As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treine classificadores personalizados (console)
Você pode criar e treinar um classificador personalizado usando o console e, em seguida, usar o classificador personalizado para analisar seus documentos.
Para treinar um classificador personalizado, você precisa de um conjunto de documentos de treinamento. Você rotula esses documentos com as categorias que deseja que o classificador de documentos reconheça. Para informações sobre como preparar seus documentos de treinamento, consulte Preparar dados de treinamento do classificador.
Criar e treinar um modelo de classificador de documentos
-
Faça login no Console de gerenciamento da AWS e abra o console do Amazon Comprehend em https://console.aws.amazon.com/comprehend/
-
No menu à esquerda, escolha Personalização e, em seguida, Classificação personalizada.
-
Escolha Criar novo modelo.
-
Em Configurações do modelo, insira um nome de modelo para o classificador. O nome deve ser exclusivo na sua conta e na sua região atual.
(Opcional) Insira um nome de versão. O nome deve ser exclusivo na sua conta e na sua região atual.
-
Selecione o idioma dos documentos de treinamento. Para ver os idiomas com os quais os classificadores são compatíveis, consulte Modelos de classificação de treinamento.
-
(Opcional) Se você quiser criptografar os dados no volume de armazenamento enquanto o Amazon Comprehend processa sua tarefa de treinamento, escolha Criptografia classificadora. Em seguida, selecione se deseja usar uma chave KMS associada à sua conta atual ou uma de outra conta.
Se estiver usando uma chave associada à conta atual, escolha o ID da chave para o ID da chave KMS.
Se estiver usando uma chave associada a uma conta diferente, insira o ARN do ID da chave em ARN da chave KMS.
nota
Para mais informações sobre como criar e usar chaves KMS e a criptografia associada, consulte o AWS Key Management Service (AWS KMS).
-
Em Especificações de dados, escolha o Tipo de modelo de treinamento a ser usado.
Documentos de texto sem formatação: escolha essa opção para criar um modelo de texto sem formatação. Treine o modelo usando documentos de texto sem formatação.
Documentos nativos: escolha essa opção para criar um modelo de documento nativo. Treine o modelo usando documentos nativos (PDF, Word, imagens).
-
Escolha o Formato de dados dos seus dados de treinamento. Para mais informações sobre o formato, consulte Formatos de arquivo de treinamento do classificador.
Arquivo CSV: escolha essa opção se seus dados de treinamento usarem o formato de arquivo CSV.
Manifesto aumentado: escolha essa opção se você usou o Ground Truth para criar arquivos de manifesto aumentados para seus dados de treinamento. Esse formato estará disponível se você escolher Documentos de texto sem formatação como o tipo de modelo de treinamento.
-
Escolha o Modo classificador a ser usado.
Single-label modo: escolha esse modo se as categorias que você está atribuindo aos documentos forem mutuamente exclusivas e você estiver treinando seu classificador para atribuir uma etiqueta a cada documento. Na API da Amazon Comprehend, o modo de rótulo único é conhecido como modo multiclasse.
Multi-label modo: Escolha esse modo se várias categorias puderem ser aplicadas a um documento ao mesmo tempo e você estiver treinando seu classificador para atribuir uma ou mais etiquetas a cada documento.
-
Se você escolher o Multi-label modo, poderá selecionar o delimitador para etiquetas. Use esse caractere delimitador para separar rótulos quando houver várias classes para um documento de treinamento. O delimitador padrão é o caractere pipe.
-
(Opcional) Se escolher Manifesto aumentado como formato de dados, poderá inserir até cinco arquivos de manifesto aumentados. Cada arquivo de manifesto aumentado contém um conjunto de dados de treinamento ou um conjunto de dados de teste. Você deve fornecer pelo menos um conjunto de dados de treinamento. Os conjuntos de dados de teste são opcionais. Use as seguintes etapas para configurar os arquivos de manifesto aumentados:
-
Em Conjunto de dados de treinamento e teste, expanda o painel Localização de entrada.
-
Em Tipo de conjunto de dados, escolha Dados de treinamento ou Dados de teste.
-
Para a localização S3 do arquivo de manifesto aumentado do SageMaker AI Ground Truth, insira a localização do bucket Amazon S3 que contém o arquivo de manifesto ou navegue até ele escolhendo Browse S3. O perfil do IAM que você está usando para obter permissões a fim de acessar a tarefa de treinamento deve ter permissões para leitura no bucket do S3.
-
Para os Nomes dos atributos, insira o nome do atributo que contém suas anotações. Se o arquivo contiver anotações de várias tarefas de rotulagem em cadeia, adicione um atributo para cada tarefa.
Para adicionar outro local de entrada, escolha Adicionar local de entrada e configure o próximo local.
-
-
(Opcional) Se escolheu o Arquivo CSV como formato de dados, use as etapas a seguir para configurar o conjunto de dados de treinamento e o conjunto de dados de teste opcional:
-
Em Conjunto de dados de treinamento, insira a localização do bucket do Amazon S3 que contém seu arquivo CSV de dados de treinamento ou navegue até ele escolhendo Procurar no S3. O perfil do IAM que você está usando para obter permissões a fim de acessar a tarefa de treinamento deve ter permissões para leitura no bucket do S3.
(Opcional) Se escolheu Documentos nativos como o tipo de modelo de treinamento, você também fornecerá a URL da pasta do Amazon S3 contendo os arquivos de exemplo de treinamento.
-
Em Testar conjunto de dados, selecione se você está fornecendo dados extras para o Amazon Comprehend testar o modelo treinado.
-
Divisão automática: a divisão automática seleciona automaticamente 10% dos seus dados de treinamento a fim de reservar para uso como dados de teste.
(Opcional) Fornecido pelo cliente: insira a URL do arquivo CSV de dados de teste no Amazon S3. Você também pode navegar até localização do arquivo no Amazon S3 e escolher Selecionar pasta.
(Opcional) Se escolher Documentos nativos como o tipo de modelo de treinamento, você também fornecerá a URL da pasta do Amazon S3 contendo os arquivos de teste.
-
-
-
(Opcional) Para Modo de leitura do documento, você pode substituir as ações padrão de extração de texto. Essa opção não é necessária para modelos de texto sem formatação, já que se aplica à extração de texto para documentos digitalizados. Para obter mais informações, consulte Configurar opções de extração de texto.
-
(Opcional para modelos de texto sem formatação) Para Dados de saída, insira a localização de um bucket do Amazon S3 para salvar os dados de saída do treinamento, como a matriz de confusão. Para obter mais informações, consulte Matriz de confusão.
(Opcional) Se criptografar o resultado de saída da sua tarefa de treinamento, escolha Criptografia. Em seguida, escolha se deseja usar uma chave KMS associada à conta atual ou uma de outra conta.
Se estiver usando uma chave associada à conta atual, escolha o alias da chave para o ID da chave KMS.
Se você estiver usando uma chave associada a uma conta diferente, insira o ARN do alias ou ID da chave em ID da chave KMS.
-
Para o Perfil do IAM, selecione Escolher um perfil do IAM existente e, em seguida, escolha um perfil do IAM existente com permissões de leitura para o bucket do S3 contendo seus documentos de treinamento. O perfil deve ter uma política de confiança que comece com
comprehend.amazonaws.com.rproxy.goskope.compara ser válida.Se ainda não tem um perfil do IAM com essas permissões, escolha Criar um perfil do IAM. Escolha as permissões de acesso para conceder esse perfil e, depois, escolha um sufixo de nome para diferenciar o perfil dos perfis do IAM em sua conta.
nota
Para documentos de entrada criptografados, o perfil do IAM usada também deve ter uma permissão do
kms:Decrypt. Para obter mais informações, consulte Permissões necessárias para usar a criptografia KMS. -
(Opcional) Para lançar seus recursos no Amazon Comprehend a partir de uma VPC, insira o ID da VPC em VPC ou escolha o ID na lista suspensa.
Escolha a sub-rede em Sub-redes. Depois de selecionar a primeira sub-rede, é possível escolher outras adicionais.
Em Grupo(s) de segurança, escolha o grupo de segurança a ser usado se tiver especificado um. Depois de selecionar o primeiro grupo de segurança, é possível escolher outros.
nota
Quando você usa uma VPC com sua tarefa de classificação, os
DataAccessRoleusados para as operações Create and Start devem ter permissões para a VPC que acessa os documentos de entrada e o bucket de saída. -
(Opcional) Para adicionar uma tag ao classificador personalizado, insira um par de valores-chave em Tags. Escolha Adicionar Tag. Para remover esse par antes de criar o classificador, escolha Remover tag. Para obter mais informações, consulte Marcando seus Recursos.
-
Escolha Criar.
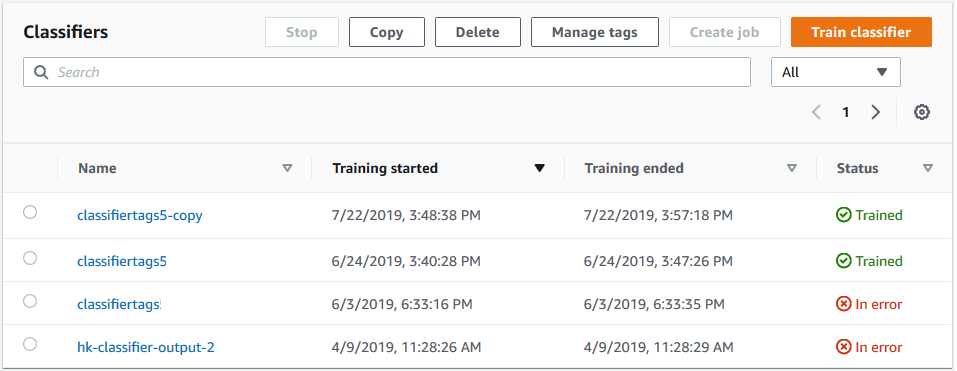
O console exibe a página Classificadores. O novo classificador aparece na tabela, mostrando Submitted como seu status. Quando o classificador começa a processar os documentos de treinamento, o status muda para Training. Quando um classificador está pronto para uso, o status muda para Trained ou Trained with warnings. Se o status for TRAINED_WITH_WARNINGS, revise a pasta de arquivos ignorados no Saída do treinamento do classificador.
Se o Amazon Comprehend encontrar erros durante a criação ou o treinamento, o status mudará para In error. Escolha uma tarefa classificadora na tabela para obter mais informações sobre o classificador, incluindo mensagens de erro.