As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Visualizar anomalias reativas
Em um insight, você pode visualizar anomalias nos recursos do Amazon RDS. Em uma página de insights reativos, na seção Indicadores agregados, você pode ver uma lista de anomalias com os cronogramas correspondentes. Também há seções que exibem informações sobre grupos de registros e eventos relacionados às anomalias. Cada anomalia causal em uma visualização reativa tem uma página correspondente com detalhes sobre a anomalia.
Visualizar a análise detalhada de uma anomalia reativa do RDS
Nesse estágio, detalhe a anomalia para obter a análise detalhada e as recomendações para suas instâncias de banco de dados do Amazon RDS.
A análise detalhada só está disponível para instâncias de banco de dados Amazon RDS com o Performance Insights ativado.
Para ver os pormenores da página de detalhes da anomalia
-
Na página de insights, encontre uma métrica agregada com o tipo de recurso AWS/RDS.
-
Escolha Exibir detalhes.
A página de detalhes da anomalia é exibida. O título começa com Anomalia de desempenho do banco de dados e nomeia o recurso mostrado. O console usa como padrão a anomalia de maior gravidade, independentemente de quando a anomalia ocorreu.
-
(Opcional) Se vários recursos forem afetados, escolha outro recurso na lista na parte superior da página.
Veja a seguir descrições dos componentes da página de detalhes.
Visão geral do recurso
A seção superior da página de detalhes é Visão geral do recurso. Esta seção resume a anomalia de performance experimentada pela instância de banco de dados do Amazon RDS.
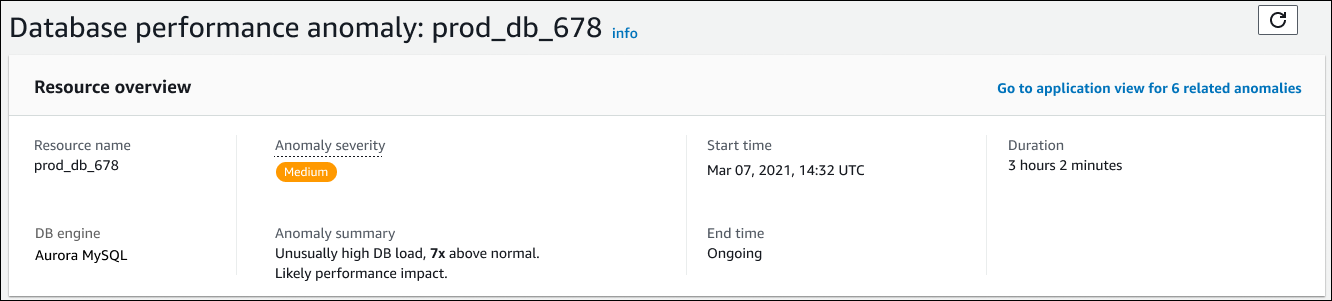
A seção pode incluir os seguintes campos:
-
Nome do recurso: o nome da instância de banco de dados que está enfrentando a anomalia. Neste exemplo, o grupo de recursos é chamado de prod_db_678.
-
Mecanismo do banco de dados — O nome da instância de banco de dados que está enfrentando a anomalia. Neste exemplo, o mecanismo é o Aurora MySQL.
-
Gravidade da anomalia — A medida do impacto negativo da anomalia na sua instância. As gravidades possíveis são Alta, Média e Baixa.
-
Resumo da anomalia — Um breve resumo do problema. Um resumo típico é Carga de banco de dados excepcionalmente alta.
-
Hora de início e hora de término — As horas em que a anomalia começou e terminou. Se o horário de término for contínuo, a anomalia ainda está ocorrendo.
-
Duração — A duração do comportamento anômalo. Neste exemplo, a anomalia está em andamento e está ocorrendo há 3 horas e 2 minutos.
Indicador primário
A seção Indicador primário resume a anomalia casual, que é a anomalia de nível superior dentro do insight. Você pode pensar na anomalia causal como o problema geral enfrentado pela sua instância de banco de dados.
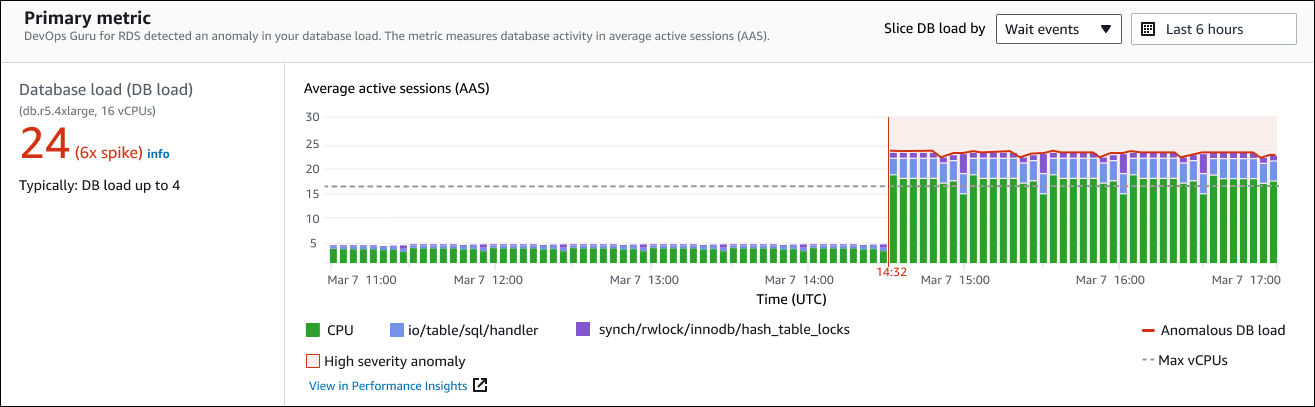
O painel esquerdo fornece mais detalhes sobre o problema. Neste exemplo, o resumo inclui as seguintes informações:
-
Carga do banco de dados — Uma categorização da anomalia como um problema de carga do banco de dados. O indicador correspondente no Performance Insights é
DBLoad. Essa métrica também é publicada na Amazon CloudWatch. -
db.r5.4xlarge: a classe de instância de banco de dados. O número de vCPUs, que é 16 neste exemplo, corresponde à linha pontilhada no gráfico Average active sessions (AAS) (Média de sessões ativas).
-
24 (pico de 6x) — A carga do banco de dados, medida em média de sessões ativas (AAS) durante o intervalo de tempo relatado no insight. Assim, em qualquer momento durante o período da anomalia, uma média de 24 sessões estavam ativas no banco de dados. A carga do banco de dados é 6 vezes a carga normal do banco de dados para essa instância.
-
Normalmente: carga de banco de dados até 4 — A referência da carga de banco de dados, medida em AAS, durante uma carga de trabalho típica. O valor 4 significa que, durante as operações normais, uma média de 4 ou menos sessões estão ativas no banco de dados a qualquer momento.
Por padrão, o gráfico de carga é dividido por eventos de espera. Isso significa que, para cada barra no gráfico, a maior área colorida representa o evento de espera que mais contribui para a carga total do banco de dados. O gráfico mostra a hora (em vermelho) em que o problema começou. Concentre sua atenção nos eventos de espera que ocupam mais espaço no bar:
-
CPU -
IO:wait/io/sql/table/handler
Os eventos de espera anteriores aparecem mais do que o normal para esse banco de dados Aurora MySQL. Para aprender a ajustar a performance usando eventos de espera no Amazon Aurora, consulte Como ajustar eventos de espera para o Aurora MySQL e Como ajustar eventos de espera para o Aurora PostgreSQL no Guia do usuário do Amazon Aurora. Para saber como ajustar o desempenho usando eventos de espera no RDS para PostgreSQL, consulte Como ajustar eventos de espera para RDS para o PostgreSQL no Guia do usuário do Amazon RDS.
Indicadores relacionados
A seção Indicadores relacionados lista as anomalias contextuais, que são descobertas específicas dentro da anomalia causal. Essas descobertas fornecem informações adicionais sobre os problemas de desempenho.
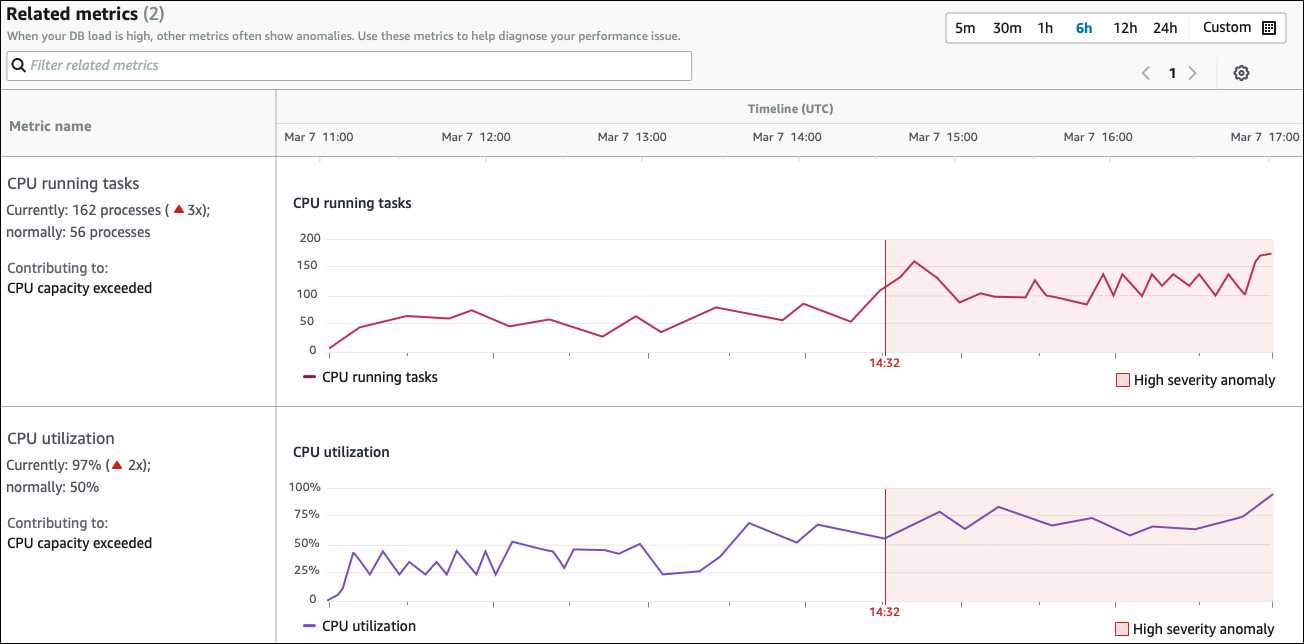
A tabela de Indicadores relacionados tem duas colunas: Nome do indicador e Cronograma (UTC). Cada linha da tabela corresponde a um indicador específico.
A primeira coluna de cada linha tem as seguintes informações:
-
Nome– O nome do indicador A primeira linha identifica o indicador como tarefas de execução da CPU. -
Atualmente — O valor atual do indicador. Na primeira linha, o valor atual é 162 processos (3x).
-
Normalmente — A linha de base dessa métrica para esse banco de dados quando ele está funcionando normalmente. DevOpsO Guru for RDS calcula a linha de base como o valor do 95º percentil em 1 semana de história. A primeira linha indica que 56 processos normalmente estão sendo executados na CPU.
-
Contribuindo para — A descoberta associada a esse indicador. Na primeira linha, o indicador de tarefas em execução da CPU está associada à anomalia de capacidade excedida da CPU.
A coluna Cronograma mostra um gráfico de linhas para o indicador. A área sombreada mostra o intervalo de tempo em que o DevOps Guru for RDS designou a descoberta como alta severidade.
Análise e recomendações
Enquanto a anomalia causal descreve o problema geral, uma anomalia contextual descreve uma descoberta específica que requer investigação. Cada descoberta corresponde a um conjunto de indicadores relacionados.
No exemplo a seguir de uma seção de análise e recomendações, a anomalia de alta carga de banco de dados tem duas descobertas.
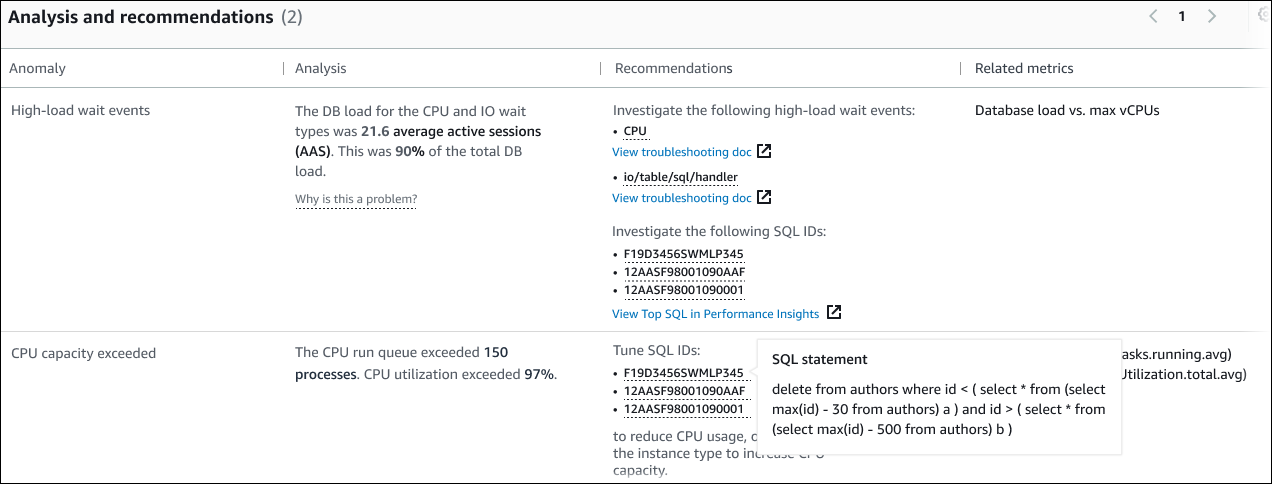
A tabela tem as seguintes colunas:
-
Anomalia — Uma descrição geral dessa anomalia contextual. Neste exemplo, a primeira anomalia são eventos de espera de alta carga, e a segunda é a capacidade da CPU excedida.
-
Análise — Uma explicação detalhada da anomalia.
Na primeira anomalia, três tipos de espera contribuem para 90% da carga do banco de dados. Na segunda anomalia, a fila de execução da CPU excedeu 150, o que significa que, a qualquer momento, mais de 150 sessões estavam aguardando tempo de CPU. A utilização da CPU foi superior a 97%, o que significa que, durante o problema, a CPU estava ocupada 97% do tempo. Assim, a CPU estava quase continuamente ocupada, enquanto uma média de 150 sessões esperavam para serem executadas na CPU.
-
Recomendações — A resposta sugerida do usuário à anomalia.
Na primeira anomalia, o DevOps Guru for RDS recomenda que você investigue os eventos de espera e.
cpuio/table/sql/handlerPara saber como ajustar o desempenho do seu banco de dados com base nesses eventos, consulte cpu e io/table/sql/handler no Guia do usuário do Amazon Aurora.Na segunda anomalia, o DevOps Guru for RDS recomenda que você reduza o consumo de CPU ajustando três instruções SQL. Você pode passar o mouse sobre os links para ver o texto SQL.
-
Indicadores relacionados — Indicadores que fornecem medidas específicas para a anomalia. Para obter mais informações sobre esses indicadores, consulte Referência de indicadores para Amazon Aurora no Guia do usuário do Amazon Aurora ou Referência de indicadores para Amazon RDS no Guia do usuário do AmazonRDS.
Na primeira anomalia, o DevOps Guru for RDS recomenda comparar a carga do banco de dados com a CPU máxima da sua instância. Na segunda anomalia, a recomendação é examinar a fila de execução da CPU, a utilização da CPU e a taxa de execução do SQL.
