As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Fazendo upload de arquivos pela primeira vez
Você pode usar o recurso de Cadeia de Suprimentos AWS associação automática para carregar seus dados brutos e associar automaticamente seus dados brutos ao modelo de Cadeia de Suprimentos AWS dados. Você também pode visualizar as colunas e tabelas necessárias para cada Cadeia de Suprimentos AWS módulo no aplicativo Cadeia de Suprimentos AWS web.
Para uma breve demonstração de como a associação automática funciona, assista ao vídeo a seguir:
nota
Você só pode fazer upload de CSV arquivos para o Amazon S3 quando estiver usando a associação automática.
Depois que as colunas de origem do seu conjunto de dados forem associadas às colunas de destino, a SQL receita Cadeia de Suprimentos AWS será gerada automaticamente.
nota
Cadeia de Suprimentos AWS usa o Amazon Bedrock para associação automática, que não é compatível com todas as AWS regiões e regiões em que Cadeia de Suprimentos AWS está disponível. Portanto, Cadeia de Suprimentos AWS chamará o endpoint Amazon Bedrock da região disponível mais próxima, região da Europa (Irlanda) — Europa (Frankfurt) e região Ásia-Pacífico (Sydney) — Oeste dos EUA (Oregon).
nota
A associação automática usando Large Language Models (LLM) só é suportada quando os dados são ingeridos por meio do Amazon S3.
-
No Cadeia de Suprimentos AWS painel, no painel de navegação esquerdo, escolha Data Lake e, em seguida, escolha a guia Ingestão de dados.
A página de ingestão de dados é exibida.
Escolha Adicionar nova fonte.
A página Selecione sua fonte de dados é exibida.
Na página Selecione sua fonte de dados, escolha Carregar arquivos.
Escolha Continuar.
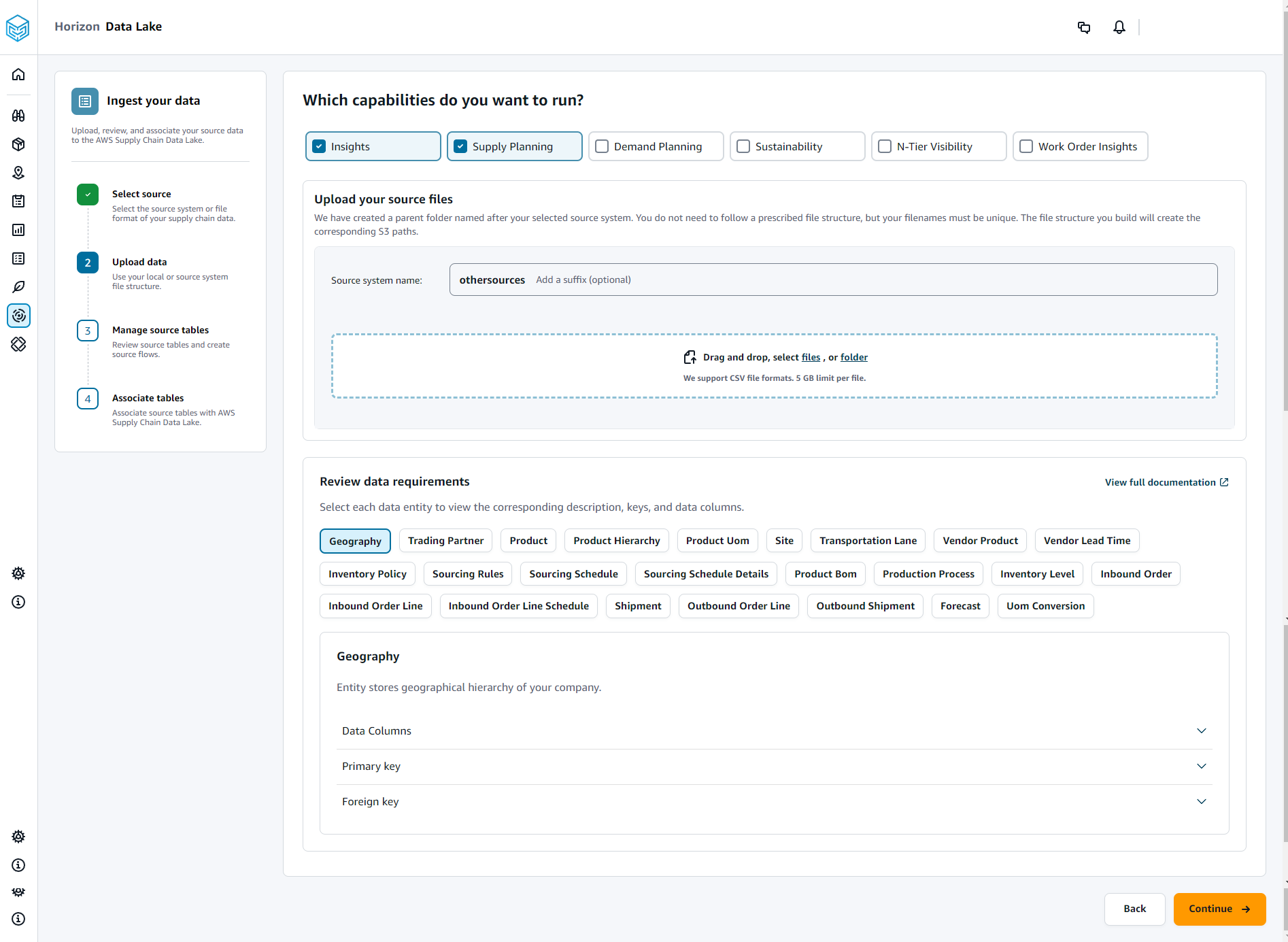
Na página Quais recursos você deseja executar, escolha os Cadeia de Suprimentos AWS módulos que você deseja usar. Você pode escolher mais de um módulo.
Na seção Carregar seus arquivos de origem, adicione um sufixo ao nome do sistema de origem. Por exemplo, oracle_test.
Para fazer o upload do conjunto de dados de origem, escolha arquivos ou arraste e solte arquivos.
As tabelas de origem com o nome e o status são exibidas.
Escolha Carregar para o S3. O status do upload será alterado para exibir o status.
Em Revisar requisitos de dados, revise todas as entidades e colunas de dados necessárias para o Cadeia de Suprimentos AWS recurso selecionado. Todas as chaves primárias e estrangeiras necessárias são exibidas.
Escolha Continuar.
Em Gerenciar suas tabelas de origem, as seguintes tabelas de origem e as colunas listadas serão associadas automaticamente e importadas para o data lake.
Escolha Excluir tabela para excluir qualquer uma das tabelas de origem antes de importar para o data lake.
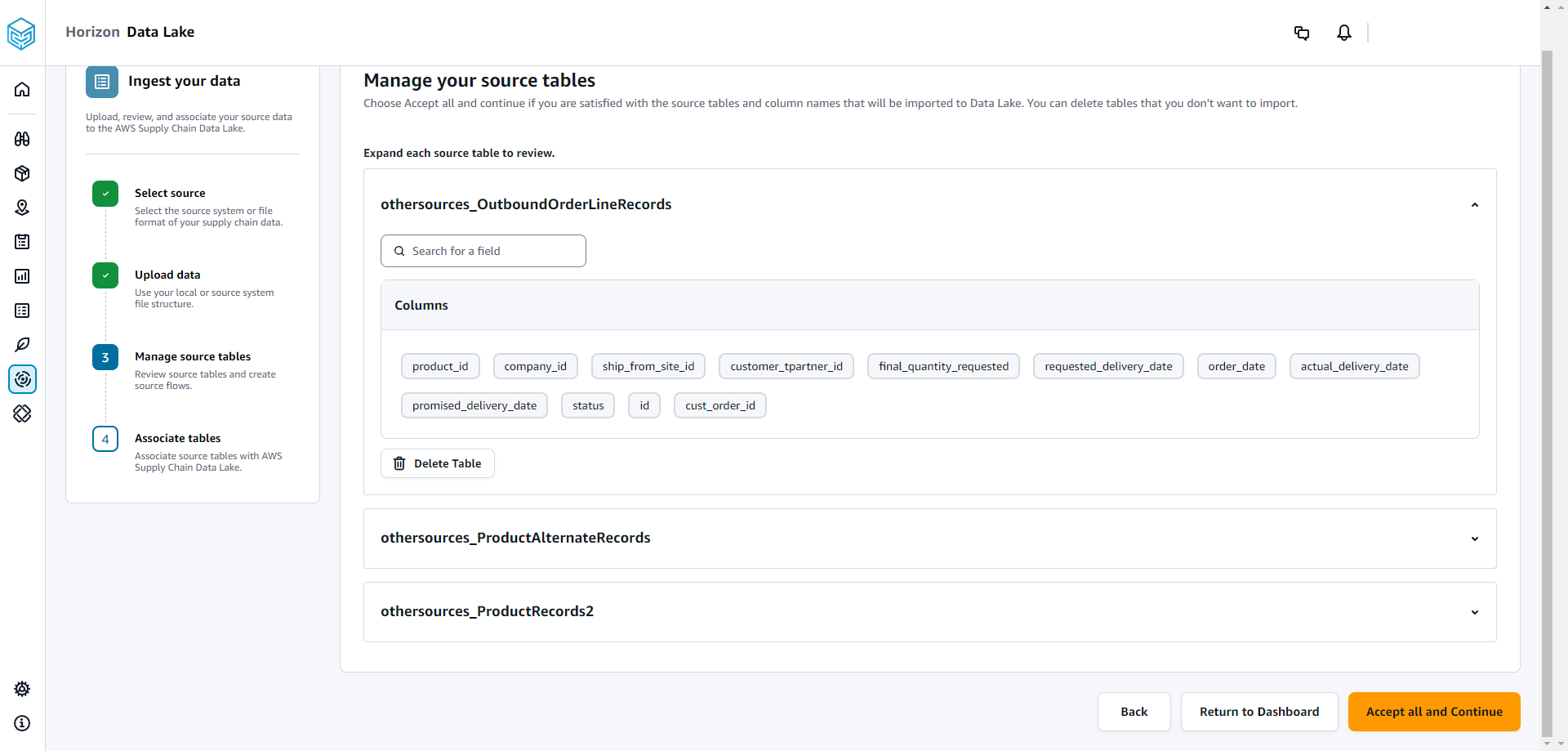
Escolha Aceitar tudo e continuar.
Uma mensagem sobre a associação automática de suas tabelas ao Cadeia de Suprimentos AWS data lake é exibida.
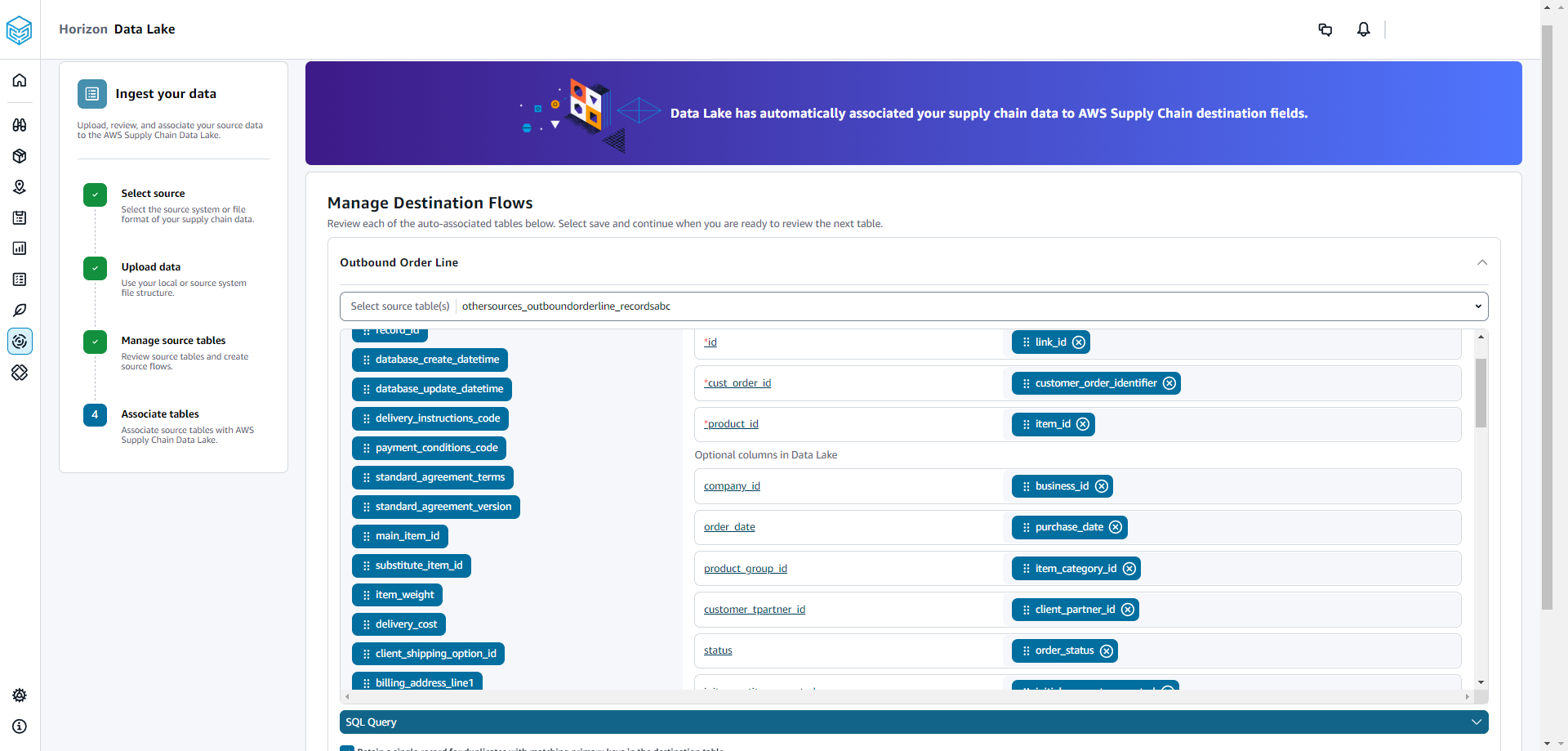
Em Gerenciar fluxos de destino, você pode revisar cada tabela associada automaticamente.
Por padrão, a associação automática está ativada e as colunas de origem são associadas automaticamente às colunas de destino. Para atualizar as colunas associadas automaticamente, você pode atualizar a SQL receita para criar sua receita personalizada.
Em Colunas de origem, todas as colunas de origem não associadas são listadas. Arraste e solte as colunas não associadas nas colunas de destino à direita.
Siga a etapa anterior para cada tabela associada automaticamente.
Selecione Enviar.
Escolha Sair e revisar os fluxos de destino.
