As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Clusters elásticos do Amazon DocumentDB: como funcionam
Os tópicos desta seção fornecem informações sobre os mecanismos e funções que alimentam os clusteres elásticos do Amazon DocumentDB.
Tópicos
Fragmentação de clusters elásticos do Amazon DocumentDB
Os clusters elásticos do Amazon DocumentDB usam fragmentação baseada em hash para particionar dados em um sistema de armazenamento distribuído. A fragmentação, também conhecida como particionamento, divide grandes conjuntos de dados em pequenos conjuntos de dados em vários nós, permitindo aumentar a escala horizontalmente do seu banco de dados além dos limites de escala vertical. Os clusters elásticos usam a separação, ou “desacoplamento”, de computação e armazenamento no Amazon DocumentDB, permitindo que você escale independentemente um do outro. Em vez de reparticionar as coleções movendo pequenos pedaços de dados entre os nós de computação, os clusters elásticos copiam os dados de forma eficiente dentro do sistema de armazenamento distribuído.
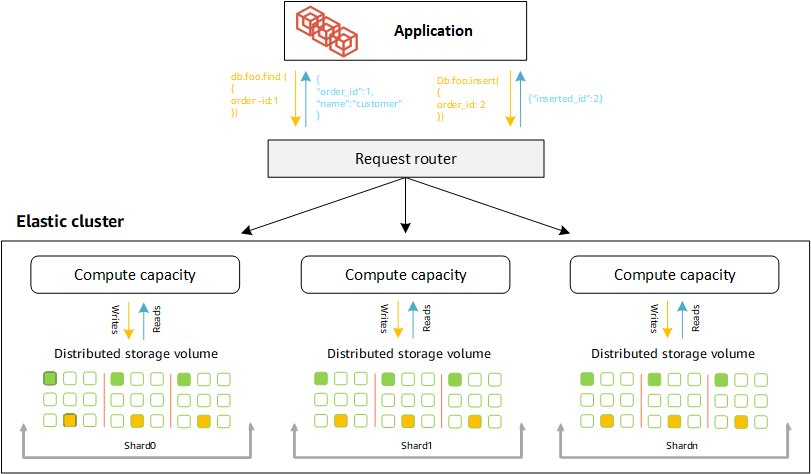
Definições de fragmentos
Definições da nomenclatura de fragmentos:
Fragmento — Um fragmento fornece computação para um cluster elástico. Ele terá uma única instância de gravador e de 0 a 15 réplicas de leitura. Por padrão, um fragmento terá duas instâncias: um gravador e uma única réplica de leitura. É possível configurar no máximo 32 fragmentos e cada instância de fragmento pode ter no máximo 64 vCPUs.
Chave de fragmento — Uma chave de fragmento é um campo obrigatório em seus documentos JSON em coleções fragmentadas que os clusters elásticos usam para distribuir tráfego de leitura e gravação para o fragmento correspondente.
Coleção fragmentada: uma coleção fragmentada é uma coleção cujos dados são distribuídos em um cluster elástico em partições de dados.
Partição — Uma partição é uma parte lógica dos dados fragmentados. Quando você cria uma coleção fragmentada, os dados são organizados em partições dentro de cada fragmento automaticamente com base na chave do fragmento. Cada fragmento tem várias partições.
Distribuir dados entre fragmentos configurados
Crie uma chave de fragmento que tenha muitos valores exclusivos. Uma boa chave de fragmento particionará uniformemente seus dados entre os fragmentos subjacentes, oferecendo à sua workload a melhor throughput e desempenho. O exemplo a seguir são dados de nome de funcionário que usam uma chave de fragmento chamada “user_id”:
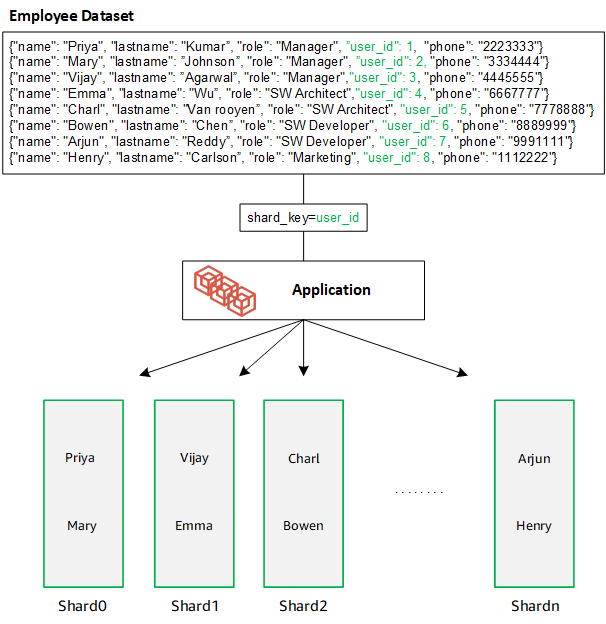
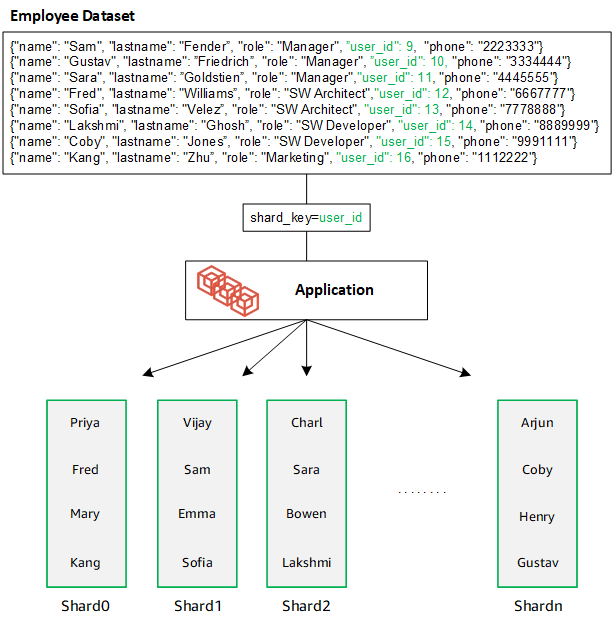
O DocumentDB usa fragmentação de hash para particionar seus dados em fragmentos subjacentes. Dados adicionais são inseridos e distribuídos da mesma forma:
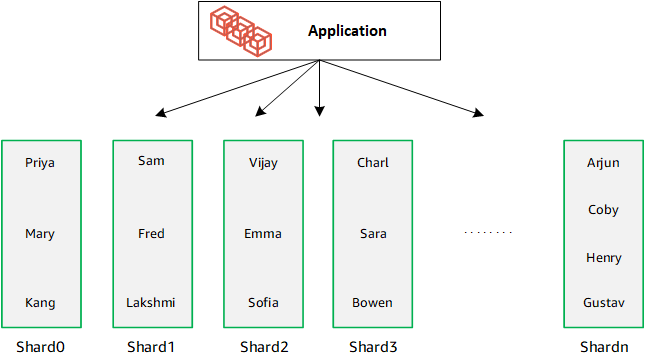
Quando você aumentar a escala de seu banco de dados horizontalmente, adicionando fragmentos, o Amazon DocumentDB redistribui automaticamente os dados:
Migração de clusters elásticos
O Amazon DocumentDB oferece suporte à migração de dados fragmentados do MongoDB para clusters elásticos. Há suporte para métodos de migração offline, online e híbrida. Para obter mais informações, consulte Migrar para o Amazon DocumentDB.
Escalabilidade dos clusters elásticos
Os clusters elásticos do Amazon DocumentDB oferecem a capacidade de aumentar o número de fragmentos (aumentar a escala horizontalmente) em seu cluster elástico e o número de vCPUs aplicados a cada fragmento (aumentar a escala verticalmente). Você também pode reduzir o número de fragmentos e a capacidade computacional (vCPUs) conforme necessário.
Para obter as melhores práticas de escalabilidade, consulte Escalar clusters elásticos.
nota
Cluster-level o dimensionamento também está disponível. Para obter mais informações, consulte Escalar clusters do Amazon DocumentDB.
Confiabilidade dos clusters elásticos
O Amazon DocumentDB foi projetado para ser confiável, durável e tolerante a falhas. Para melhorar a disponibilidade, os clusters elásticos implantam dois nós por fragmento colocados em diferentes zonas de disponibilidade. O Amazon DocumentDB inclui vários recursos automáticos que o tornam uma solução de banco de dados confiável. Para obter mais informações, consulte Confiabilidade do Amazon DocumentDB.
Armazenamento e disponibilidade de clusters elásticos
Os dados do Amazon DocumentDB são armazenados em um volume de cluster, que é um único volume virtual único que usa unidades de estado sólido (SSDs). Um volume de cluster consiste em seis cópias de seus dados, que são replicadas automaticamente em várias zonas de disponibilidade em uma única AWS região. Essa replicação ajuda a garantir que seus dados sejam resilientes, com menor possibilidade de perda de dados. Isso também ajuda a garantir que o cluster esteja mais disponível durante um failover, pois as cópias dos dados já existem em outras zonas de disponibilidade. Para obter mais detalhes sobre armazenamento, alta disponibilidade e replicação, consulte Amazon DocumentDB: como funciona.
Diferenças funcionais entre o Amazon DocumentDB 4.0 e clusters elásticos
As seguintes diferenças funcionais existem entre o Amazon DocumentDB 4.0 e os clusters elásticos.
Os resultados de
topecollStatssão particionados por fragmentos. Para coleções fragmentadas, os dados são distribuídos entre várias partições ecollStatsinformacollScansagregados a partir das partições.As estatísticas de
topecollStatspara coleções fragmentadas são redefinidas quando a contagem de fragmentos do cluster é alterada.A função integrada de backup agora é compatível com
serverStatus. Ação: desenvolvedores e aplicações com função de backup podem coletar estatísticas sobre o estado do cluster Amazon DocumentDB.O campo
SecondaryDelaySecssubstituislaveDelayna saídareplSetGetConfig.O comando
hellosubstituiisMaster-helloretorna um documento que descreve a função do cluster elástico.O operador
$elemMatchem clusters elásticos só corresponde aos documentos no primeiro nível de aninhamento de uma matriz. No Amazon DocumentDB 4.0, o operador percorre todos os níveis antes de devolver os documentos correspondentes. Por exemplo:
db.foo.insert( [ {a: {b: 5}}, {a: {b: [5]}}, {a: {b: [3, 7]}}, {a: [{b: 5}]}, {a: [{b: 3}, {b: 7}]}, {a: [{b: [5]}]}, {a: [{b: [3, 7]}]}, {a: [[{b: 5}]]}, {a: [[{b: 3}, {b: 7}]]}, {a: [[{b: [5]}]]}, {a: [[{b: [3, 7]}]]} ]); // Elastic clusters > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } // Docdb 4.0: traverse more than one level deep > db.foo.find({a: {$elemMatch: {b: {$elemMatch: {$lt: 6, $gt: 4}}}}}, {_id: 0}) { "a" : [ { "b" : [ 5 ] } ] } { "a" : [ [ { "b" : [ 5 ] } ] ] }
A projeção “$” no Amazon DocumentDB 4.0 retorna todos os documentos com todos os campos. Com clusters elásticos, o comando
findcom uma projeção “$” retorna documentos que correspondem ao parâmetro de consulta contendo somente o campo que corresponde à projeção “$”.Em clusters elásticos, os comandos
findcom parâmetros de consulta$regexe$optionsretornam um erro: “Não é possível definir opções em $regex e $options”.
Com clusters elásticos,
$indexOfCPagora retorna “-1" quando:a substring não foi encontrada no
string expression, oustarté um número maior queend, oustarté um número maior que o comprimento do byte da string.
No Amazon DocumentDB 4.0,
$indexOfCPretorna “0" quando a posiçãostarté um número maior queendou o comprimento do byte da string.Com clusters elásticos, as operações de projeção em
_id fields, por exemplo,{"_id.nestedField" : 1}, retornam documentos que incluem apenas o campo projetado. Já no Amazon DocumentDB 4.0, os comandos de projeção de campo aninhados não filtram nenhum documento.
