AWS Data Pipeline não está mais disponível para novos clientes. Os clientes existentes do AWS Data Pipeline podem continuar usando o serviço normalmente. Saiba mais
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Executar trabalho em recursos existentes usando o Task Runner
É possível instalar o Task Runner em recursos computacionais que você gerencia, como uma instância do Amazon EC2, um servidor físico ou uma estação de trabalho. O Task Runner pode ser instalado em qualquer lugar, em qualquer hardware ou sistema operacional compatível, desde que possa se comunicar com o serviço AWS Data Pipeline web.
Essa abordagem pode ser útil quando, por exemplo, você deseja usar AWS Data Pipeline para processar dados armazenados no firewall da sua organização. Ao instalar o Task Runner em um servidor na rede local, você pode acessar o banco de dados local com segurança e depois pesquisar AWS Data Pipeline a próxima tarefa a ser executada. Quando AWS Data Pipeline termina o processamento ou exclui o pipeline, a instância do Task Runner permanece em execução no seu recurso computacional até que você a desligue manualmente. Os logs do Task Runner são mantidos depois que a execução do pipeline é concluída.
Para usar o Task Runner em um recurso que você gerencia, é necessário fazer download do Task Runner e instalá-lo no seu recurso computacional, seguindo os procedimentos nesta seção.
nota
Você só pode instalar o Task Runner no Linux, UNIX ou macOS. O Task Runner não é compatível com o sistema operacional Windows.
Para usar o Task Runner 2.0, a versão mínima necessária do Java é 1.7.
Para conectar um Task Runner que você instalou às atividades do pipeline que devem ser processadas, adicione um campo de workerGroup ao objeto e configure o Task Runner para pesquisar o valor do grupo desse operador. É possível fazer isso especificando a string do grupo do operador como um parâmetro (por exemplo, --workerGroup=wg-12345) ao executar o arquivo JAR do Task Runner.
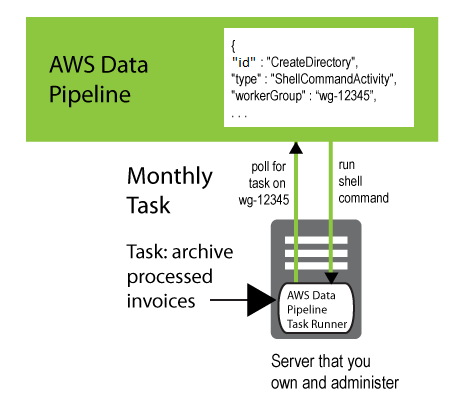
{ "id" : "CreateDirectory", "type" : "ShellCommandActivity", "workerGroup" : "wg-12345", "command" : "mkdir new-directory" }
Instalando o Task Runner
Esta seção explica como instalar e configurar o Task Runner e quais são os pré-requisitos. A instalação é um processo manual simples.
Para instalar o Task Runner
-
O Task Runner requer Java versões 1.6 ou 1.8. Para determinar se o Java está instalado e qual versão está sendo executada, use o seguinte comando:
java -versionSe você não tiver o Java 1.6 ou 1.8 instalado em seu computador, baixe uma dessas versões em http://www.oracle. com/technetwork/java/index.html
. Faça download e instale o Java. Em seguida, vá para a próxima etapa. -
Faça o download
TaskRunner-1.0.jarde https://s3.amazonaws.com/datapipeline-us-east-1/us-east-1/ software/latest/TaskRunner/TaskRunner -1.0.jare copie-o em uma pasta no recurso de computação de destino. Para clusters do Amazon EMR que executam tarefas de EmrActivity, é necessário instalar o Task Runner no nó principal do cluster. -
Ao usar o Task Runner para se conectar ao serviço AWS Data Pipeline web para processar seus comandos, os usuários precisam de acesso programático a uma função que tenha permissões para criar ou gerenciar pipelines de dados. Para obter mais informações, consulte Conceder acesso programático.
-
O Task Runner se conecta ao serviço AWS Data Pipeline web usando HTTPS. Se você estiver usando um AWS recurso, verifique se o HTTPS está habilitado na tabela de roteamento e na ACL de sub-rede apropriadas. Se você estiver usando um firewall ou proxy, verifique se a porta 443 está aberta.
Iniciar o Task Runner
Em uma nova janela de prompt de comando configurada para o diretório em que você instalou o Task Runner, inicie o Task Runner com o comando a seguir.
java -jar TaskRunner-1.0.jar --config ~/credentials.json--workerGroup=myWorkerGroup--region=MyRegion--logUri=s3://amzn-s3-demo-bucket/foldername
A opção --config aponta para o arquivo de credenciais.
A opção --workerGroup especifica o nome do grupo do operador, que deve ser o mesmo valor especificado no seu pipeline para que tarefas sejam processadas.
A opção --region especifica a região de serviço de onde as tarefas serão retiradas para execução.
A opção --logUri é usada para enviar seus logs compactados para um local no Amazon S3.
Quando o Task Runner está ativo, ele imprime o caminho do local onde os arquivos de log serão gravados na janela do terminal. Veja um exemplo do a seguir:
Logging to /Computer_Name/.../output/logs
O Task Runner deve ser executado separadamente do seu shell de login. Se você estiver usando um aplicativo de terminal para se conectar ao seu computador, precisará de um utilitário, como o nohup, ou uma tela para impedir que a aplicação Task Runner seja encerrada quando você se desconectar. Para obter mais informações sobre as opções de linha de comando, consulte Opções de configuração do Task Runner.
Verificando o registro do Task Runner
A maneira mais fácil de saber se o Task Runner está funcionando é verificar se ele está gravando arquivos de log. De hora em hora, o Task Runner grava arquivos de log no diretório, output/logs, sob o diretório em que ele está instalado. O nome do arquivo é Task Runner.log.YYYY-MM-DD-HH, e HH vai de 00 a 23, em UDT. Para economizar espaço de armazenamento, todos os arquivos de log com mais de oito horas são compactados com GZip.
