Este é o Guia do desenvolvedor do AWS CDK v2. O CDK v1 antigo entrou em manutenção em 1º de junho de 2022 e encerrou o suporte em 1º de junho de 2023.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Melhores práticas para desenvolver e implantar infraestrutura em nuvem com o CDK AWS
Com o AWS CDK, desenvolvedores ou administradores podem definir sua infraestrutura de nuvem usando uma linguagem de programação compatível. As aplicações do CDK devem ser organizadas em unidades lógicas, como API, banco de dados e recursos de monitoramento, e, opcionalmente, ter um pipeline para implantações automatizadas. As unidades lógicas devem ser implementadas como constructos, incluindo as seguintes:
-
Infraestrutura (como buckets do Amazon S3, bancos de dados do Amazon RDS ou uma rede da Amazon VPC)
-
Código de tempo de execução (como funções AWS Lambda)
-
Código de configuração
As pilhas definem o modelo de implantação dessas unidades lógicas. Para uma introdução mais detalhada aos conceitos por trás do CDK, consulte Introdução ao AWS CDK.
O AWS CDK reflete uma análise cuidadosa das necessidades de nossos clientes e equipes internas e dos padrões de falha que geralmente surgem durante a implantação e a manutenção contínua de aplicativos complexos em nuvem. Descobrimos que as falhas geralmente estão relacionadas a out-of-band "" alterações em um aplicativo que não foram totalmente testadas, como alterações de configuração. Por isso, desenvolvemos o AWS CDK em torno de um modelo no qual todo o seu aplicativo é definido em código, não apenas na lógica de negócios, mas também na infraestrutura e na configuração. Dessa forma, as mudanças propostas podem ser cuidadosamente analisadas, testadas de forma abrangente em ambientes semelhantes aos de produção em vários graus e totalmente revertidas se algo der errado.
No momento da implantação, o AWS CDK sintetiza um conjunto de nuvem que contém o seguinte:
-
AWS CloudFormation modelos que descrevem sua infraestrutura em todos os ambientes de destino
-
Ativos de arquivo que contêm seu código de runtime e seus arquivos de suporte
Com o CDK, cada confirmação na ramificação principal de controle de versão da sua aplicação pode representar uma versão completa, consistente e implantável da sua aplicação. Sua aplicação pode então ser implantada automaticamente sempre que uma alteração for feita.
A filosofia por trás do AWS CDK leva às nossas melhores práticas recomendadas, que dividimos em quatro grandes categorias.
dica
Considere também as melhores práticas AWS CloudFormation e os AWS serviços individuais que você usa, quando aplicável à infraestrutura definida pela CDK.
Práticas recomendadas para organizações
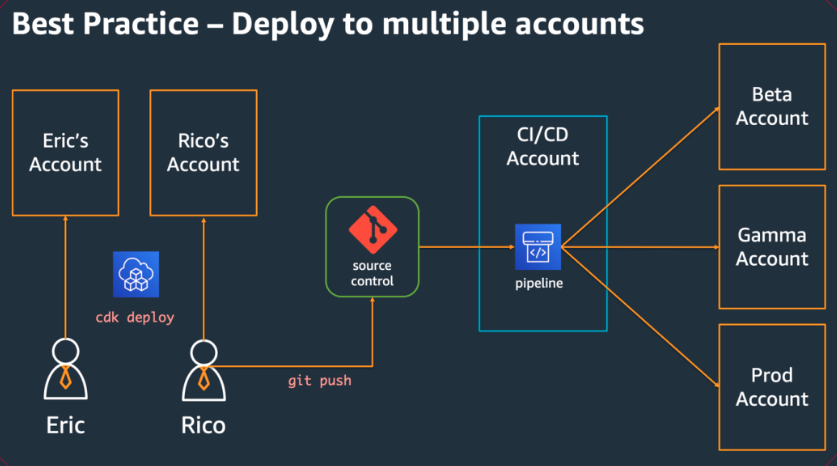
Nos estágios iniciais da adoção do AWS CDK, é importante considerar como preparar sua organização para o sucesso. É uma prática recomendada ter uma equipe de especialistas responsável por treinar e orientar o resto da empresa à medida que eles adotam o CDK. O tamanho dessa equipe pode variar, de uma ou duas pessoas em uma pequena empresa a um Centro de Excelência em Nuvem (CCoE) completo em uma empresa maior. Essa equipe é responsável por definir padrões e políticas para a infraestrutura de nuvem em sua empresa e também por treinar e orientar desenvolvedores.
O CCo E pode fornecer orientação sobre quais linguagens de programação devem ser usadas para a infraestrutura de nuvem. Os detalhes variam de uma organização para outra, mas uma boa política ajuda a garantir que os desenvolvedores possam entender e manter a infraestrutura de nuvem da empresa.
O CCo E também cria uma “landing zone” que define suas unidades organizacionais internas AWS. Uma landing zone é um AWS ambiente pré-configurado, seguro, escalável e com várias contas, baseado em esquemas de melhores práticas. Para unir os serviços que compõem sua zona de pouso, é possível usar a AWS Control Tower
As equipes de desenvolvimento devem poder usar suas próprias contas para testar e implantar novos recursos nessas contas, conforme necessário. Desenvolvedores individuais podem tratar esses recursos como extensões de sua própria estação de trabalho de desenvolvimento. Usando o CDK Pipelines, AWS os aplicativos CDK podem então ser implantados por meio de CI/CD uma conta em ambientes de teste, integração e produção (cada um isolado em sua própria AWS região ou conta). Isso é feito mesclando o código dos desenvolvedores no repositório canônico da sua organização.
Práticas recomendadas de codificação
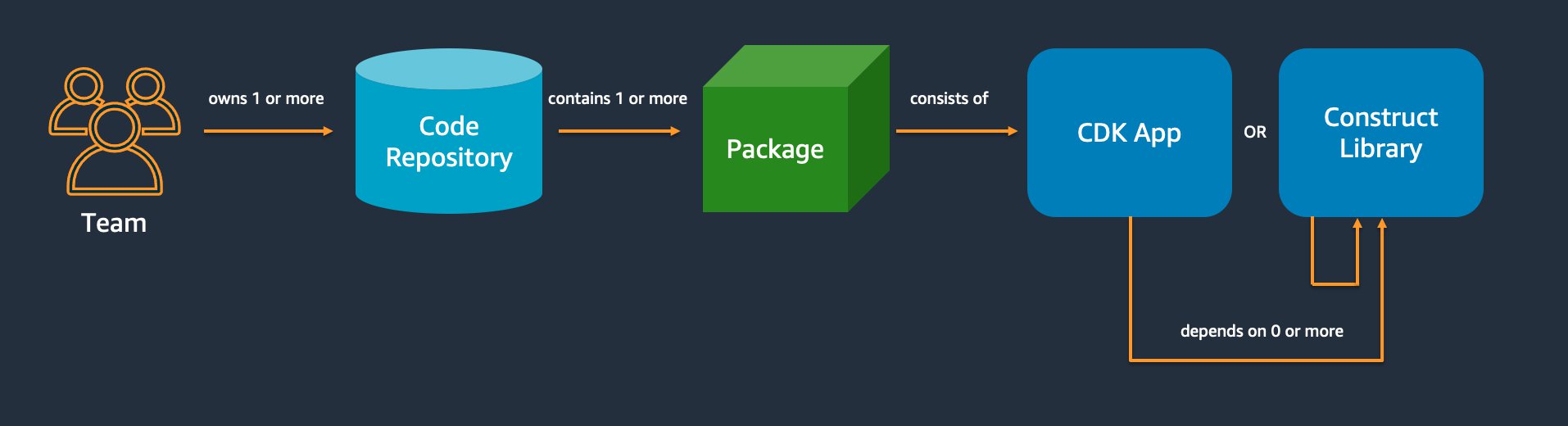
Esta seção apresenta as melhores práticas para organizar seu código AWS CDK. O diagrama a seguir mostra a relação entre uma equipe e os repositórios de código, os pacotes, as aplicações e as bibliotecas de constructos dessa equipe.
- Comece de forma simples e acrescente complexidade somente quando precisar
-
O princípio orientador da maioria das nossas práticas recomendadas é manter as coisas tão simples quanto possível, mas não mais simples que isso. Adicione complexidade somente quando seus requisitos exigirem uma solução mais complicada. Com o AWS CDK, você pode refatorar seu código conforme necessário para suportar novos requisitos. Você não precisa arquitetar todos os cenários possíveis com antecedência.
- Alinhe-se com o AWS Well-Architected Framework
-
O AWS Well-Architected
Framework define um componente como o código, a configuração AWS e os recursos que, juntos, atendem a um requisito. Um componente geralmente é a unidade de propriedade técnica e é dissociada de outros componentes. O termo workload é usado para identificar um conjunto de componentes que entrega o valor empresarial. Uma workload é normalmente o nível de detalhes sobre o qual os líderes de negócios e tecnologia se comunicam. Um aplicativo AWS CDK mapeia para um componente conforme definido pelo AWS Well-Architected Framework. AWS Os aplicativos CDK são um mecanismo para codificar e fornecer as melhores práticas de aplicativos em nuvem da Well-Architected. Você também pode criar e compartilhar componentes como bibliotecas de código reutilizáveis por meio de repositórios de artefatos, como o AWS CodeArtifact.
- Cada aplicativo começa com um único pacote em um único repositório
-
Um único pacote é o ponto de entrada do seu aplicativo AWS CDK. Aqui, você define como e onde implantar as diferentes unidades lógicas da sua aplicação. Você também define o CI/CD pipeline para implantar o aplicativo. Os constructos da aplicação definem as unidades lógicas da sua solução.
Use pacotes adicionais para constructos que você usa em mais de uma aplicação. (Os constructos compartilhados também devem ter seu próprio ciclo de vida e estratégia de teste.) As dependências entre pacotes no mesmo repositório são gerenciadas pelas ferramentas de compilação do seu repositório.
Embora seja possível, não recomendamos colocar várias aplicações no mesmo repositório, especialmente ao usar pipelines de implantação automatizados. Isso aumenta o “raio de alcance” das mudanças durante a implantação. Quando há várias aplicações em um repositório, as alterações em uma aplicação acionam a implantação dos outros (mesmo que os outros não tenham sido alterados). Além disso, uma interrupção em uma aplicação impede que os outras aplicações sejam implantados.
- Mova o código para repositórios com base no ciclo de vida do código ou na propriedade da equipe
-
Quando os pacotes começarem a ser usados em várias aplicações, mova-os para seu próprio repositório. Dessa forma, os pacotes podem ser referenciados pelos sistemas de criação de aplicações que os usam e também podem ser atualizados em cadências independentes dos ciclos de vida da aplicação. No entanto, a princípio, pode fazer sentido colocar todos os constructos compartilhados em um repositório.
Além disso, mova os pacotes para seu próprio repositório quando equipes diferentes estiverem trabalhando neles. Isso ajuda na aplicação do controle de acesso.
Para consumir pacotes além dos limites do repositório, você precisa de um repositório de pacotes privado, semelhante ao NPM ou ao Maven Central PyPi, mas interno à sua organização. Você também precisa de um processo de lançamento que compile, teste e publique o pacote no repositório privado de pacotes. CodeArtifactpode hospedar pacotes para as linguagens de programação mais populares.
As dependências dos pacotes no repositório de pacotes são gerenciadas pelo gerenciador de pacotes da sua linguagem, como o NPM for TypeScript or applications. JavaScript Seu gerenciador de pacotes ajuda a garantir que as compilações sejam repetíveis. Isso é feito gravando as versões específicas de cada pacote do qual sua aplicação depende. Também permite que você atualize essas dependências de forma controlada.
Pacotes compartilhados precisam de uma estratégia de teste diferente. Para um única aplicação, pode ser suficiente implantá-lo em um ambiente de teste e confirmar se ele ainda funciona. Mas pacotes compartilhados devem ser testados independentemente da aplicação consumidora, como se estivessem sendo lançados para o público. (Sua organização pode optar por lançar alguns pacotes compartilhados para o público.)
Lembre-se de que um constructo pode ser arbitrariamente simples ou complexo. O
Bucketé um constructo, masCameraShopWebsitetambém pode ser um constructo.
- A infraestrutura e o código de tempo de execução residem no mesmo pacote
-
Além de gerar AWS CloudFormation modelos para a implantação da infraestrutura, o AWS CDK também agrupa ativos de tempo de execução, como funções Lambda e imagens do Docker, e os implanta junto com sua infraestrutura. Isso possibilita a combinação do código que define sua infraestrutura e do código que implementa sua lógica de runtime em um único constructo. Essa é uma prática recomendada. Esses dois tipos de código não precisam estar em repositórios separados ou mesmo em pacotes separados.
Para desenvolver os dois tipos de código juntos, você pode usar um constructo independente que descreva completamente uma parte da funcionalidade, incluindo sua infraestrutura e lógica. Com um constructo independente, você pode testar os dois tipos de código isoladamente, compartilhar e reutilizar o código entre projetos e criar versões de todo o código em sincronia.
Práticas recomendadas de constructos
Esta seção contém práticas recomendadas para o desenvolvimento de constructos. Os constructos são módulos reutilizáveis e combináveis que encapsulam recursos. Eles são os alicerces dos aplicativos AWS CDK.
- Modele com construções, implante com pilhas
-
As pilhas são a unidade de implantação: tudo em uma pilha é implantado em conjunto. Portanto, ao criar as unidades lógicas de nível superior do seu aplicativo a partir de vários AWS recursos, represente cada unidade lógica como uma construção, não como uma pilha. Use pilhas somente para descrever como seus constructos devem ser compostos e conectados para seus vários cenários de implantação.
Por exemplo, se uma de suas unidades lógicas for um site, os constructos que a compõem (como um bucket do Amazon S3, API Gateway, funções do Lambda ou tabelas do Amazon RDS) devem ser compostas em um único constructo de alto nível. Em seguida, esse constructo deve ser instanciado em uma ou mais pilhas para implantação.
Ao usar constructos para criação e pilhas para implantação, você melhora o potencial de reutilização de sua infraestrutura e oferece mais flexibilidade na forma como ela é implantada.
- Configure com propriedades e métodos, não com variáveis de ambiente
-
Pesquisas de variáveis de ambiente dentro de constructos e pilhas são um antipadrão comum. Tanto os constructos quanto as pilhas devem aceitar um objeto de propriedades para permitir a configuração total inteiramente em código. Fazer o contrário introduz uma dependência na máquina na qual o código será executado, o que cria ainda mais informações de configuração que você precisa rastrear e gerenciar.
Em geral, as pesquisas de variáveis de ambiente devem ser limitadas ao nível superior de um aplicativo AWS CDK. Elas também devem ser usadas para transmitir informações necessárias para execução em um ambiente de desenvolvimento. Para obter mais informações, consulte Ambientes para o AWS CDK.
- Teste unitário sua infraestrutura
-
Para executar consistentemente um conjunto completo de testes de unidade no momento da criação em todos os ambientes, evite consultas na rede durante a síntese e modele todos os estágios de produção no código. (Essas práticas recomendadas serão abordadas posteriormente.) Se qualquer confirmação individual sempre resultar no mesmo modelo gerado, você pode confiar nos testes de unidade que você escreve para confirmar se os modelos gerados têm a aparência esperada. Para obter mais informações, consulte Testar aplicativos AWS CDK.
- Não alterar o ID lógico dos recursos com estado
-
Alterar o ID lógico de um recurso resulta na substituição do recurso por um novo na próxima implantação. Para recursos com estado, como bancos de dados e buckets do S3, ou infraestrutura persistente, como uma Amazon VPC, isso raramente é desejado. Tenha cuidado com qualquer refatoração do seu código AWS CDK que possa fazer com que o ID seja alterado. Escreva testes unitários que afirmem que a lógica IDs de seus recursos com estado permanece estática. O ID lógico é derivado do
idque você especifica ao instanciar o constructo e da posição dele na árvore de constructos. Para obter mais informações, consulte Logical IDs.
- Os constructos não são suficientes para a conformidade
-
Muitos clientes corporativos escrevem seus próprios wrappers para construções L2 (as construções “selecionadas” que representam AWS recursos individuais com padrões sensatos integrados e melhores práticas). Esses wrappers aplicam as práticas recomendadas de segurança, como criptografia estática e políticas do IAM específicas. Por exemplo, você pode criar um
MyCompanyBucketpara usar em suas aplicações no lugar do constructo doBucketdo Amazon S3 usual. Esse padrão é útil para apresentar diretrizes de segurança no início do ciclo de vida do desenvolvimento de software, mas não confie nele como o único meio de imposição.Em vez disso, use AWS recursos como políticas de controle de serviço e limites de permissão para reforçar suas barreiras de segurança no nível da organização. Use o Aspects e o AWS CDK ou ferramentas como o CloudFormation Guard
para fazer afirmações sobre as propriedades de segurança dos elementos da infraestrutura antes da implantação. Use o AWS CDK para fazer o que ele faz de melhor. Por fim, lembre-se de que escrever suas próprias construções “L2+” pode impedir que seus desenvolvedores tirem proveito de pacotes de AWS CDK, como AWS Solutions Constructs ou construções de terceiros do Construct Hub. Esses pacotes geralmente são criados em construções AWS CDK padrão e não poderão usar suas construções de wrapper.
Práticas recomendadas de aplicações
Nesta seção, discutimos como escrever seus aplicativos de AWS CDK, combinando construções para definir como seus AWS recursos estão conectados.
- Tome decisões na hora da síntese
-
Embora AWS CloudFormation permita que você tome decisões no momento da implantação (usando
Conditions{ Fn::If },, eParameters) e o AWS CDK ofereça algum acesso a esses mecanismos, não recomendamos usá-los. Os tipos de valores que podem ser usados e os tipos de operações que podem ser realizadas neles são limitados em comparação com o que está disponível em uma linguagem de programação de uso geral.Em vez disso, tente tomar todas as decisões, como qual construção instanciar, em seu aplicativo AWS CDK usando as
ifinstruções e outros recursos da sua linguagem de programação. Por exemplo, um idioma CDK comum, iterando em uma lista e instanciando uma construção com valores de cada item na lista, simplesmente não é possível usando expressões. AWS CloudFormationTrate AWS CloudFormation como um detalhe de implementação que o AWS CDK usa para implantações robustas na nuvem, não como um destino de linguagem. Você não está escrevendo AWS CloudFormation modelos em TypeScript Python, você está escrevendo um código CDK que por acaso é usado CloudFormation para implantação.
- Use nomes de recursos gerados, não nomes físicos
-
Os nomes são um recurso precioso. Cada nome só pode ser usado uma vez. Portanto, se você codificar um nome de tabela ou nome de bucket em sua infraestrutura e em sua aplicação, não poderá implantar essa parte da infraestrutura duas vezes na mesma conta. (O nome do qual estamos falando aqui é o nome especificado, por exemplo, pela propriedade
bucketNameem um constructo de bucket do Amazon S3.)Pior ainda, você não poderá fazer alterações no recurso que exijam sua substituição. Se uma propriedade só puder ser definida na criação do recurso, como o
KeySchemade uma tabela do Amazon DynamoDB, essa propriedade será imutável. A alteração dessa propriedade requer um novo recurso. No entanto, o novo recurso deve ter o mesmo nome para ser um verdadeiro substituto. Mas ele não pode ter o mesmo nome enquanto o recurso existente ainda estiver usando esse nome.Uma abordagem melhor é especificar o mínimo possível de nomes. Se você omitir os nomes dos recursos, o AWS CDK os gerará para você de uma forma que não cause problemas. Suponha que você tenha uma tabela como recurso. Em seguida, você pode passar o nome da tabela gerada como uma variável de ambiente para sua função AWS Lambda. Em seu aplicativo AWS CDK, você pode referenciar o nome da tabela como
table.tableName. Como alternativa, você pode gerar um arquivo de configuração na sua EC2 instância Amazon na inicialização ou gravar o nome real da tabela no AWS Systems Manager Parameter Store para que seu aplicativo possa lê-lo a partir daí.Se o local de que você precisa for outra pilha de AWS CDK, isso é ainda mais simples. Supondo que uma pilha defina o recurso e outra pilha precise usá-lo, o seguinte se aplica:
-
Se as duas pilhas estiverem no mesmo aplicativo AWS CDK, passe uma referência entre as duas pilhas. Por exemplo, salve uma referência ao constructo do recurso como um atributo da pilha definidora (
this.stack.uploadBucket = amzn-s3-demo-bucket). Em seguida, passe esse atributo para o construtor da pilha que precisa do recurso. -
Quando as duas pilhas estiverem em aplicativos AWS CDK diferentes, use um
frommétodo estático para usar um recurso definido externamente com base em seu ARN, nome ou outros atributos. (Por exemplo, useTable.fromArn()para uma tabela do DynamoDB). Use aCfnOutputconstrução para imprimir o ARN ou outro valor necessário na saída decdk deploy, ou procure no AWS Management Console. Como alternativa, o segundo aplicativo pode ler o CloudFormation modelo gerado pelo primeiro aplicativo e recuperar esse valor daOutputsseção.
-
- Defina políticas de remoção e retenção de registros
-
O AWS CDK tenta evitar que você perca dados adotando políticas que retêm tudo o que você cria. Por exemplo, a política de remoção padrão em recursos que contêm dados (como buckets do Amazon S3 e tabelas de banco de dados) é não excluir o recurso quando ele é removido da pilha. Em vez disso, o recurso fica órfão da pilha. Da mesma forma, o padrão do CDK é reter todos os logs para sempre. Em ambientes de produção, esses padrões podem resultar rapidamente no armazenamento de grandes quantidades de dados que você realmente não precisa e na fatura correspondente AWS .
Considere cuidadosamente o que você deseja que essas políticas sejam para cada recurso de produção e especifique-as adequadamente. Use o Aspects e o AWS CDK para validar as políticas de remoção e registro em sua pilha.
- Separe seu aplicativo em várias pilhas, conforme determinado pelos requisitos de implantação
-
Não há uma regra rígida e rápida de quantas pilhas sua aplicação precisa. Normalmente, você acabará baseando a decisão em seus padrões de implantação. Lembre-se das seguintes orientações:
-
Normalmente, é mais fácil manter o máximo possível de recursos na mesma pilha, então mantenha-os juntos, a menos que você saiba que os quer separados.
-
Considere manter os recursos com estado (como bancos de dados) em uma pilha separada dos recursos sem estado. Em seguida, você pode ativar a proteção contra encerramento na pilha com estado. Dessa forma, você pode destruir ou criar livremente várias cópias da pilha sem estado sem risco de perda de dados.
-
Recursos com estado são mais sensíveis à renomeação de constructos, pois renomear leva à substituição de recursos. Portanto, não agrupe recursos com estado em constructos que provavelmente serão movidos ou renomeados (a menos que o estado possa ser reconstruído caso perdido, como um cache). Esse é outro bom motivo para colocar recursos com estado em sua própria pilha.
-
- Comprometa-se
cdk.context.jsona evitar comportamentos não determinísticos -
O determinismo é fundamental para implantações bem-sucedidas de AWS CDK. Um aplicativo AWS CDK deve ter essencialmente o mesmo resultado sempre que for implantado em um determinado ambiente.
Como seu aplicativo AWS CDK é escrito em uma linguagem de programação de uso geral, ele pode executar código arbitrário, usar bibliotecas arbitrárias e fazer chamadas de rede arbitrárias. Por exemplo, você pode usar um AWS SDK para recuperar algumas informações da sua AWS conta enquanto sintetiza seu aplicativo. Reconheça que isso resultará em requisitos adicionais de configuração de credenciais, maior latência e uma chance, ainda que pequena, de falha toda vez que você executar
cdk synth.Nunca modifique sua AWS conta ou seus recursos durante a síntese. Sintetizar uma aplicação não deve ter efeitos colaterais. As alterações em sua infraestrutura devem ocorrer somente na fase de implantação, após a geração do AWS CloudFormation modelo. Dessa forma, se houver algum problema, AWS CloudFormation pode reverter automaticamente a alteração. Para fazer alterações que não podem ser feitas facilmente na estrutura do AWS CDK, use recursos personalizados para executar código arbitrário no momento da implantação.
Mesmo chamadas que são estritamente somente para leitura não são necessariamente seguras. Considere o que acontece se o valor retornado por uma chamada de rede for alterado. Que parte da sua infraestrutura isso afetará? O que acontecerá com os recursos já implantados? A seguir estão dois exemplos de situações em que uma mudança repentina nos valores pode causar um problema.
-
Se você provisionar uma Amazon VPC para todas as zonas de disponibilidade disponíveis em uma região específica e o número AZs for dois no dia da implantação, seu espaço IP será dividido pela metade. Se AWS iniciar uma nova zona de disponibilidade no dia seguinte, a próxima implantação tentará dividir seu espaço IP em terços, exigindo que todas as sub-redes sejam recriadas. Isso provavelmente não será possível porque suas EC2 instâncias da Amazon ainda estão em execução e você precisará limpá-las manualmente.
-
Se você consultar a imagem mais recente da máquina Amazon Linux e implantar uma EC2 instância da Amazon, e no dia seguinte uma nova imagem for lançada, uma implantação subsequente selecionará a nova AMI e substituirá todas as suas instâncias. Isso pode não ser o que você esperava que acontecesse.
Essas situações podem ser perniciosas porque a mudança AWS lateral pode ocorrer após meses ou anos de implantações bem-sucedidas. De repente, suas implantações estão falhando “sem motivo” e você esqueceu há muito tempo o que fez e por quê.
Felizmente, o AWS CDK inclui um mecanismo chamado provedores de contexto para registrar um instantâneo de valores não determinísticos. Isso permite que futuras operações de síntese produzam exatamente o mesmo modelo que produziam quando foram implantadas pela primeira vez. As únicas alterações no novo modelo são as alterações que você fez no seu código. Quando você usa o método
.fromLookup()de um constructo, o resultado da chamada é armazenado em cache emcdk.context.json. É necessário submeter isso ao controle de versão junto com o resto do seu código para garantir que futuras execuções da sua aplicação do CDK usem o mesmo valor. O Kit de Ferramentas CDK inclui comandos para gerenciar o cache de contexto, para que você possa atualizar entradas específicas quando precisar. Para obter mais informações, consulte Valores de contexto e o AWS CDK.Se você precisar de algum valor (de AWS ou de outro lugar) para o qual não haja um provedor de contexto CDK nativo, recomendamos escrever um script separado. O script deve recuperar o valor e gravá-lo em um arquivo e, em seguida, ler esse arquivo na sua aplicação do CDK. Execute o script somente quando quiser atualizar o valor armazenado, não como parte do seu processo de criação normal.
-
- Deixe o AWS CDK gerenciar funções e grupos de segurança
-
Com a
grantspropriedade da biblioteca de construção do AWS CDK e seus métodos de conveniência, você pode criar funções de AWS Identity and Access Management que concedem acesso a um recurso por outro usando permissões com escopo mínimo. Por exemplo, considere uma linha como a seguinte:amzn-s3-demo-bucket.grants.read(myLambda)Essa única linha adiciona uma política à função do Lambda (que também é criada para você). Essa função e suas políticas são mais de uma dúzia de linhas CloudFormation que você não precisa escrever. O AWS CDK concede somente as permissões mínimas necessárias para que a função seja lida do bucket.
Se você exigir que os desenvolvedores sempre usem funções predefinidas criadas por uma equipe de segurança, a codificação do AWS CDK se torna muito mais complicada. Suas equipes podem perder muita flexibilidade na forma como projetam suas aplicações. Uma alternativa melhor é usar políticas de controle de serviços e limites de permissões para garantir que os desenvolvedores permaneçam dentro das barreiras de proteção.
- Modele todas as etapas de produção em código
-
Em AWS CloudFormation cenários tradicionais, sua meta é produzir um único artefato parametrizado para que possa ser implantado em vários ambientes de destino após a aplicação de valores de configuração específicos a esses ambientes. No CDK, você pode e deve criar essa configuração em seu código-fonte. Crie uma pilha para seu ambiente de produção e crie uma pilha separada para cada um dos outros estágios. Em seguida, coloque os valores de configuração de cada pilha no código. Use serviços como Secrets Manager
e Systems Manager Parameter Store para valores confidenciais que você não deseja verificar no controle de origem, usando os nomes ou ARNs desses recursos. Quando você sintetiza sua aplicação, o conjunto de nuvem criado na pasta
cdk.outcontém um modelo separado para cada ambiente. Toda a sua criação é determinística. Não há out-of-band alterações em seu aplicativo, e qualquer confirmação sempre gera exatamente o mesmo AWS CloudFormation modelo e os ativos que o acompanham. Isso torna o teste de unidade muito mais confiável.
- Meça tudo
-
Atingir a meta de implantação contínua completa, sem intervenção humana, requer um alto nível de automação. Essa automação só é possível com um monitoramento extensivo. Para medir todos os aspectos de seus recursos implantados, crie métricas, alarmes e painéis. Não pare de medir coisas como uso da CPU e espaço em disco. Além disso, registre suas métricas de negócios e use essas medidas para automatizar decisões de implantação, como reversões. A maioria das construções L2 no AWS CDK tem métodos convenientes para ajudá-lo a criar métricas, como o
metricUserErrors()método na classe.dynamodb.Table
