Práticas recomendadas para usar chaves de classificação para organizar dados no DynamoDB
Em uma tabela do Amazon DynamoDB, a chave primária que identifica exclusivamente cada item na tabela pode ser composta de uma chave de partição e uma chave de classificação.
As chaves de classificação bem-projetadas tem dois principais benefícios:
Elas reúnem informações relacionadas em um só lugar para consulta eficiente. O design cuidadoso da chave de classificação permite recuperar grupos de itens relacionados comumente necessários, usando consultas de intervalo com operadores como
begins_with,between,>,<e assim por diante.-
Chaves de classificação compostas permitem definir os relacionamentos hierárquicos (um para muitos) entre os dados que podem ser consultados em qualquer nível da hierarquia.
Por exemplo, em uma tabela que lista as localizações geográficas, você pode estruturar a chave de classificação desta forma.
[country]#[region]#[state]#[county]#[city]#[neighborhood]Isso permite fazer consultas de intervalos eficientes de uma lista de localizações em qualquer um desses níveis de agregação, de
countryaneighborhoode tudo o que estiver nesse intervalo.
Usar chaves de classificação para controle de versões
Muitos aplicativos precisam manter um histórico de revisões no nível do item para fins de auditoria ou conformidade e para conseguir recuperar a versão mais recente com facilidade. Há um padrão de design eficiente que faz isso por meio do uso de prefixos de chave de classificação:
Para cada novo item, crie duas cópias do item: uma cópia deve ter um prefixo de número de versão zero (como
v0_) no início da chave de classificação, e a outra deve ter um prefixo de número de versão um (comov1_).Sempre que o item for atualizado, use o próximo prefixo de versão mais alto na chave de classificação da versão atualizada e copie o conteúdo atualizado para o item com o prefixo de versão zero. Isso significa que a versão mais recente de qualquer item pode ser localizada facilmente usando o prefixo zero.
Por exemplo, o fabricante de uma peça pode usar um esquema como esse ilustrado abaixo.
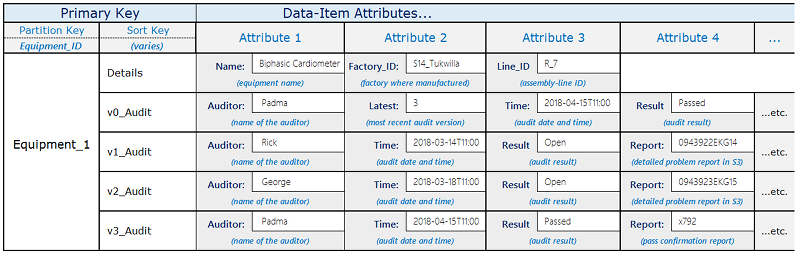
O item Equipment_1 passa por uma sequência de auditorias realizadas por vários auditores. Os resultados de cada nova auditoria são capturados em um novo item na tabela, começando com o número de versão um e depois incrementando o número para cada revisão sucessiva.
Quando cada nova revisão é adicionada, a camada do aplicativo substitui o conteúdo do item de versão zero (com chave de classificação igual a v0_Audit) com conteúdo da nova revisão.
Sempre que o aplicativo precisar recuperar para o status de auditoria mais recente, ele poderá consultar o prefixo da chave de classificação v0_.
Se o aplicativo precisar recuperar o histórico de revisão inteiro, poderá consultar todos os itens na chave de partição do item e filtrar o item v0_.
Esse design também funcionará para auditorias em várias peças de uma parte do equipamento, se você incluir IDs de peças individuais na chave de classificação após o prefixo de chave de classificação
