As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Fontes de dados
Na seção anterior, aprendemos que um esquema define a forma dos seus dados. No entanto, não explicamos de onde vieram esses dados. Em projetos reais, seu esquema é como um gateway que manipula todas as solicitações feitas ao servidor. Quando uma solicitação é feita, o esquema atua como o único endpoint que interage com o cliente. O esquema acessa, processa e retransmite dados da fonte de dados para o cliente. Veja o infográfico abaixo:
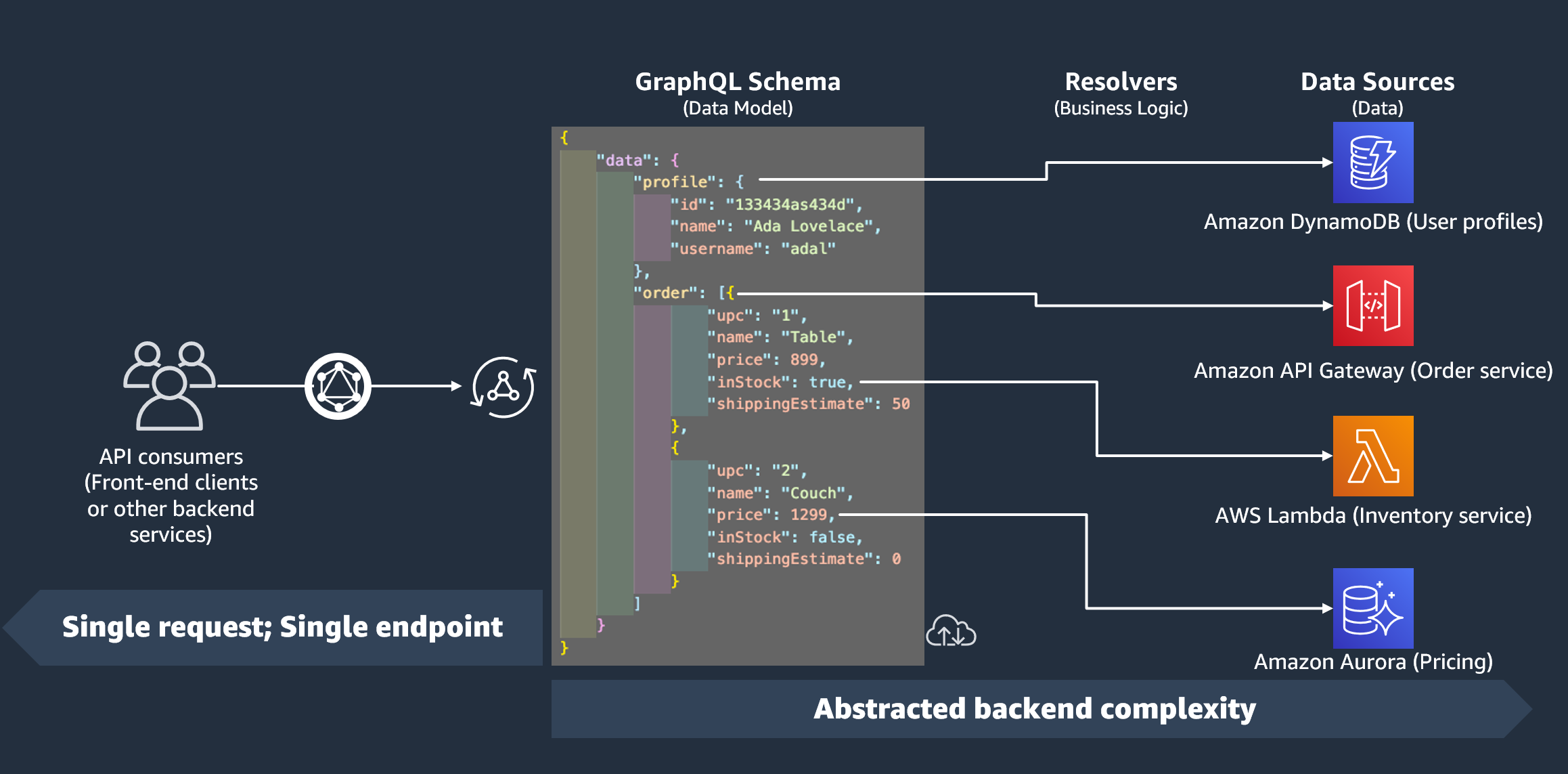
AWS AppSync e o GraphQL implementam de forma excelente as soluções Backend For Frontend (BFF). Eles trabalham em conjunto para reduzir a complexidade em grande escala ao abstrair o back-end. Caso seu serviço use fontes de dados e/ou microsserviços diferentes, você pode basicamente abstrair parte da complexidade definindo a forma dos dados de cada fonte (subgráfico) em um único esquema (supergráfico). Isso significa que sua API GraphQL não precisa usar uma única fonte de dados. Você pode associar qualquer número de fontes de dados à sua API GraphQL e especificar no seu código como elas interagirão com o serviço.
Como você pode ver no infográfico, o esquema do GraphQL contém todas as informações que os clientes precisam para solicitar dados. Isso significa que tudo pode ser processado em uma única solicitação, em vez de várias solicitações, como é o caso do REST. Essas solicitações passam pelo esquema, que é o único endpoint do serviço. Quando as solicitações são processadas, um resolvedor (explicado na próxima seção) executa seu código para processar os dados da fonte de dados relevante. Quando a resposta for retornada, o subgráfico vinculado à fonte de dados será preenchido com os dados no esquema.
AWS AppSync oferece suporte a vários tipos diferentes de fontes de dados. Na tabela abaixo, descreveremos cada tipo, listaremos alguns dos benefícios de cada um e forneceremos links úteis que trazem mais contexto.
| Fonte de dados | Description | Benefícios | Informações complementares |
|---|---|---|---|
| Amazon DynamoDB | “O Amazon DynamoDB é um serviço de banco de dados NoSQL totalmente gerenciado que fornece uma performance rápida e previsível com escalabilidade integrada. O DynamoDB permite que você transfira os encargos administrativos de operação e escalabilidade de um banco de dados distribuído. Assim, você não precisa se preocupar com provisionamento, instalação e configuração de hardware, replicação, correção de software nem escalabilidade de cluster. Além disso, o DynamoDB oferece criptografia em repouso, o que elimina a carga e a complexidade operacionais envolvidas na proteção de dados confidenciais.” |
|
|
| AWS Lambda | “AWS Lambda é um serviço de computação que permite executar código sem provisionar ou gerenciar servidores. O Lambda executa seu código em uma infraestrutura de computação de alta disponibilidade e executa toda a administração dos recursos computacionais, incluindo manutenção do servidor e do sistema operacional, provisionamento e escalabilidade automática da capacidade e registro em log do código. Com o Lambda, tudo o que você precisa fazer é fornecer seu código em um dos runtimes de linguagens compatíveis com o Lambda.” |
|
|
| OpenSearch | “O Amazon OpenSearch Service é um serviço gerenciado que facilita a implantação, a operação e a escalabilidade de OpenSearch clusters na AWS nuvem. O Amazon OpenSearch Service suporta OpenSearch e lega o Elasticsearch OSS (até a versão 7.10, a versão final de código aberto do software). Ao criar um cluster, você tem a opção de escolher qual mecanismo de pesquisa deseja usar. OpenSearché um mecanismo de pesquisa e análise totalmente de código aberto para casos de uso como análise de registros, monitoramento de aplicativos em tempo real e análise de fluxo de cliques. Para obter mais informações, consulte a documentação do OpenSearch O Amazon OpenSearch Service provisiona todos os recursos do seu OpenSearch cluster e o executa. Ele também detecta e substitui automaticamente os nós de OpenSearch serviço com falha, reduzindo a sobrecarga associada às infraestruturas autogerenciadas. Você pode escalar seu cluster com uma única chamada de API ou alguns cliques no console.” |
|
|
| Endpoints de HTTP | Você pode usar endpoints HTTP como fontes de dados. AWS AppSync pode enviar solicitações aos endpoints com as informações relevantes, como parâmetros e carga útil. A resposta HTTP será exposta ao resolvedor, que retornará a resposta final após concluir suas operações. |
|
|
| Amazon EventBridge | “EventBridge é um serviço sem servidor que usa eventos para conectar componentes do aplicativo, facilitando a criação de aplicativos escaláveis orientados por eventos. Use-o para rotear eventos de fontes como aplicativos, AWS serviços e software de terceiros desenvolvidos internamente para aplicativos de consumo em toda a sua organização. EventBridge fornece uma maneira simples e consistente de ingerir, filtrar, transformar e entregar eventos para que você possa criar novos aplicativos rapidamente.” |
|
|
| Bancos de dados relacionais | “O Amazon Relational Database Service (Amazon RDS) é um serviço web que facilita a configuração, a operação e a escalabilidade de um banco de dados relacional na nuvem. AWS Ele fornece capacidade econômica e redimensionável para um banco de dados relacional padrão do setor e gerencia tarefas comuns de administração de banco de dados. |
|
|
| Fonte de dados none | Se você não pretende usar uma fonte de dados, pode defini-la como none. Uma fonte de dados none, embora ainda seja explicitamente categorizada como fonte de dados, não é um meio de armazenamento. Apesar disso, ela ainda é útil em algumas instâncias para manipulação e passagem de dados. |
|
dica
Para obter mais informações sobre como as fontes de dados interagem AWS AppSync, consulte Anexando uma fonte de dados.
