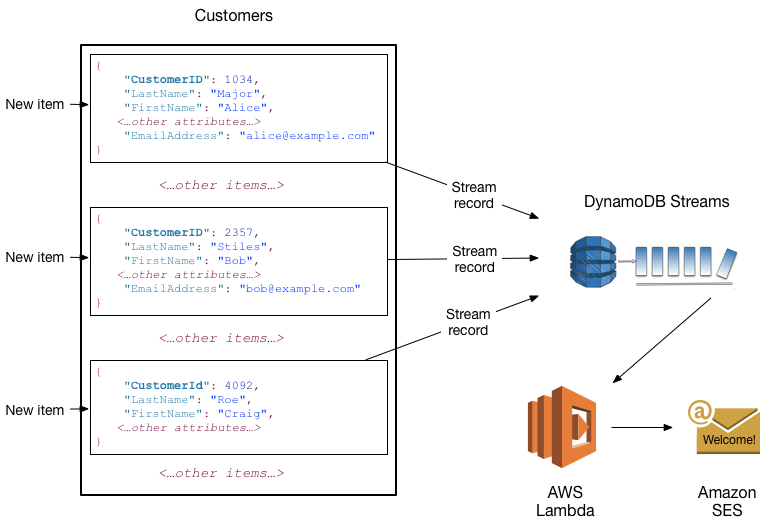
nota
Neste exemplo, o último cliente, Craig Roe, não receberá um e-mail, pois não tem um EmailAddress.
Além de acionadores, o DynamoDB Streams possibilita implementar soluções poderosas, como a replicação de dados dentro e entre regiões da AWS, visualizações materializadas de dados em tabelas do DynamoDB, análise de dados usando visualizações materializadas do Kinesis e muito mais.
Para obter mais informações, consulte Capturar dados de alterações para o DynamoDB Streams.
