Conector do Amazon Athena para o Vertica
O Vertica é uma plataforma de banco de dados em colunas que pode ser implantada na nuvem ou on-premises e que oferece suporte a data warehouses em escala de exabytes. Você pode usar o conector do Vertica para Amazon Athena em consultas federadas para consultar origens de dados do Vertica usando o Athena. Por exemplo, você pode executar consultas analíticas em um data warehouse no Vertica e um data lake no Amazon S3.
Pré-requisitos
Implante o conector na sua Conta da AWS usando o console do Athena ou o AWS Serverless Application Repository. Para obter mais informações, consulte Implantação de um conector de fonte de dados ou Usar o AWS Serverless Application Repository para implantar um conector de fonte de dados.
Configura uma VPC e um grupo de segurança antes de usar esse conector. Para ter mais informações, consulte Criar uma VPC para um conector de fonte de dados.
Limitações
-
Como o conector Vertica do Athena lê arquivos exportados Parquet do Amazon S3, o desempenho do conector pode ser lento. Ao consultar tabelas grandes, recomendamos usar uma consulta CREATE TABLE AS (SELECT ...) e predicados de SQL.
-
Atualmente, devido a um problema conhecido na consulta federada do Athena, o conector faz com que o Vertica exporte todas as colunas da tabela consultada para o Amazon S3, mas somente as colunas consultadas estão visíveis nos resultados no console do Athena.
-
Não há suporte para operações de gravação de DDL.
-
Quaisquer limites relevantes do Lambda. Para obter mais informações, consulte Cotas do Lambda no Guia do desenvolvedor do AWS Lambda.
Fluxo de trabalho
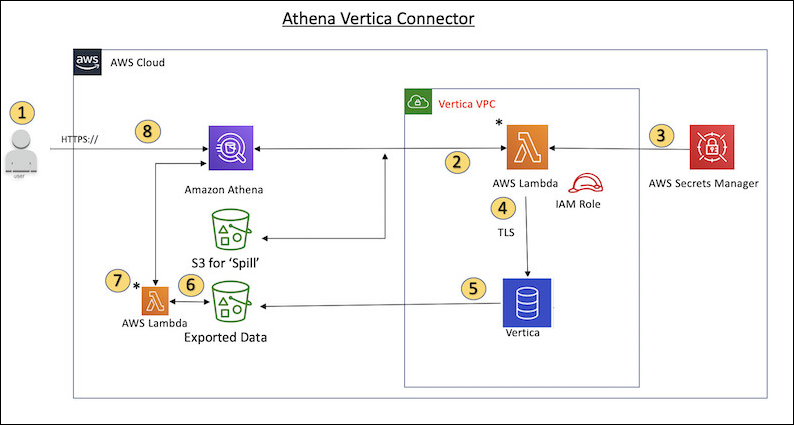
O diagrama a seguir mostra o fluxo de trabalho de uma consulta que use o conector Vertica.
-
Uma consulta SQL é emitida em uma ou mais tabelas no Vertica.
-
O conector analisa a consulta SQL para enviar a parte relevante para o Vertica por meio da conexão do JDBC.
-
As strings de conexão usam o nome de usuário e a senha armazenados no AWS Secrets Manager para obter acesso ao Vertica.
-
O conector envolve a consulta SQL com um comando
EXPORTdo Vertica, como no exemplo a seguir.EXPORT TO PARQUET (directory = 's3://amzn-s3-demo-bucket/folder_name, Compression='Snappy', fileSizeMB=64) OVER() as SELECT PATH_ID, ... SOURCE_ITEMIZED, SOURCE_OVERRIDE FROM DELETED_OBJECT_SCHEMA.FORM_USAGE_DATA WHERE PATH_ID <= 5; -
O Vertica processa a consulta SQL e envia o conjunto de resultados para um bucket do Amazon S3. Para uma melhor throughput, o Vertica usa a opção
EXPORTpara paralelizar a operação de gravação de vários arquivos Parquet. -
O Athena examina o bucket do Amazon S3 para determinar o número de arquivos a serem lidos para o conjunto de resultados.
-
O Athena faz várias chamadas para a função do Lambda e usa o Apache
ArrowReaderpara ler os arquivos Parquet do conjunto de resultados. Várias chamadas permitem que o Athena paralelize a leitura dos arquivos do Amazon S3 e alcance uma throughput de até 100 GB por segundo. -
O Athena processa os dados retornados do Vertica com dados examinados do data lake e retorna o resultado.
Termos
Os termos a seguir estão relacionados ao conector Vertica.
-
Instância do banco de dados: qualquer instância de um banco de dados Vertica implantado no Amazon EC2.
-
Manipulador: um manipulador Lambda que acessa sua instância de banco de dados. Um manipulador pode ser para metadados ou para registros de dados.
-
Manipulador de metadados: um manipulador Lambda que recupera metadados da sua instância de banco de dados.
-
Manipulador de registros: um manipulador Lambda que recupera registros de dados da sua instância de banco de dados.
-
Manipulador composto: um manipulador Lambda que recupera tanto metadados quanto registros de dados da sua instância de banco de dados.
-
Propriedade ou parâmetro: uma propriedade do banco de dados usada pelos manipuladores para extrair informações do banco de dados. Você configura essas propriedades como variáveis de ambiente do Lambda.
-
String de conexão: uma string de texto usada para estabelecer uma conexão com uma instância de banco de dados.
-
Catálogo: um catálogo não AWS Glue registrado no Athena que é um prefixo obrigatório para a propriedade
connection_string.
Parâmetros
O conector do Amazon Athena para o Vertica expõe as opções de configuração por meio das variáveis de ambiente do Lambda. É possível usar as seguintes variáveis de ambiente do Lambda para definir o conector.
-
AthenaCatalogName: nome da função do Lambda
-
ExportBucket: o bucket do Amazon S3 para onde os resultados de consultas do Vertica são exportados.
-
SpillBucket: o nome do bucket do Amazon S3 no qual essa função pode derramar dados.
-
SpillPrefix: o prefixo para a localização do
SpillBucketonde essa função pode derramar dados. -
SecurityGroupIds: um ou mais IDs que correspondem ao grupo de segurança que deve ser aplicado à função do Lambda (por exemplo,
sg1,sg2ousg3). -
SubnetIds: uma ou mais IDs de sub-rede que correspondem à sub-rede que a função do Lambda pode usar para acessar sua fonte de dados (por exemplo,
subnet1ousubnet2). -
SecretNameOrPrefix: o nome ou prefixo de um conjunto de nomes no Secrets Manager ao qual essa função tem acesso (por exemplo,
vertica-*) -
VerticaConnectionString: os detalhes da conexão do Vertica a serem usados por padrão se nenhuma conexão específica do catálogo for definida. A string pode opcionalmente usar a sintaxe do AWS Secrets Manager (por exemplo,
${secret_name}). -
VPC ID: o ID da VPC a ser associada à função do Lambda.
String de conexão
Use uma string de conexão JDBC no seguinte formato para se conectar a uma instância de banco de dados.
vertica://jdbc:vertica://host_name:port/database?user=vertica-username&password=vertica-password
Uso de um único manipulador de conexão
É possível usar os seguintes metadados de conexão única e manipuladores de registros para se conectar a uma única instância do Vertica.
| Tipo de manipulador | Classe |
|---|---|
| Manipulador composto | VerticaCompositeHandler |
| Manipulador de metadados | VerticaMetadataHandler |
| Manipulador de registros | VerticaRecordHandler |
Parâmetros do manipulador de conexão única
| Parâmetro | Descrição |
|---|---|
default |
Obrigatório. A string de conexão padrão. |
Os manipuladores de conexão únicos oferecem suporte a uma instância de banco de dados e devem fornecer um parâmetro de string de conexão default. Todas as outras strings de conexão são ignoradas.
Fornecimento de credenciais
Para fornecer um nome de usuário e uma senha para seu banco de dados na string de conexão JDBC, é possível usar as propriedades da string de conexão ou o AWS Secrets Manager.
-
String de conexão: um nome de usuário e uma senha podem ser especificados como propriedades na string de conexão do JDBC.
Importante
Como prática recomendada de segurança, não use credenciais codificadas em suas variáveis de ambiente ou strings de conexão. Para obter informações sobre como mover seus segredos codificados para o AWS Secrets Manager, consulte Mover segredos codificados para o AWS Secrets Manager no Guia do usuário do AWS Secrets Manager.
-
AWS Secrets Manager: para usar o recurso Athena Federated Query com o AWS Secrets Manager, a VPC conectada à sua função do Lambda deve ter acesso à Internet
ou um endpoint da VPC para se conectar ao Secrets Manager. É possível colocar o nome de um segredo no AWS Secrets Manager na sua string de conexão JDBC. O conector substitui o nome secreto pelos valores de
usernameepassworddo Secrets Manager.Para instâncias de banco de dados do Amazon RDS, esse suporte é totalmente integrado. Se você usa o Amazon RDS, é altamente recomendável usar o AWS Secrets Manager e rotação de credenciais. Se seu banco de dados não usar o Amazon RDS, armazene as credenciais em JSON no seguinte formato:
{"username": "${username}", "password": "${password}"}
Exemplo de string de conexão com nomes secretos
A string a seguir tem os nomes secretos ${vertica-username} e ${vertica-password}.
vertica://jdbc:vertica://host_name:port/database?user=${vertica-username}&password=${vertica-password}
O conector usa o nome secreto para recuperar segredos e fornecer o nome de usuário e a senha, como no exemplo a seguir.
vertica://jdbc:vertica://host_name:port/database?user=sample-user&password=sample-password
Atualmente, o conector Vertica reconhece as propriedades vertica-username e vertica-password do JDBC.
Parâmetros de derramamento
O SDK do Lambda pode derramar dados no Amazon S3. Todas as instâncias do banco de dados acessadas pela mesma função do Lambda derramam no mesmo local.
| Parâmetro | Descrição |
|---|---|
spill_bucket |
Obrigatório. Nome do bucket de derramamento. |
spill_prefix |
Obrigatório. Prefixo de chave do bucket de derramamento. |
spill_put_request_headers |
(Opcional) Um mapa codificado em JSON de cabeçalhos e valores de solicitações para a solicitação putObject do Amazon S3 usada para o derramamento (por exemplo, {"x-amz-server-side-encryption" :
"AES256"}). Para outros cabeçalhos possíveis, consulte PutObject na Referência da API do Amazon Simple Storage Service. |
Suporte ao tipo de dados
A tabela a seguir mostra os tipos de dados com suporte pelo conector Vertica.
| Booleano |
|---|
| BigInt |
| Short |
| Inteiro |
| Longo |
| Float |
| Double |
| Data |
| Varchar |
| Bytes |
| BigDecimal |
| TimeStamp como Varchar |
Performance
A função do Lambda realiza o empilhamento de projeções para diminuir os dados verificados pela consulta. As cláusulas LIMIT reduzem a quantidade de dados verificados, mas se você não fornecer um predicado, deverá aguardar que as consultas SELECT com uma cláusula LIMIT verifiquem, no mínimo, 16 MB de dados. O conector Vertica é resiliente ao controle de utilização devido à simultaneidade.
Consultas de passagem
O conector Vertica é compatível com consultas de passagem. As consultas de passagem usam uma função de tabela para enviar sua consulta completa para execução na fonte de dados.
Para usar consultas de passagem com o Vertica, você pode empregar a seguinte sintaxe:
SELECT * FROM TABLE( system.query( query => 'query string' ))
O exemplo de consulta a seguir envia uma consulta para uma fonte de dados no Vertica. A consulta seleciona todas as colunas na tabela customer, limitando os resultados a 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
Informações de licença
Ao usar esse conector, você reconhece a inclusão de componentes de terceiros, cuja lista pode ser encontrada no arquivo pom.xml
Recursos adicionais
Para obter as informações mais recentes sobre a versão do driver JDBC, consulte o arquivo pom.xml
Para obter mais informações sobre esse conector, consulte o site correspondente
