Design de esquema de rede social no DynamoDB
Caso de uso de negócios de redes sociais
Esse caso de uso aborda o uso do DynamoDB como uma rede social. Uma rede social é um serviço on-line que permite que diferentes usuários interajam entre si. A rede social que criaremos permitirá que o usuário veja uma linha do tempo que consiste em suas publicações, seguidores, quem ele está seguindo e publicações escritas por quem ele está seguindo. Os padrões de acesso para este design de esquema são:
-
Obter informações do usuário para determinado ID de usuário
-
Obter lista de seguidores para determinado ID de usuário
-
Obter lista de seguidores para determinado ID de usuário
-
Obter lista de seguidores para determinado ID de usuário
-
Obter a lista de usuários que curtiram a publicação de determinado PostID
-
Obter a contagem de curtidas para determinado PostID
-
Obter a linha do tempo de determinado ID de usuário
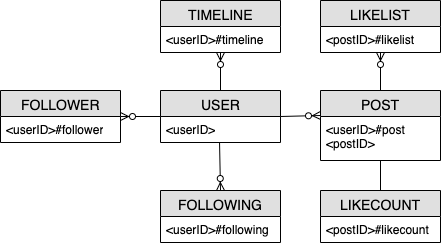
Diagrama de relacionamento de entidades de redes sociais
Este é o diagrama de relacionamento de entidades (ERD) que usaremos para o design do esquema da rede social.
Padrões de acesso da rede social
Estes são os padrões de acesso que vamos considerar para o design do esquema da rede social.
-
getUserInfoByUserID -
getFollowerListByUserID -
getFollowingListByUserID -
getPostListByUserID -
getUserLikesByPostID -
getLikeCountByPostID -
getTimelineByUserID
Evolução do design do esquema da rede social
O DynamoDB é um banco de dados NoSQL. Por isso, ele não permite que você realize uma união; isto é, uma operação que combina dados de vários bancos de dados. Os clientes que não estão familiarizados com o DynamoDB podem aplicar filosofias de design do sistema de gerenciamento de banco de dados relacional (RDBMS) (como criar uma tabela para cada entidade) ao DynamoDB quando na verdade não precisam. O objetivo do design de tabela única do DynamoDB é gravar dados em um formato pré-unido de acordo com o padrão de acesso da aplicação e, em seguida, usar imediatamente os dados sem computação adicional. Para obter mais informações, consulte Design de tabela única versus design de várias tabelas no DynamoDB
Agora vamos ver como desenvolveremos nosso design de esquema para abordar todos os padrões de acesso.
Etapa 1: abordar o padrão de acesso 1 (getUserInfoByUserID)
Para receber informações de um usuário específico, precisaremos usar Query na tabela base com uma condição de chave PK=<userID>. A operação de consulta permite paginar os resultados, o que pode ser útil quando um usuário tem muitos seguidores. Para obter mais informações sobre Query, consulte Consultar tabelas no DynamoDB.
Em nosso exemplo, rastreamos dois tipos de dados para nosso usuário: “count” e “info”. A “contagem” de um usuário reflete quantos seguidores ele tem, quantos usuários ele está seguindo e quantas publicações ele criou. As “informações” de um usuário refletem suas informações pessoais, como seu nome.
Vemos esses dois tipos de dados representados pelos dois itens abaixo. O item que tem “count” na chave de classificação (SK) tem maior probabilidade de mudar do que o item com “info”. O DynamoDB considera o tamanho do item conforme ele aparece antes e depois da atualização, e o throughput provisionado consumido refletirá o item de tamanho maior. Mesmo se você atualizar apenas um subconjunto dos atributos do item, UpdateItem ainda consumirá a quantidade total do throughput provisionado (o maior tamanho de item de “antes” e “depois”). Você pode obter os itens por meio de uma única operação Query e usar UpdateItem para adicionar ou subtrair atributos numéricos existentes.

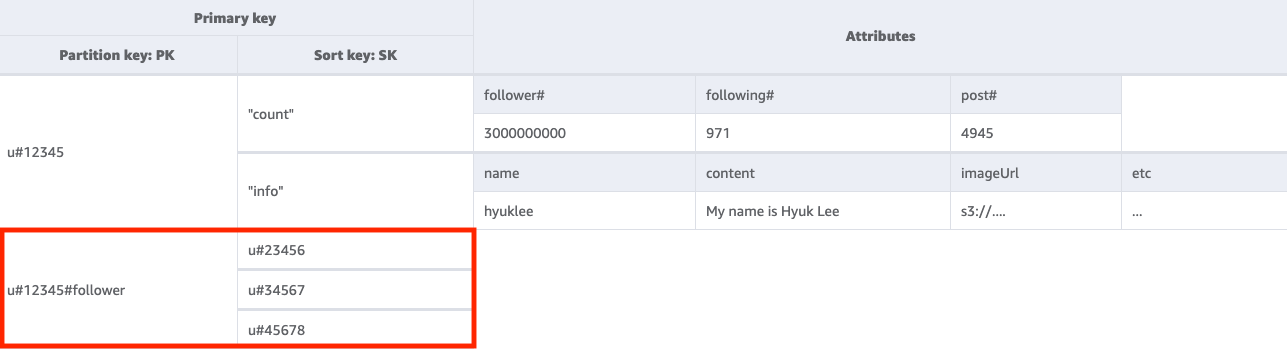
Etapa 2: abordar o padrão de acesso 2 (getFollowerListByUserID)
Para obter uma lista dos usuários que estão seguindo determinado usuário, precisaremos utilizar Query na tabela base com uma condição de chave PK=<userID>#follower.
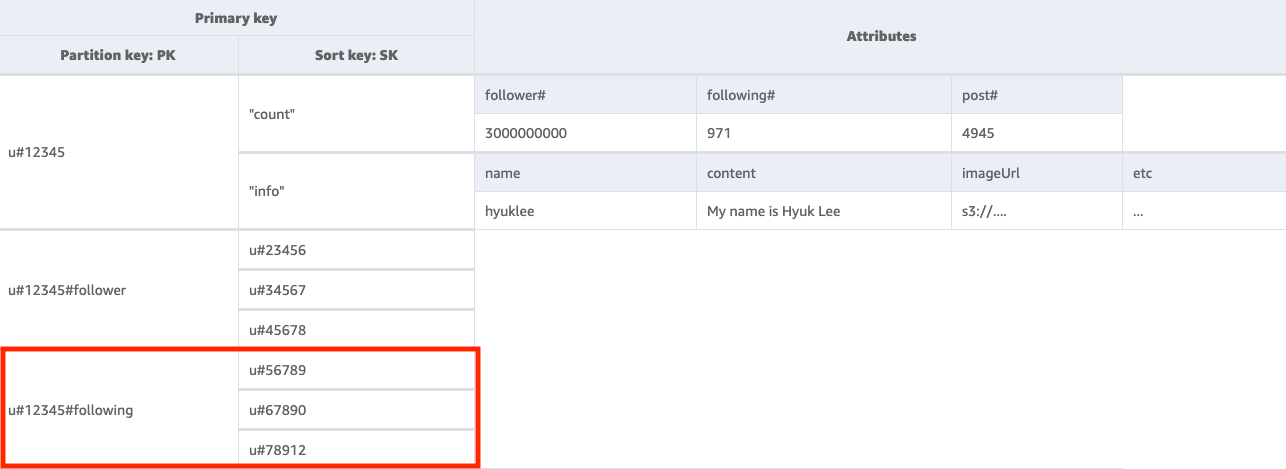
Etapa 3: abordar o padrão de acesso 3 (getFollowingListByUserID)
Para obter uma lista dos usuários que um usuário está seguindo, precisaremos utilizar Query na tabela base com uma condição de chave PK=<userID>#following. Depois, você pode usar uma operação TransactWriteItems para agrupar várias solicitações e fazer o seguinte:
-
Adicionar o usuário A à lista de seguidores do usuário B e, depois, incrementar a contagem de seguidores do usuário B em um.
-
Adicionar o usuário B à lista de seguidores do usuário A e, depois, incrementar a contagem de seguidores do usuário A em um.
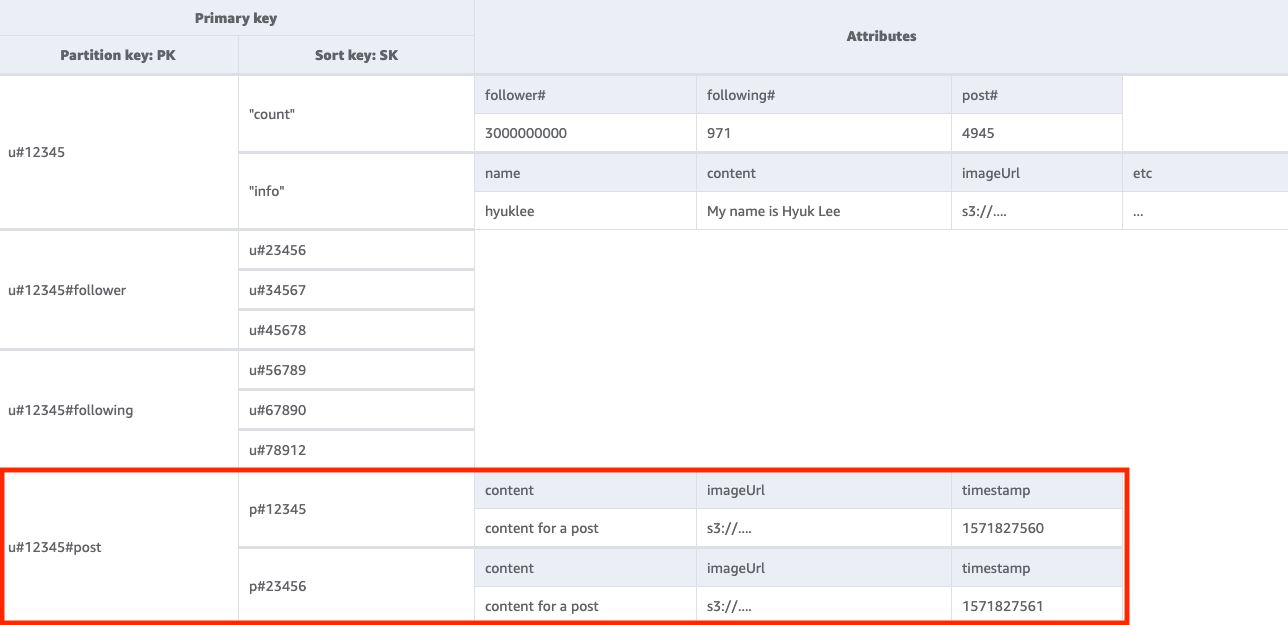
Etapa 4: abordar o padrão de acesso 4 (getPostListByUserID)
Para obter uma lista das publicações de determinado usuário, precisaremos utilizar Query na tabela base com uma condição de chave PK=<userID>#post. Um fator importante a observar aqui é que os postIDs de um usuário devem ser incrementais: o segundo valor postID deve ser maior que o primeiro valor postID (já que os usuários querem ver suas publicações de forma ordenada). Você pode fazer isso gerando PostIDs com base em um valor de tempo, como um identificador lexicograficamente classificável universalmente exclusivo (ULID).
Etapa 5: abordar o padrão de acesso 5 (getUserLikesByPostID)
Para obter uma lista dos usuários que curtiram a publicação de determinado usuário, precisaremos utilizar Query na tabela base com uma condição de chave PK=<postID>#likelist. Essa abordagem é o mesmo padrão que usamos para recuperar as listas de seguidores e seguidos nos padrões de acesso 2 (getFollowerListByUserID) e 3 (getFollowingListByUserID).
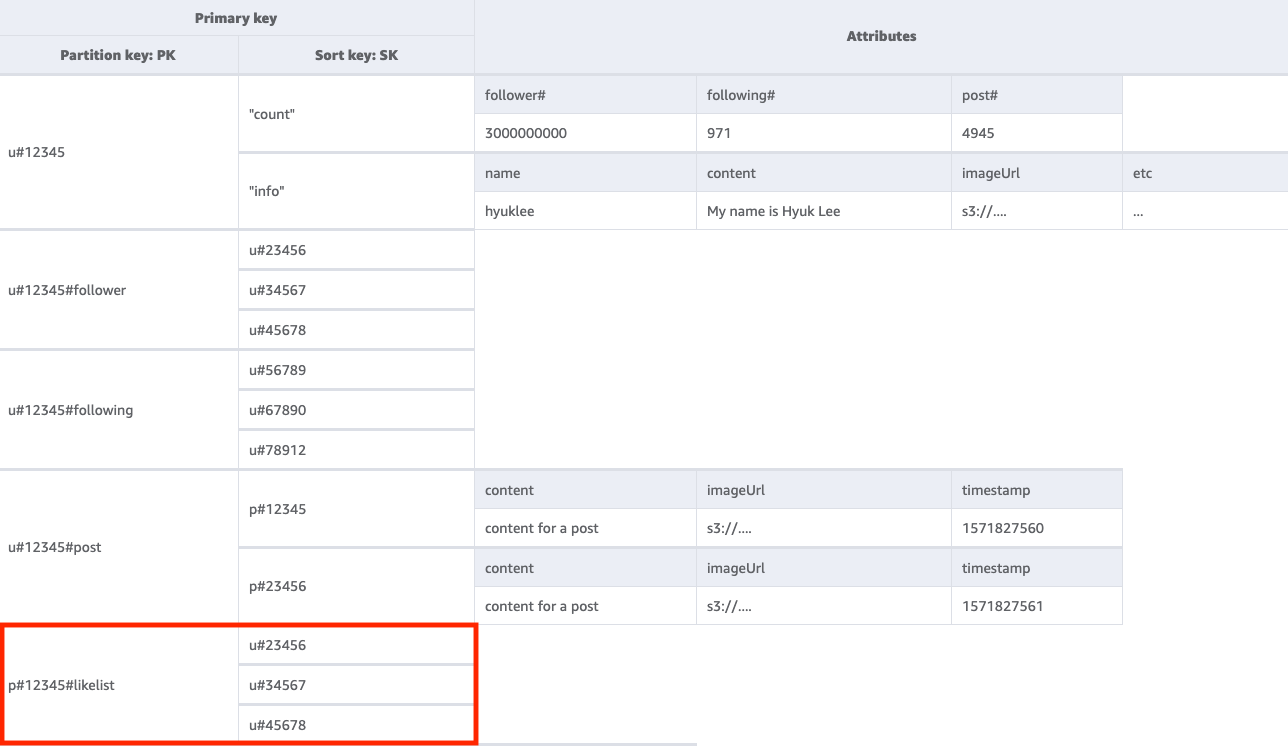
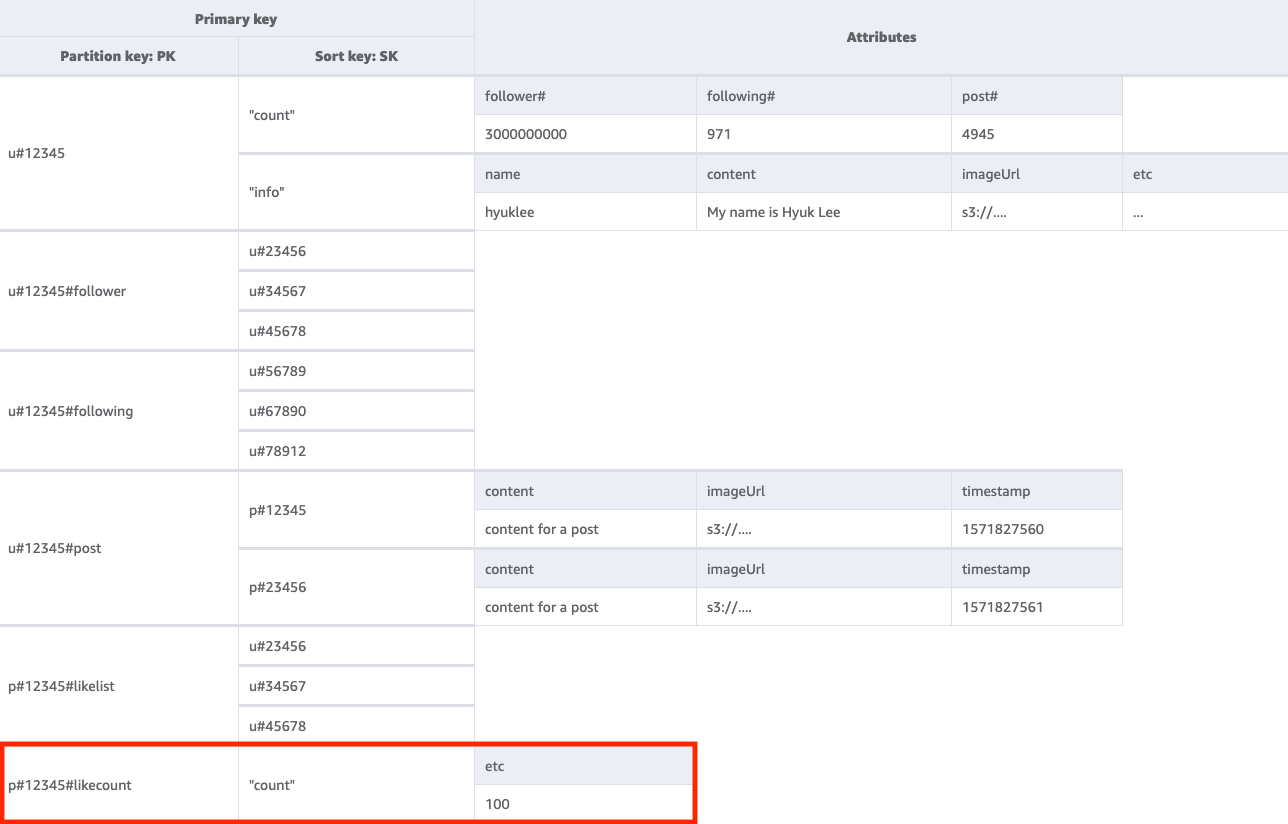
Etapa 6: abordar o padrão de acesso 6 (getLikeCountByPostID)
Para obter uma contagem de curtidas de determinada publicação, precisaremos realizar uma operação GetItem na tabela base com uma condição de chave PK=<postID>#likecount. Esse padrão de acesso pode causar problemas de controle de utilização sempre que um usuário com muitos seguidores (como uma celebridade) criar uma publicação, pois a limitação ocorre quando o throughput de uma partição excede 1.000 WCU por segundo. Esse problema não é provocado pelo DynamoDB. Ele só aparece no DynamoDB porque está no final da pilha de software.
Você deve avaliar se é realmente essencial que todos os usuários visualizem a contagem de curtidas simultaneamente ou se isso pode ocorrer gradualmente ao longo do tempo. Em geral, a contagem de curtidas de uma publicação não precisa ser 100% exata imediatamente. Você pode implementar essa estratégia colocando uma fila entre a aplicação e o DynamoDB para que as atualizações ocorram periodicamente.
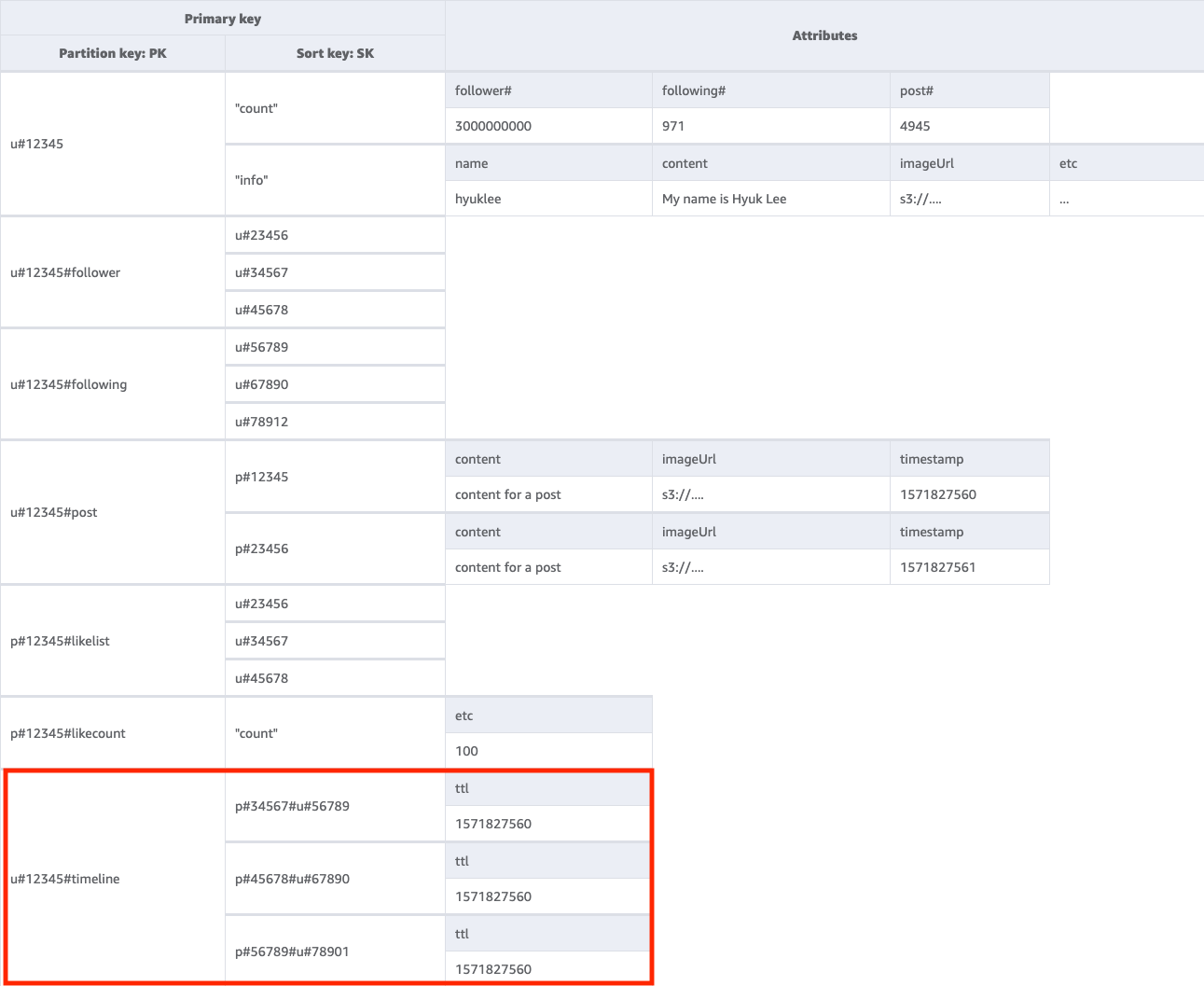
Etapa 7: abordar o padrão de acesso 7 (getTimelineByUserID)
Para obter a linha do tempo de determinado usuário, precisaremos realizar uma operação Query na tabela base com uma condição de chave PK=<userID>#timeline. Vamos considerar uma situação em que os seguidores de um usuário precisam ver a publicação dele de forma síncrona. Toda vez que um usuário escreve uma publicação, sua lista de seguidores é lida e seu ID de usuário e postID são inseridos lentamente na chave da linha do tempo de todos os respectivos seguidores. Em seguida, quando a aplicação for iniciada, você poderá ler a chave da linha do tempo com a operação Query e preencher a tela da linha do tempo com uma combinação de UserID e PostID usando a operação BatchGetItem para qualquer item novo. Não é possível ler a linha do tempo com uma chamada de API, mas essa é uma solução mais econômica se as publicações puderem ser editadas com frequência.
Como a linha do tempo é um local que mostra as publicações recentes, precisaremos de um meio para limpar as antigas. Em vez de usar WCU para excluí-las, você pode usar o atributo TTL do DynamoDB para fazer isso gratuitamente.
Todos os padrões de acesso e a forma como o design do esquema os aborda estão resumidos na tabela abaixo:
| Padrão de acesso | Tabela base/GSI/LSI | Operation | Valor da chave de partição | Valores de chave de classificação | Outras condições/filtros |
|---|---|---|---|---|---|
| getUserInfoByUserID | Tabela base | Consulta | PK=<userID> | ||
| getFollowerListByUserID | Tabela base | Consulta | PK=<userID>#follower | ||
| getFollowingListByUserID | Tabela base | Consulta | PK=<userID>#following | ||
| getPostListByUserID | Tabela base | Consulta | PK=<userID>#post | ||
| getUserLikesByPostID | Tabela base | Consulta | PK=<postID>#likelist | ||
| getLikeCountByPostID | Tabela base | GetItem | PK=<postID>#likecount | ||
| getTimelineByUserID | Tabela base | Consulta | PK=<userID>#timeline |
Esquema final da rede social
Veja aqui o design do esquema final. Para baixar esse design de esquema como arquivo JSON, consulte DynamoDB Examples
Tabela base:
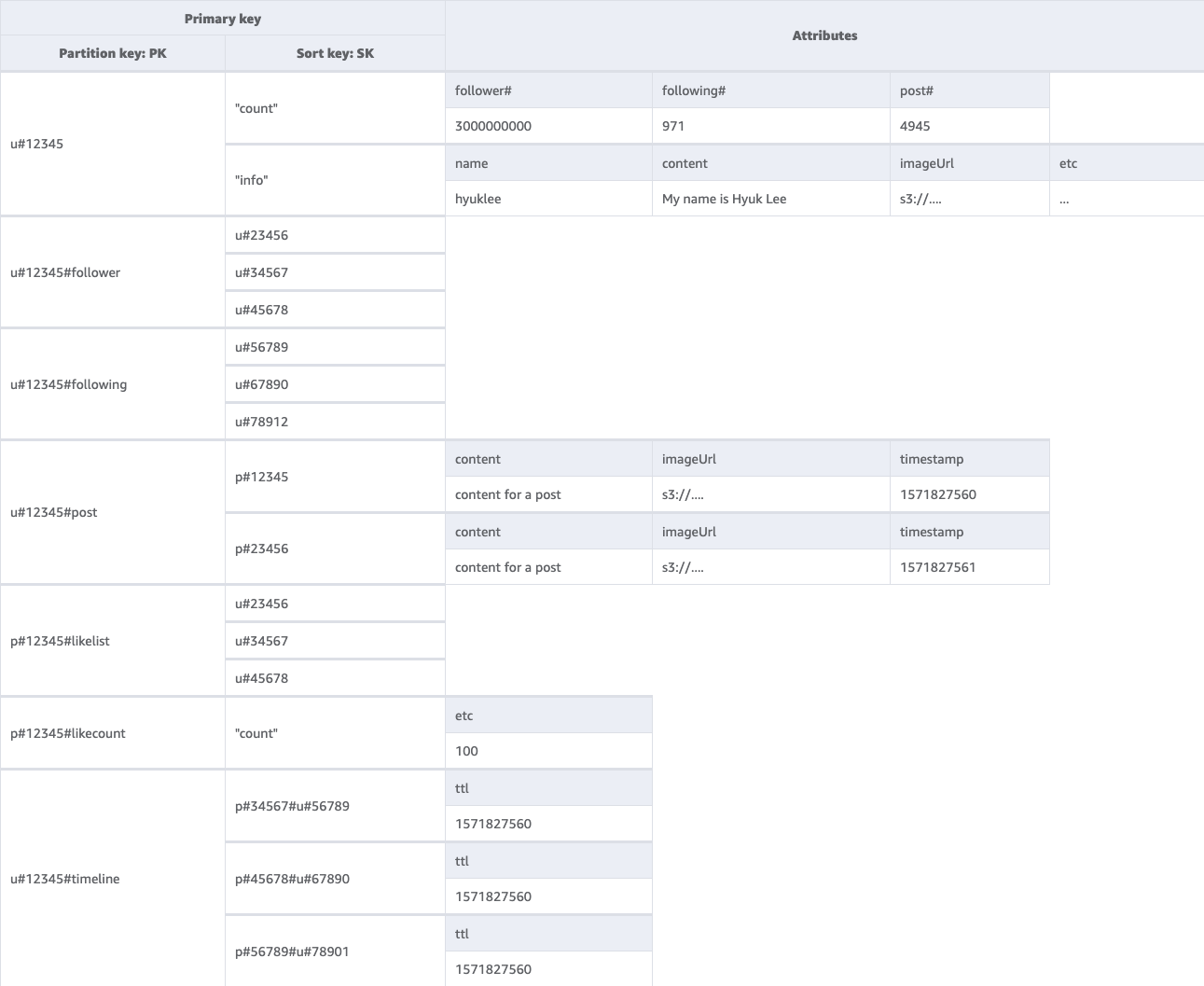
Como usar o NoSQL Workbench com esse design de esquema
Você pode importar esse esquema final para o NoSQL Workbench, uma ferramenta visual que fornece atributos de modelagem de dados, visualização de dados e desenvolvimento de consultas para o DynamoDB, se quiser explorar e editar ainda mais seu novo projeto. Para começar, siga estas etapas:
-
Baixe o NoSQL Workbench. Para obter mais informações, consulte Baixar o NoSQL Workbench para DynamoDB.
-
Baixe o arquivo do esquema JSON listado acima, que já está no formato do modelo NoSQL Workbench.
-
Importe o arquivo do esquema JSON para o NoSQL Workbench. Para obter mais informações, consulte Importar um modelo de dados existente.
-
Depois de importar para o NOSQL Workbench, você pode editar o modelo de dados. Para obter mais informações, consulte Editar um modelo de dados existente.
